列表
“列表”是一种数据结构,可以存储多个值。

指标
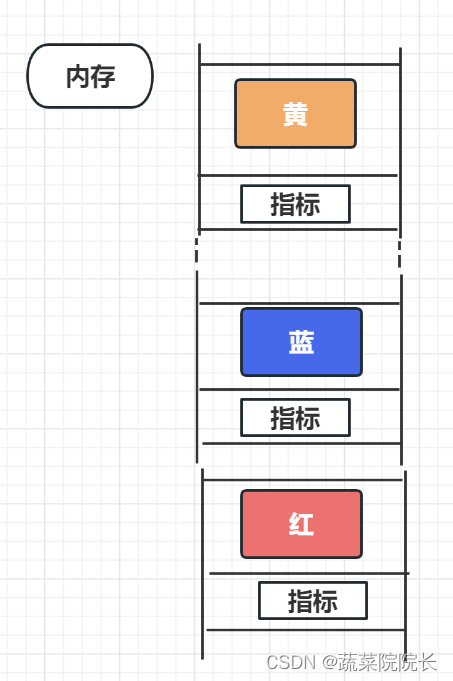
特点是如何将数据与“指标”配对,以及指示下一条数据的内存位置。
内存
在列表中,数据存储在内存中分散的位置。
顺序访问
由于数据存储在不通过的位置,每个数据只能通过其前面的指标来访问。
类似香港电影中的警察做危险的间谍任务时,只有他的上头知道他是警察,这样是为了保护,但是一旦其中一个警察的上头不幸出了意外,那这个警察就没有人来证明他是警察了。
数据的添加只需要通过替换添加任一侧的指针即可执行。

数组
“数组”是一种数据结构,可以存储多个值。
每个元素可以通过索引(数字表示数据的数量)进行访问。
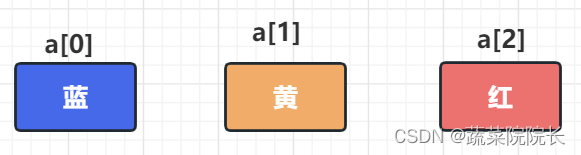
内存:数据按顺序存储在连续位置的存储器中。
随机访问:由于他们存储在连续的位置,因此可以使用他们的索引来计算内存地址,以便随机访问数据。
数据的另一个特点是与列表相比,在特定位置添加或者删除数据的成本很高。
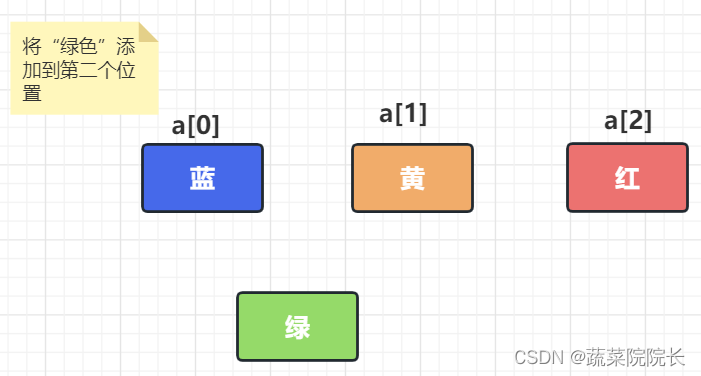
首先我们在数组的末尾确保额外的空间。
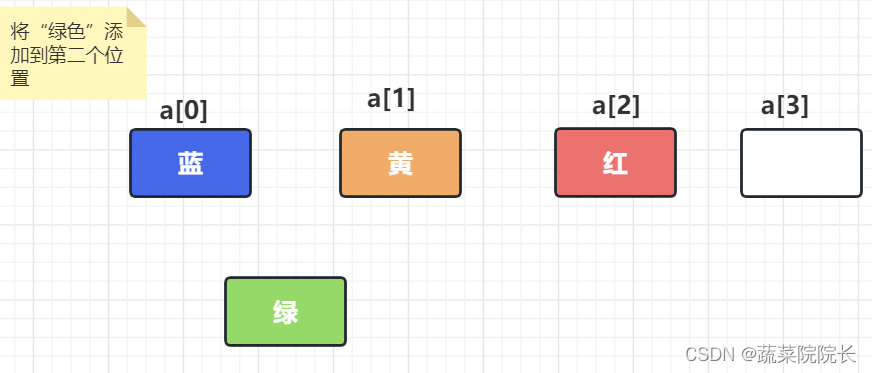
为了腾出空间来推荐爱,逐个移动数据。
