源自:电子与信息学报
作者:孙磊, 杨宇, 毛秀青, 汪小芹, 李佳欣
摘 要
传统的生成对抗网络(GAN)在特征图较大的情况下,忽略了原始特征的表示和结构信息,并且生成图像的像素之间缺乏远距离相关性,从而导致生成的图像质量较低。为了进一步提高生成图像的质量,该文提出一种基于空间特征的生成对抗网络数据生成方法(SF-GAN)。该方法首先将空间金字塔网络加入生成器和判别器,来更好地捕捉图像的边缘等重要的描述信息;然后将生成器和判别器进行特征加强,来建模像素之间的远距离相关性。使用CelebA,SVHN,CIFAR-10等小规模数据集进行实验,通过定性和盗梦空间得分(IS)、弗雷歇距离(FID)定量评估证明了所提方法相比梯度惩罚生成对抗网络(WGAN-GP)、自注意力生成对抗网络(SAGAN)能使生成的图像具有更高的质量。并且通过实验证明了该方法生成的数据能够进一步提升分类模型的训练效果。
关键词
生成对抗网络 / 空间金字塔网络 / 特征加强 / 特征图
1. 引 言
随着人工智能技术的不断发展,越来越多的下游任务相继涌现,例如分类[1]、人脸识别[2]、目标检测[3,4]等,而这些任务大都依赖大量的数据,包括图像、语音、文本等数据。但是在现实世界中,对于医疗、安全、航空、脑电等特殊领域数据获取较为困难,成本极高。数据量的匮乏会对模型的训练产生极大的负面影响,因此,需要通过数据生成技术生成较为接近真实数据的虚假数据,从而提升模型的训练效果。在计算机视觉领域,图像生成技术一直以来都是研究的热点问题。传统的生成模型有受限玻尔兹曼机(Restricted Boltzmann Machines, RBM)[5]、深度信念网络(Deep Belief Network, DBN)[6]、变分自编码器(Auto-Encoding Variational, AEV)[7]等,此类方法计算复杂且生成效果有限。
2014年Goodfellow等人[8]提出了基于博弈论的生成模型,即生成对抗网络(Generative Adversarial Network, GAN),它使用生成器和判别器进行对抗训练,通过反向传播更新网络的权值,易于计算且效果显著,极大推动了图像生成领域的发展,但是训练过程极不稳定。卷积神经网络(Convolutional Neural Network, CNN)[9]已经广泛应用于深度学习领域,经典的深度卷积生成对抗网络(Deep Convolution Generative Adversarial Networks, DCGAN)[10]将传统GAN的多层感知机替换为CNN,将CNN引入生成器和判别器,该模型进一步提升了GAN的学习能力,提高了生成图像的质量,但是存在着训练不稳定,易产生模式坍塌的现象。2017年由Arjovsky等人[11]提出的瓦瑟施泰因生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)用Wasserstein距离取代詹森-香农(Jensen-Shannon divergence, JS)[12]距离,这样能更好地衡量两个分布之间的散度,在一定程度上缓解了GAN训练不稳定的问题,但是此算法并没有让判别器真的限制在1-利普希茨函数(1-Lipschitz function)[13]内,并没有严格给出Wasserstein距离的计算方法。由Gulrajani等人[14]提出的梯度惩罚生成对抗网络(improved training of Wasserstein GANs, WGAN-GP)属于WGAN的增强版,用梯度惩罚实现了对判别器的近似1-利普希茨函数限制,使得GAN训练更加稳定,收敛更快,同时能够生成更高质量的样本,但是它只对于梯度的模大于1的区域的x作出了惩罚,并没有从根本上解决判别器的1-利普希茨函数限制问题。Zhang等人[15]提出了将注意力机制与GAN融合的自注意力生成对抗网络(Self-Attention GAN, SAGAN),该改进模型可以很好地处理长范围、多层次的依赖,生成更精细、更协调的图像,但是依然存在建模像素之间远距离相关性能力弱的问题。文献[16]提出一种空间金字塔注意力网络以探索注意力模块在图像识别中的作用,它通过横向添加空间金字塔模块方式增强基础网络的性能。丁斌等人[17]提出了一种基于深度生成对抗网络的海杂波数据增强方法,通过改进传统的GAN框架来训练生成器和判别器。曹志义等人[18]提出了一种改进的GAN模型来进行人脸还原算法,但是缺点是需要基于大量的训练样本。
