
01
背景解读
在90年代提出的Log-Structured File System(LFS)思想和NAND Flash简直是天生一对。当初设计Log-Structured File System最主要的想法是利用机械磁盘出色的顺序写性能,避免糟糕的随机写问题。Log-Structured File System在机械硬盘的时代有一定的应用局限性,问题在于采用log数据布局的方式之后,顺序读性能变得很差。因此,只有在大块数据读写的环境下,Log-Structured File System才变得合情合理。
在NAND Flash介质上,不存在机械硬盘随机读写的问题,因此,Log-Structured的数据布局方式不会引入任何性能问题,反而能够解决NAND Flash的“写时擦除”带来的寿命、磨损均衡等问题。
02
存在的问题

03
方案选型

写入前先记日志,可以是redo日志,记录需要写入的数据,也可以是undo日志,记录写入前的数据,再写入。写入完成删除日志。如果中断就进行undo或者redo,保证各副本数据一致。Ceph中未对齐IO以RMW方式更新就是使用undo日志,将旧数据记录在数据库中,FASS中logctl是使用redo方式,将需要写入的数据记录在LOG中。缺点是需要两次写入,写放大严重。

Ceph中BlueStore使用这种方式实现,当数据发生覆盖写时,不再直接更新磁盘对应位置的已有内容,而是分配一块新空间,存放本次新写入的内容。当新写完成后,释放原有空间。因此可以解决RMW多读一次的问题和覆盖写的问题。ROW可以把随机写转换为顺序写,能提高一定写性能。但是ROW原有块仍保留部分有效内容,后续范围内操作都需要多次读,还是会影响读性能。FASS如果也使用此种方式,就需要将chunk空间管理粒度变为4K,将元数据保存位置变成一个数据列表。

Log-Structured将整个磁盘空间作为一个日志卷,以日志卷的形式写入,可以减少一次写入,缺点是实现复杂,也会破坏数据原本的连续性。

不支持rewrite就必须整条带写。不满整条带的也需要占用一个条带,小IO随机写空间浪费严重。例如:一个4k数据,条带16K,正条带写浪费75%的空间。如果把小文件聚合后大块顺序写,则基本不会出现空间浪费。
04
分析
由上分析,如果提升EC随机写入性能,同时兼顾磁盘写入寿命,压缩去重的支持,Log-Structured将是FASS目前唯一可选方案。
Log-Structured为我们提供了日志卷的设计思路,将写入的IO以日志的形式追加到末尾,随机IO顺序化,然后再进行大块顺序整条带写。在FASS项目中引入日志结构化存储,提供日志结构化存储卷,减少写放大,提升随机写IO性能和延长磁盘寿命。
05
基于Log-Structured的设计
FASS 2.0分布式全闪块存储系统的实现基于Log- Structured。它将类HDD的映射方式改为类SSD的映射方式,相当于在系统内实现了一个分布式的SSD控制器。
由于range大小固定,方便空间管理,所以当前版本在range层实现Log- Structured。它主要由WAL、data log组成。
WAL(Write Ahead Log)预写日志用于保证数据操作的原子性和持久性。把随机小块写IO聚合成大块顺序(append)写操作。data log是落盘数据,由于新数据采用追加写,旧的数据被留在原位,会涉及到旧数据的垃圾回收(Garbage Collection,以下简称GC)。

WAL采用副本冗余策略,具有和data log相同的保护等级。例如:data log使用EC4+2时,WAL使用3副本,WAL写盘后即可返回上层应用。

WAL使用的磁盘layout包括:
-
wal header:wal总体元数据,其中head中的begin/end表示wal payload的起止地址。
-
alloc header:管理data+metadata分配存储空间的元数据。wal payload被切分为不同segment,按照seg顺序环回分配。
-
data&meta:包括数据和元数据,按照4K切分。每个4K数据,对应于元数据中一个iomd,为减少空间放大,多个数据的元数据会进行合并写入。meta包含off+size,crc,clock(标识io顺序)等。数据和元数据以4K为单位顺序追加写,同时,元数据以kv形式缓存在内存中。

data log以4KB为单位采用append write方式落盘,元数据采用address mapping方式存储,并以4k为单位加载到内存,mapping缓存根据策略dump到磁盘,保证缓存和盘上数据一致性,并采用addr_log来保证flush过程的数据可靠性。data log 每段大小固定。
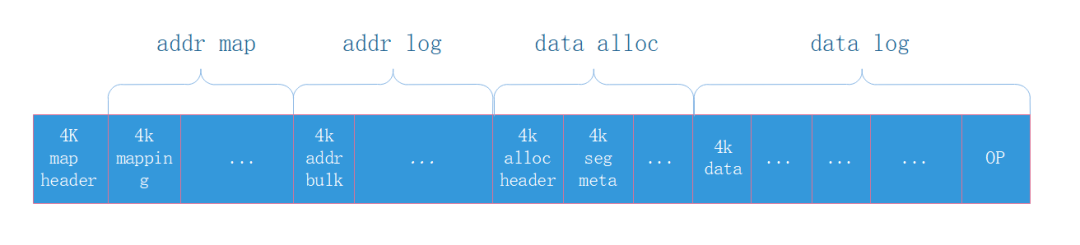
data log使用的磁盘layout包括:
-
map header:map元数据。用于flush和newloc定位。
-
addr map:映射表的落盘数据。以4k为单位,包含其中每个4K page的LBA。内存中加载保存了mappings缓存,并定期同步落盘。
-
addr log:记录wal flush时的log,以addr bulk的格式存储。
-
data alloc:管理数据page分配的元数据。alloc header记录总体信息。seg meta记录分配元数据。空间忽略不计。
-
data log:以4K为单位存储的数据。

data log支持GC。假设在物理地址n上写入数据D1,接下来在地址(n+1)写入数据D2,接着D1数据被更新为D1',但是更新后的数据并不是覆盖上去,会把它append写入到地址(n+2)上,然后标记地址n为"无效"。

经过多次这样的操作后,segment1装满了许多"有效"及"无效"的数据。如果要再次写入到这个segment1,就需要先把所有“有效”的数据复制到另外的空白空间segment2上,再回收segment1空间。这样的操作就是GC(即垃圾回收)。
GC需要预留空白空间叫OP(Over-Provisioning),OP和data log空间并没有明确界限区分,和data log使用同一个区域。并根据空间使用情况自动调整OP空间大小。
06
FASS 2.0 IO流程


07
带来的效益