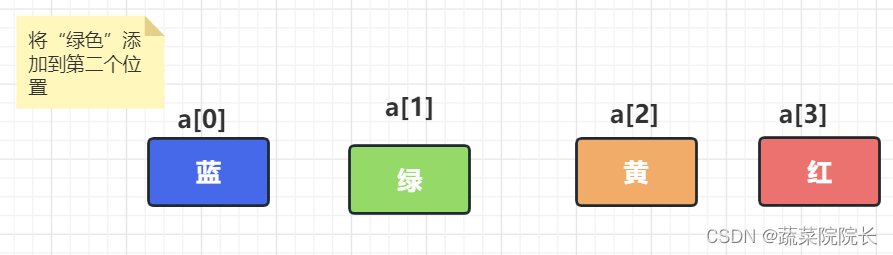
“绿色”被添加到空白处,完成添加。
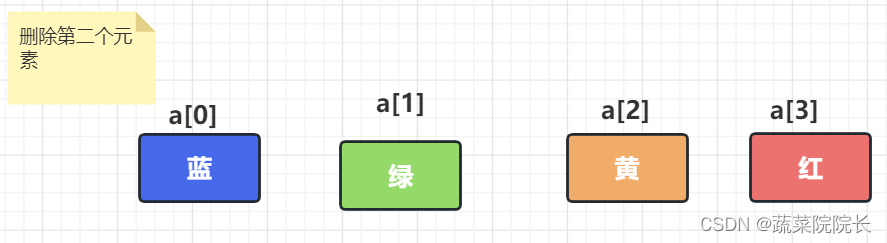
首先我们删除元素,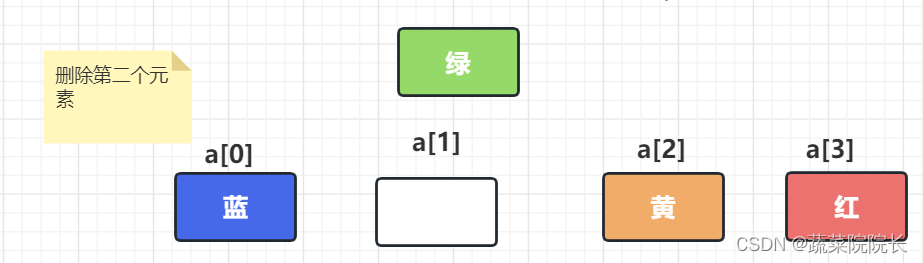 通过逐个移动数据填充空白空间。
通过逐个移动数据填充空白空间。
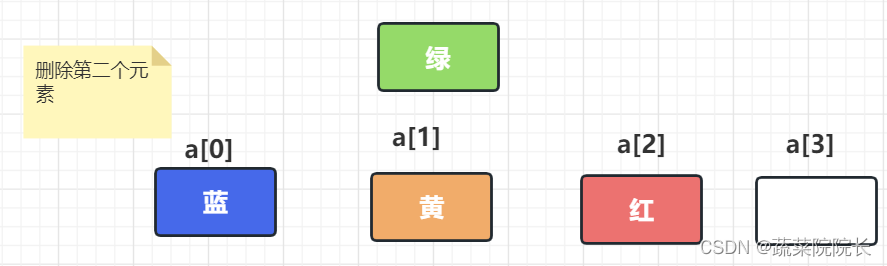
最后,通过删除额外的空间来完成删除操作。
栈
“栈”是一种数据结构。
栈的结构可以很容易地想象为一堆垂直堆叠的物品。
在堆积的山上取出物品时,我们会从顶部依次取出物品。
将数据添加到堆栈时,数据将添加到最后。
将数据添加到堆栈的操作称为“推入”。
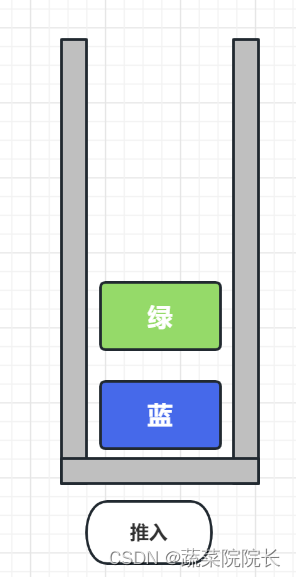
从栈中取出数据时,会从最近添加的数据开始取出。
从栈中取出数据的曹组器称为“弹出”。
这种首先取出最近添加的数据的方法称为“后进先出”(Last In First Out),或简称为“LIFO”。
队列
“队列“是一种数据结构。
队列也被称为“等待线”,正如名字所暗示的,它们很容易被想象成一群排队等待的人。
排队时,排队越早,优先级越高。
将数据添加到队列时,数据放在最后。