虽然如今已经衍生出了各种GAN的模型,但是依然存在生成的图像不清晰、质量不高等问题。而且一些GAN模型大都需要基于大量的训练样本,而在一些特殊领域,数据集的获取较为保密和艰难,所以如何在小样本的基础上,生成质量更高的图片是本文的研究重点。本文的主要贡献有:
-
(1) 提出一种基于空间特征的生成对抗网络数据生成方法,在小样本的基础上进行图像数据的生成,在生成更高质量图像的同时不会引入较大的时间开销。
-
(2) 将梯度惩罚损失函数引入对抗训练,使得训练过程更加稳定,更能快速收敛。
-
(3) 在CelebA, SVHN以及CIFAR-10数据集上进行大量对比实验,并且使用经典盗梦空间得分(Inception Score, IS)、弗雷歇距离(Frechet Inception Distance, FID)定量评估验证了所提方法的有效性。并且设计了分类实验进一步验证了本文生成的图像数据能够提升已有深度模型的训练效果。
2. 相关工作
2.1 生成对抗网络
GAN由生成器和判别器组成,生成器试图捕捉学习数据集中的真实分布,判别器在与生成器的不断对抗中提升判别图像真伪的能力,两者是一个不断博弈对抗的过程。GAN示意图如图1所示。
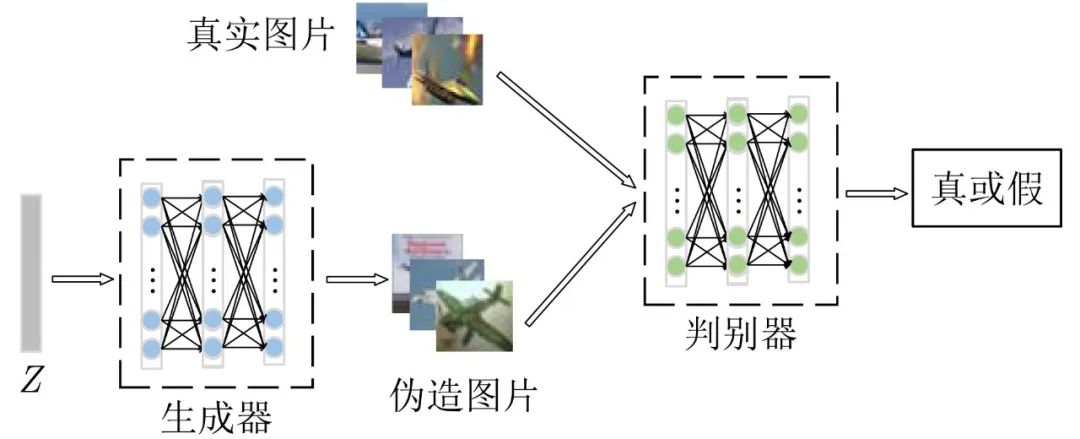
图 1 GAN结构示意图
图1为GAN的基本结构示意图,其中生成器记为G,判别器记为D,G的输入为来自隐空间的随机变量Z,输出生成的样本,其训练目标是提高生成样本与真实样本的相似度,使其无法被D所判别。D的输入为真实样本和生成样本,最后输出判别结果为真或假,其训练目标是分辨真实样本与生成样本。原始GAN的目标函数为
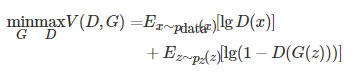
(1)
其中,pdata(x) 代表真实样本的分布,pz(z) 代表生成样本的分布,D(x) 是真实图像的概率,是一个0~1的实数。训练目标为最小化pz(z) 与pdata(x) 之间的距离,最大化D 判别样本的准确率。由式(1)可知训练判别器的过程中期望最大化目标函数使D(x) 输出的概率趋近于1,使D(G(z)) 输出概率值趋近于0;当对生成器进行训练时期望最小化目标函数,即D(G(z)) )输出概率趋近于1,使生成器生成的图像无法被判别器判别真伪。当对抗训练进行到最后时理想情况下判别器对生成图像以及真实图像的输出概率值都接近于0.5,此时判别器将无法判断生成器所生成图像的真伪,生成器将可以很好地拟合数据集的真实分布,生成以假乱真的图像。
2.2 深度卷积生成对抗网络
DCGAN将CNN引入生成器和判别器,借助CNN更强的拟合与表达能力,很大程度上提高了生成图像的能力,其思路主要使用了原始GAN模型的基础理论。DCGAN相比于原始的GAN改进包含以下几个方面:
-
(1) 取消了所有的池化层,生成器中使用转置卷积[19]进行上采样;
-
(2) 除了生成器的输出层和判别器的输入层之外,在网络其他层上都使用了批量归一化(Batch Normalization, BN)[20];
-
(3) 生成器中除了最后一层均使用整流型线性单元(Rectified Linear Unit, ReLU)[21]作为激活函数,最后一层使用双曲正切(hyperbolic Tangent, Tanh)[22]激活函数;判别器中除了最后一层均使用渗漏整流型线性单元(Leaky ReLU)[23]作为激活函数,最后一层使用Sigmoid激活函数。
DCGAN在图像生成方面被广泛应用,它在很大程度上提升了GAN的训练稳定性和生成结果的质量,但是它只是改进了GAN的结构,并没有从根本上解决GAN训练稳定性的问题,在训练过程中仍然需要平衡生成器和判别器的训练次数。
如图2所示为DCGAN生成器示意图,生成器接收一个表示为Z的100×1的噪声矢量,通过一系列转置卷积操作,最终将噪声映射到64×64×3的图像中。