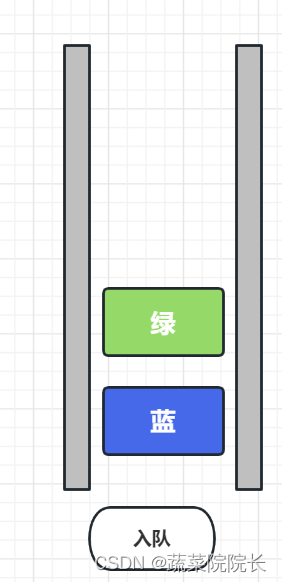
将数据添加到队列中的操作称为“入队”。
从队列中取出数据时,将从最早添加的数据开始取出。

从队列中取出数据的操作称为“出队”。
首先取出最初添加的数据的方法称为“先进先出”(First In First Out),或简称为“FIFO”。
哈希表
“哈希表”是一种数据结构。

擅长以“keys”和“values”组成的集合存储数据。
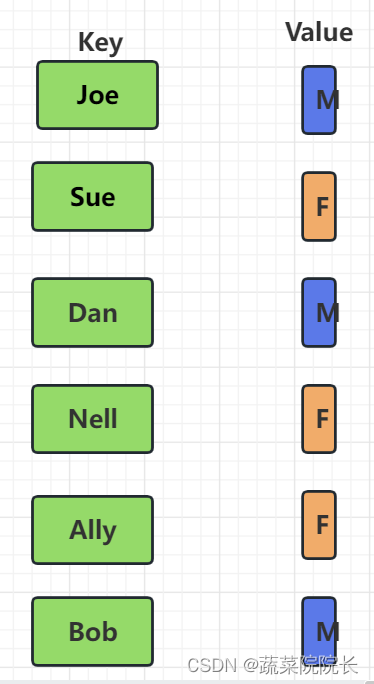
此时,名字是key,性别是value。
作为一个例子,将图中的数据想象为一个数组。
我们为数组准备了6个盒子,并在其中存储了数据。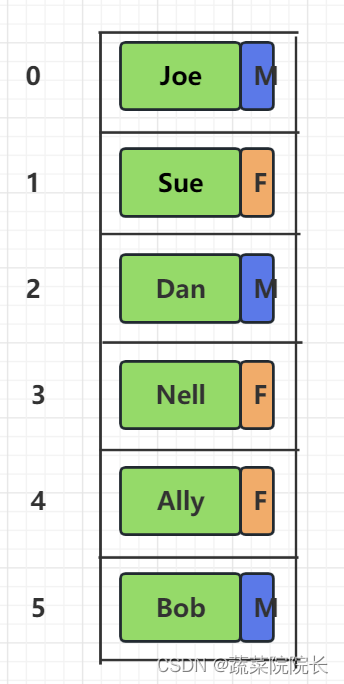
查找Ally的性别的情况:
我们不知道Ally存储在数组的第几个盒子里。
由此,我们需要从头开始搜索。这个操作被称为“线性搜索”。
存储在第0个盒子的数据的Key是Joe,而不是Ally。
盒子1也不是Ally。
盒子2也不是Ally。
盒子3也不是Ally。
存储在第4个盒子中的数据的Key和Ally匹配。通过取出相应的Value,我们发现Ally的性别是女性(F)。
这样,线性搜索操作的成本与数据大小成正比。
将数据存储在数组中时,需要花费一些时间来搜索数据,使其称为不合适的选择。
哈希表解决了这个问题。
我们将准备一个数组来存储一些数据,为了腐败,在数组中有5个盒子。
现在来存储一些数据。

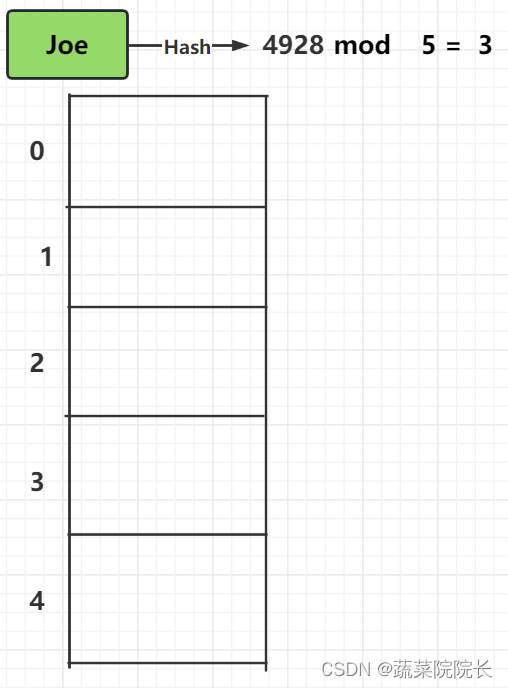
存储“Joe”的数据时,使用哈希函数(将数据转换为固定长度值的函数)计算密钥的哈希值。注释结果为4928。查找的哈希值除以数组中的盒子数5,以找出余数。查找除法余下部分的操作称为“mod”操作。mod操作的结果为3 。Joe 的数据存储在数组的第 3 个盒子中,与找到的数字相同。

该操作将被重复以存储其他数据。
找到密钥的 哈希值,并使用数组中的盒子数 5 对其执行 mod 运算。
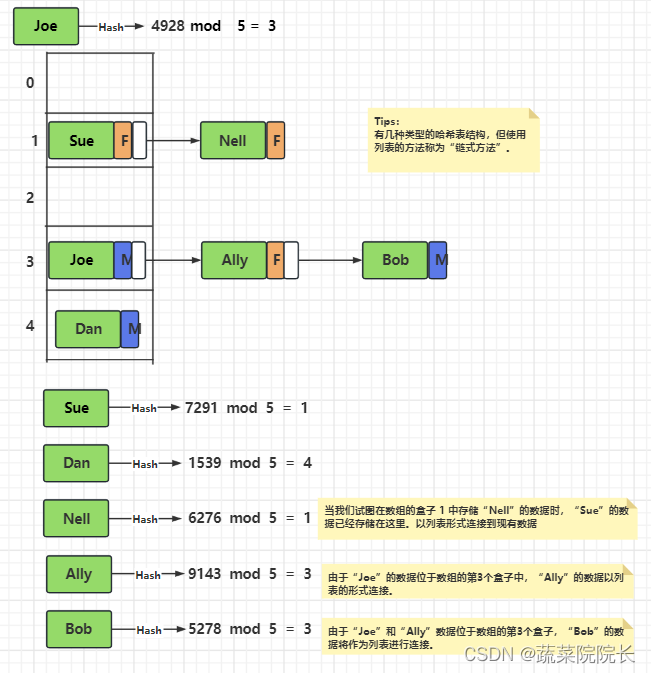
所有数据完成存储,哈希表完成。
此时再次查找Dan的性别情况。
为了知道Dan存储在第几个盒子的数组中,我们找到密钥的哈希值,并用数组中的盒子数 5 对它进行 mod 运算。结果为 4 。
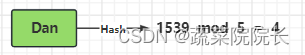
存储在数组的第4个盒子中的密钥匹配“Dan”。
通过取出相应的Value,我们得知Dan的性别是男性(M)。
查找其他数据以此类推。

通过使用哈希函数,哈希表能快速访问数组中的数据。