图 2 DCGAN生成器结构示意图
3. 基于空间特征的生成对抗网络
本文提出的SF-GAN使得网络在训练过程中能够迅速定位图像的重点生成区域,抑制噪声对模型训练的干扰,提升网络模型的训练效率,增强网络模型的性能,然后使用梯度惩罚损失函数来稳定训练过程,从而提升生成图像的清晰度和精细度。如图3为SF-GAN的模型框架图。
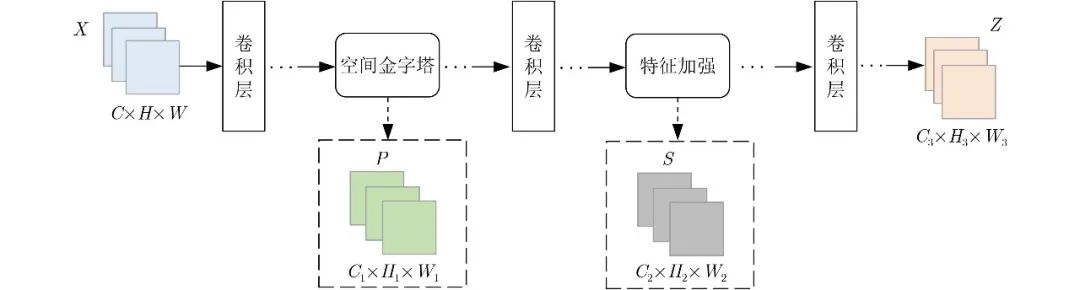
图 3 SF-GAN的模型框架
如图3所示,X为初始特征图,X∈RC×H×W,Z为输出特征图,
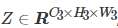
,其中P代表空间金字塔的输出特征图,S代表特征加强后的输出特征图,图3中激活函数、归一化层、其他层等均用省略号代替。初始特征图经过一系列卷积、归一化等操作后,通过空间金字塔模块,得到特征图P,将P接着进行一系列卷积等操作,然后进行特征加强,得到特征图S,最后将特征加强后的特征图S继续进行卷积等操作输出最后的结果Z。
在生成器和判别器中加入两个模块,从简单的特征依赖开始,逐渐学习到复杂的依赖关系。如图4所示为SF-GAN的网络训练流程图,SM代表空间金字塔模块,FM代表特征加强模块,通过生成器和判别器不断循环交替的训练,反向传播更新参数,生成器生成越来越逼真的图像。

图 4 SF-GAN的网络训练流程图
3.1 空间金字塔
已有的通道注意力网络仅考虑通道方面的依赖性而忽视了结构信息,结构信息中体现的是图像的整体框架,包含图像的边缘等重要的描述信息。为增强CNN的特征表达能力,传统的深度残差网络(deep Residual learning for image recognition, ResNet)[24]引入了更多的参数和更大的时间开销。将金字塔网络加入到生成器和判别器中,用更少的网络层获得更好的性能。如图5所示为空间金字塔结构示意图。

图 5 空间金字塔结构
基于注意力的CNN对每个特征图应用全局平均池化。全局平均池化的行为类似于一个结构正则化器,并且能够防止过拟合。然而,将全局平均池化应用于每个特征图过于强调正则化的效果,而忽略了原始特征的表示和结构信息,尤其是在特征图较大的情况下。例如,将一个112×112的特征映射聚合到一个平均值会导致特征表示能力的严重损失,从而影响特征学习。空间金字塔结构包括3种不同大小的自适应平均池化,将结构正规化和结构信息整合到注意路径中,多层感知机从空间金字塔结构的输出中学习权重特征图。
自适应和平均地将输入特征映射到3个比例尺:4×4, 2×2和1×1。4×4平均池化是为了获取更多的特征表示和结构信息;1×1平均池化是具有较强结构正则化的传统全局平均池化;2×2平均池化目标是在结构信息和结构正规化之间进行权衡。将这3个输出reshape为3个1维向量,并通过连接将它们组合在一起生成1维特征向量。空间金字塔结构既能保留特征表示,又能继承全局平均池化的优点。
假设CNN包含L层,xl表示第l∈[1,L]层的输出,P(⋅,⋅)表示自适应平均池化,Ffc(⋅)表示全连接层,C(⋅)表示连接操作,σ(⋅)表示sigmoid激活函数,R(⋅)表示Resize函数,xl∈RC×W×H为中间特征映射,则空间金字塔结构输出公式为

(2)
接着经过一个多层感知机后输出为

(3)
从空间金字塔结构中提取的1维注意图V是由3个池化层的输出拼接而成的,然而,它不能用于学习通道依赖,其非线性表达影响了注意力机制的有效性。为了解决这个问题,利用激励块对V 进行非线性建模,并生成1维注意力图,然后使用一个sigmoid激活函数将输出归一化到(0,1)范围。公式为

(4)
其中,
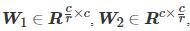
, W1 和W2 是两个全连接层的权值矩阵。
3.2 特征加强
由于卷积核大小的限制,GAN的生成器只能捕捉局部区域的关系。针对原始GAN生成的图像几何特征不明显,局部区域细节不丰富的问题,将特征加强同时应用于生成器和判别器,加强生成图像的整体几何特征,加强领域特征与远距离特征之间的关联度。
将前一个隐含层x∈RC×N 的图像特征转化为两个特征空间函数f,g ,其中C 是通道的数量,N 是宽度乘以高度。f(x) , g(x) , h(x) 都是1×1 的卷积,通常一个卷积过程包括一个激活函数,所以在输入不发生尺寸的变化下引入了更多的非线性,增强了神经网络的表达能力。
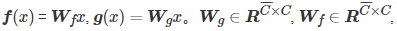
, 是学习的权重矩阵
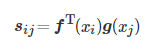
(5)
如式(5)所示,将f(xi) 的输出转置并和g(xj) 的输出相乘,再经softmax归一化得到一个特征图。如式(6)所示

(6)
其中,βj,i 表示在合成第j个区域时模型对第i个位置的影响程度,本质上是量化图像中像素j相对于i的重要性。将得到的特征图和h(xi) 逐像素点相乘,得到特征加强的特征图oj ,其中xi为第i个被提取的图像特征图。如式(7)所示

(7)
另外,进一步将输出o乘以比例参数γ并添加回输入要素图x,最终输出由式(8)给出
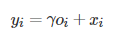
(8)
为了兼顾领域信息和远距离特征相关性,引入一个过渡参数γ,初始值为0,使得模型从领域信息学起,逐渐将权重分配到别的远距离特征细节上,从而实现了特征加强。
4. 实验过程及分析
4.1 实验环境及数据集
为了验证本文方法的有效性,在CelebA, SVHN和CIFAR-10数据集上进行实验,运行环境为PyTorch开源框架,操作系统为Windows10 64位,处理器为Intel(R)Core(TM)i7-10700K [email protected] GHz,显卡型号为NVIDIA GeForce RTX 2080 SUPER,显存为8 GB。CelebA数据集是由香港中文大学Liu等人[25]所收集整理并公开的,该数据集包含10177名公众人员的202599张人脸图像,每张图片的大小为178×218,且人脸图像包含了多个视角及背景,同时该数据集对人脸的性别、表情、发色等特征都做了标记;街景门牌数字(Street View House Number, SVHN)数据集来源于谷歌的真实世界街景门牌的数字号码,共100000张32×32的彩色图像,包括0~9 10个类别,其中训练集样本73257张,训练集样本26032张;CIFAR-10数据集是由Krizhevsky[26]收集并整理,该数据集包含汽车、青蛙、马以及船等10个类别的彩色图像,训练集中每个类别由5000张图像组成,总共50000张,测试集每个类别有1000张图像,总共10000张,图像大小均为32像素×32像素。
4.2 评价指标
IS是由Salimans等人[27]提出的评价生成图像语义的初始得分算法,其起源于Google的Inception Nets,该图像评价指标能够衡量单张生成图像的清晰度以及生成图像的多样性。Inception Score在评价生成图像清晰度时,将生成的图像样本x输入到Inception Nets中,输出1000维的y向量,在y向量中每个维度代表输入图像样本x属于某一类别的概率,如果输入图像样本x清晰度很高,那么输入图像样本x属于某一类别的概率很高,属于其他类别的概率则会很低。IS值越高意味着生成对抗网络的生成图像样本清晰度越高、丰富性越好,生成图像样本质量越高。
FID[28]是真实图像与生成图像的特征向量间距离的一种度量。这里的特征向量是由Inception v3 Network得到的,网络结构的最后两层为全连接层,以得到1×1×1000分类向量,FID采用的是倒数第2个全连接层的输出1×1×2048维图像特征向量用于距离度量。它可以更好地捕捉生成图像与真实图像的相似性,符合人类的区分准则,FID值越低意味着生成的图像有更好的图像质量和多样性。
4.3 实验设计
为了验证本文所提方法的有效性,在CelebA, CIFAR-10, SVHN数据集上进行实验对比。对于CelebA数据集,生成的图片的大小为64×64;对于CIFAR-10和SVHNN数据集,生成的图片的大小为32×32,从原始数据集每个类别中随机抽取500张图像,总数为5000张图像,因为是无监督生成,所以把每个类的500张分别放到模型中进行生成。所有对比模型的数据集的种类和数量都相同,batch size设置为64,生成器的迭代次数total step都各自设置为200000次,在训练过程中每迭代100次保存一次生成的样本和预训练的权重。该实验中使用Adam[29]优化器,其中β1=0.0, β2=0.9,学习率衰减设置为0.95,使用双时间尺度的更新规则(Two Time-scale Update Rule, TTUR),生成器的学习率设置为0.0001,判别器的学习率设置为0.0004,这样一来,使生成器和判别器有不同的学习率,生成器使用更小的更新幅度来欺骗判别器,并且不会选择快速、不精确和不现实的方式来赢得博弈。学习率衰减设置为0.95。对抗训练损失函数使用梯度惩罚函数,此损失函数能够稳定GAN的训练,更容易收敛。训练时采取判别器训练5次,生成器训练一次的方法,其中梯度惩罚系数λ=10。
为了进一步验证本文生成的图像数据能够提升已有深度模型的训练效果,使用分类实验进行验证。在小规模数据集分类实验中,为了排除分类器性能的影响仅考虑生成数据的效果,基于经典的LeNet设计一个分类网络。对于SVHN和CIFAR-10数据集来说,从每个类别中随机抽取500张图像,10个类共5000张。每个类在扩充前的训练集:测试集=350:150,扩充前总的训练集为3500张,总的测试集为1500张。将原始进行分类的每个类的训练集扩充10倍后为3500张,总的训练集为35000张,总的测试集依然为1500张。对比使用真实图片、不同GAN方法生成数据扩充前后在测试集上的准确率,准确率越高说明生成的图像质量越好,能有效提高分类模型的性能。
4.4 实验结果分析
本文所选的基线模型为DCGAN,为了验证MA-GAN数据增强的有效性,与WGAN-GP和同样使用注意力机制的SAGAN通过定性和定量进行比较,这几个模型的共同特点是都是以DCGAN为基线方法,结构简单,参数量相对较少,仅占用较小的GPU内存,更能验证所提方法的有效性。
4.4.1 CelebA实验结果
如图6所示为各个模型迭代200次时生成的图片效果,对于CelebA数据集来说,当生成器迭代200次时WGAN-GP, SAGAN和SF-GAN都大致有了人脸的轮廓,但是WGAN-GP, SAGAN中存在的黑色的斑块较多且呈现不规则状态,SF-GAN相比之下伪影存在规则状态。

图 6 不同模型生成样本对比
由图7可知,WGAN-GP生成的图像存在人脸模式崩溃的现象(如图7(a)中红色方框所示),SAGAN生成的人脸图像出现较多的异常结构图像(如图7(b)中红色方框所示),原因是SAGAN虽然通过自注意力机制捕获了单张特征图上的像素相关性,但无法捕捉各特征通道之间的联系,故未能成功捕获图像的几何特征和结构。SF-GAN相对于SAGAN, WGAN-GP生成的图片更加平滑自然,人脸器官较为协调。

图 7 不同模型在CelebA数据集上的生成效果
表1中指标IS的“↑”符号表示IS越大模型效果越好,指标FID的“↓”符号表示FID越小模型效果越好。由表1可知,SF-GAN相对于SAGAN,IS分数提升了10.28%,FID降低了1.18%;相对于WGAN-GP,IS分数提升了12.75%,FID降低了14.93%。表明了所提方法的有效性以及在生成图像上的优良性能。

表 1 在CelebA数据集上不同模型的对比结果
4.4.2 SVHN实验结果
如图8所示为不同模型在类“8”上的生成效果,WGAN-GP和SAGAN都存在无法正常生成图像样本的情况(如图8(a)和图8(b)中红色方框所示)SF-GAN生成的数字较为清晰、边缘干净、色彩也更为明亮,细节展现较为自然。

图 8 不同模型在数字8上的生成效果
由表2可知,在数字0~9这10个类中,SF-GAN生成图像的各个类的IS分数都是最高的。在类“5”中,SF-GAN相对于WGAN-GP, SAGAN模型IS分数分别提升了11.81%, 12.43%;其中在类“7”中,SF-GAN相对于WGAN-GP模型IS分数提升了20.35%,相比SAGAN提升了13.95%。

表 2 在SVHN数据集上不同模型的IS对比结果
由表3可知,在数字0~9这10个类中,SF-GAN生成图像的各个类的FID分数都是最低的,即代表模型的性能最好。其中在类“8”中,SF-GAN相对于WGAN-GP, SAGAN模型FID分数分别降低了27.63%, 27.511%;在类“9”中,SF-GAN相对于WGAN-GP, SAGAN模型FID分数分别降低了35.55%, 23.10%。

表 3 在SVHN数据集上不同模型的FID对比结果
4.4.3 CIFAR-10实验结果
如图9所示为不同模型在CIFAR-10上的生成效果,由图9(a)可知WGAN-GP生成的图像效果较为混乱,物体与背景区分度较低;由图9(b)可知SAGAN生成的图像色彩的视觉效果表达上优于WGAN-GP,具有较好的明暗层次,但在物体的特征表现上仍有欠缺;图9(c)为SF-GAN的生成图像,相比其他模型,其生成的图像具有较好的色彩表现力,物体的特征区分度较好,图像主体与背景的过渡更加自然,细节展现较多,进一步说明SF-GAN对于深层特征的提取能力较强,生成的图像质量也较好。

图 9 不同模型在CIFAR-10上的生成效果
由表4可知,在CIFAR-10的10个类中SF-GAN的IS都是最高的。其中在类“飞机”中,SF-GAN相对于WGAN-GP, SAGAN模型IS分数分别提升了9.42%, 8.89%;在类“狗”中,SF-GAN相对于WGAN-GP, SAGAN模型IS分数分别提升了24.51%, 18.54%。

表 4 在CIFAR-10数据集上不同模型的IS对比结果
由表5可知,在类“飞机”、“鸟”、“猫”、“鹿”、“狗”、“蛙”、“马”、“轮船”、“卡车”等9个类中SF-GAN相较于其他对比模型FID都是最低的。在类“汽车”中,SF-GAN模型的FID低于SAGAN,高于WGAN-GP。其中在类“鸟”中,SF-GAN相对于WGAN-GP, SAGAN模型FID分数分别降低了21.92%, 17.63%;在类“轮船”中,SF-GAN相对于WGAN-GP, SAGAN模型FID分数分别降低了9.33%, 23.29%。

表 5 在CIFAR-10数据集上不同模型的FID对比结果
4.4.4 分类识别性能分析
由图10可知,在进行2000次迭代步长时,除了真实图片增强,3种不同GAN方法增强后训练集损失趋近于0。真实图片增强后训练损失没有GAN数据增强方法损失下降快。
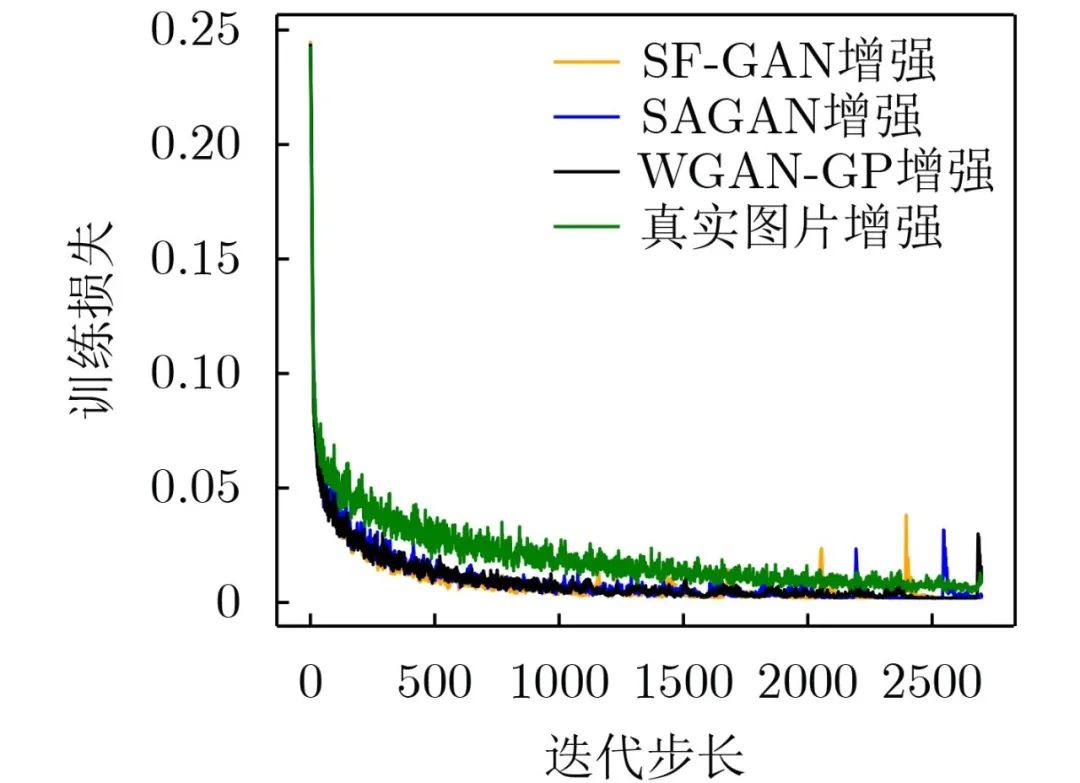
图 10 SVHN增强后训练集损失的变化
由图11(a)可知,对于训练集中每个类的分类准确率来说,WGAN-GP增强后每个类的分类准确率波动最大,其次波动较大的是真实图片增强;使用SF-GAN增强的每个类的分类准确率相当。由图11(b)可知对于测试集中每个类的分类准确率来说,使用SF-GAN增强后每个类的分类准确率波动最小并且准确率也较高。
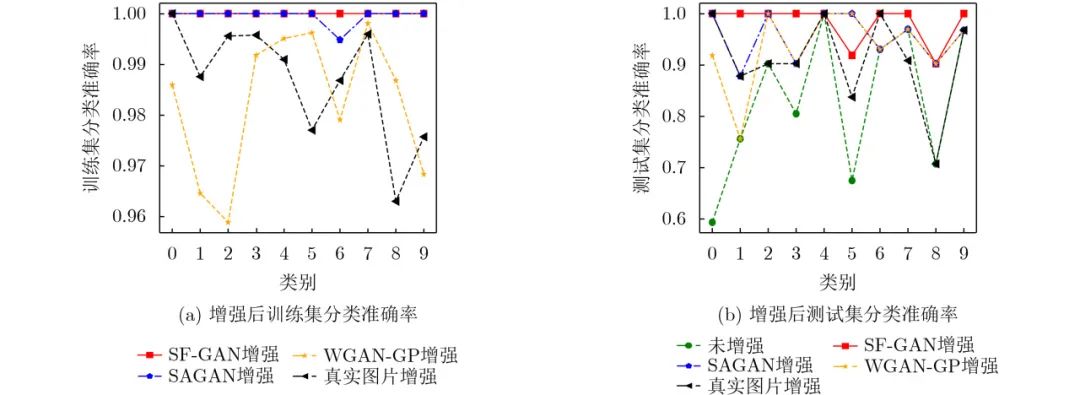
图 11 SVHN增强后训练集和测试集分类准确率
由图12可知,SF-GAN增强和MA-GAN增强损失下降最快并且在进行2500次迭代步长时,两种方法增强后的训练损失趋近于0,说明训练过程更加稳定,收敛更快。
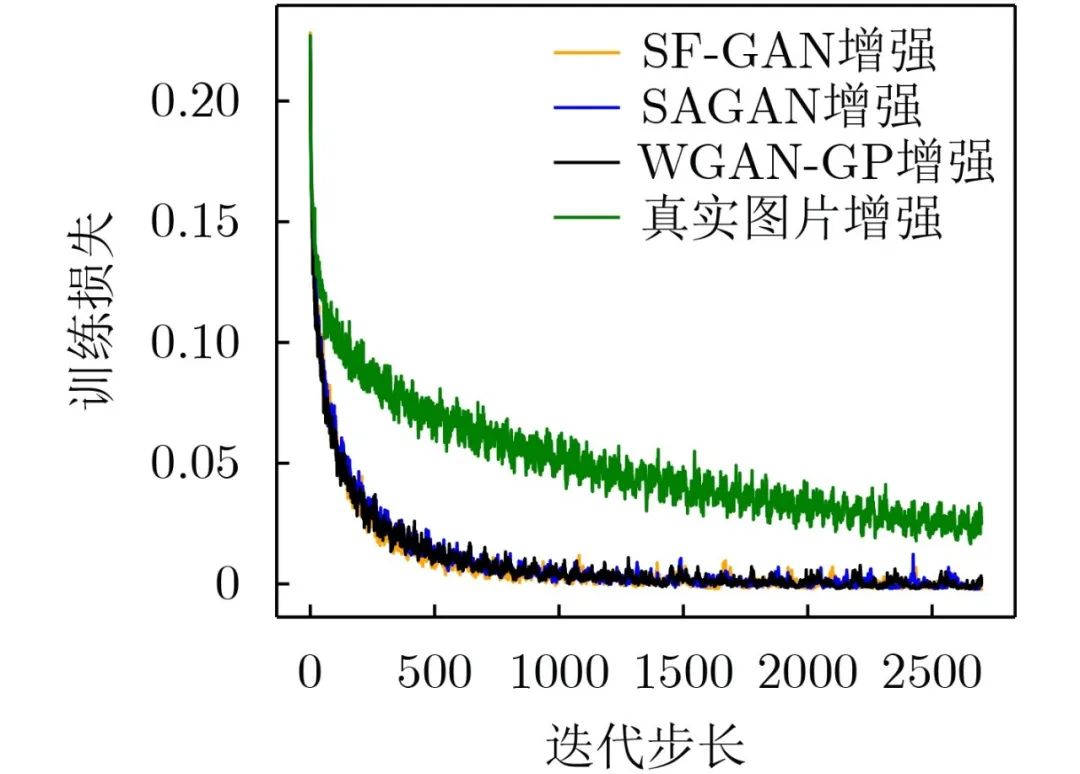
图 12 CIFAR-10增强后训练集损失的变化
由图13(a)可知,对于训练集中每个类的分类准确率来说,使用真实图片增强较其他方法增强波动大,使用WGAN-GP增强较其他GAN方法增强波动大,而使用SF-GAN增强后波动最小;由图13(b)可知,对于测试集中每个类的分类准确率来说,使用SF-GAN增强后每个类的分类准确率较高且波动较小。

图 13 CIFAR-10增强后训练集和测试集分类准确率
由表6可知,SF-GAN增强后,测试集上的平均准确率最高,相比未增强时的准确率提升了12.16%,相比WGAN-GP方法增强的准确率提升了6.41%。
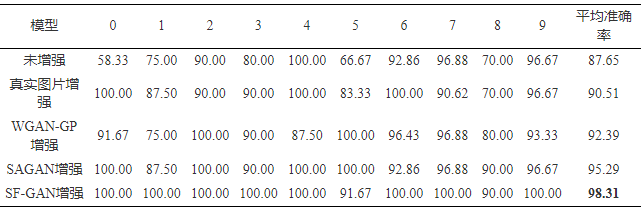
表 6 不同方法增强后SVHN测试集的分类准确率(%)
由表7可知,SF-GAN相比真实图片,SAGAN, WGAN-GP增强后,平均准确率都是最高的,相比未增强时的准确率提升了64.53%,相比WGAN-GP方法增强后的准确率提升了12.31%。所提方法一定程度上提高了生成图像的质量和逼真度以及加快了网络收敛速度,在分类器上的准确率优于其他对比方法,证明了本文生成的图像数据能够进一步提升深度模型的性能。

表 7 不同方法增强后CIFAR-10测试集的分类准确率(%)
5. 结束语
针对GAN在特征图较大的情况下忽略原始特征的表示和结构信息从而导致生成图像质量低的问题,本文提出一种基于空间特征的生成对抗网络数据生成方法(SF-GAN)。所提方法在CelebA, SVHN, CIFAR-10等数据集上有较好的生成效果,在标准IS, FID度量指标验证了SF-GAN的性能优于WGAN-GP, SAGAN等经典方法,并且通过分类实验进一步验证了本文生成的图像数据能够提升已有深度模型的训练效果,表明本文提出的方法比其他方法能够更全面地获取图像中的特征信息,生成的图像结构分布也与真实分布更为接近。在未来的工作中,将致力于用更少的数据集生成更高分辨率的图像。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询” 发布