当 哈希值重叠时,将使用列表,从而可以灵活处理不确定数量的数据。
如果用于哈希值的数组的大小太小,则重复会增加并且线性搜索将更可能发生。
相反,如果数组的大小太大,会有很多数据盒子没有存储数据,浪费内存,因此需要谨慎。
能够灵活存储数据和快速查找的哈希值被用在编程语言的关联数组中。
堆
“堆”是一种树形结构,并在实现“优先队列”时使用。
优先队列是一种数据结构。
在优先队列中,数据可以按任意顺序添加。
相反,在取出数据时,首先选择最小值。(按数据从小到大的顺序取出)
能够自由地添加数据并从最小值开始取出,这被定义为优先队列。
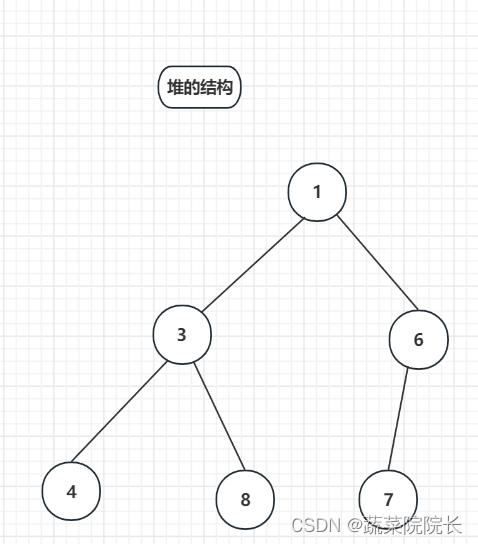

作为堆的一个规则,子类数字总是大于其父类数字。
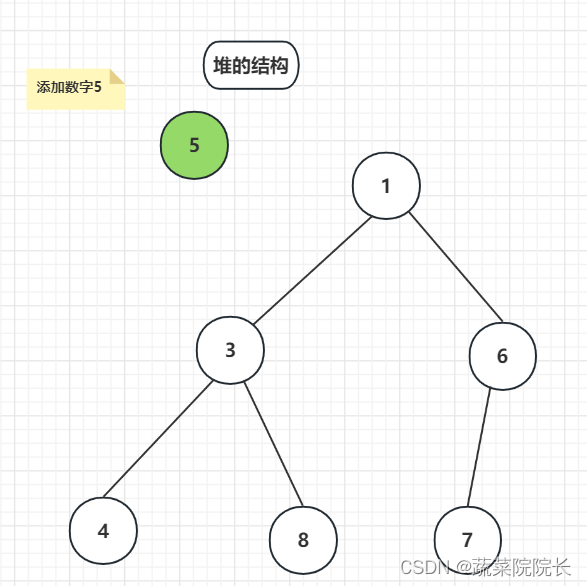
添加的数字将首先放在末尾。
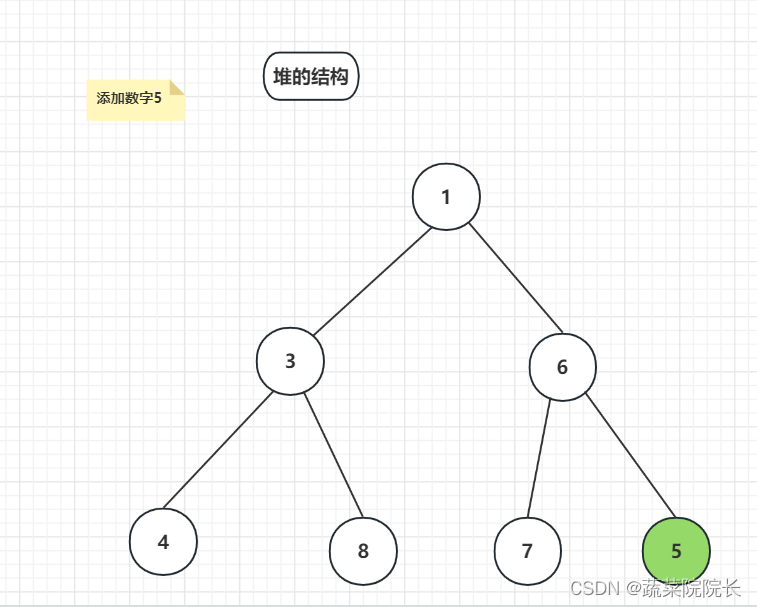 如果父类数字较大,则子类与父类互换。
如果父类数字较大,则子类与父类互换。
因为父类 6 > 子类 5 ,则替换数字。
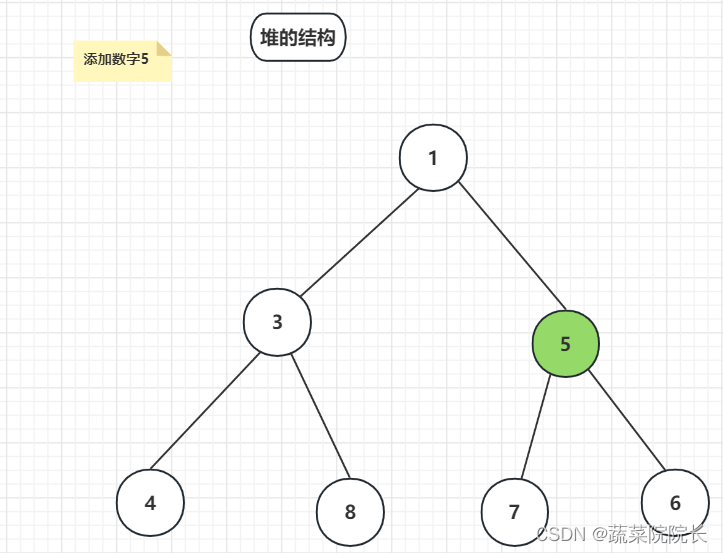
重复此操作,直到不发生替换。
父类 1 < 子类 5 ,由于父类的数字较小,所以不会发生替换。=》完成在堆中添加数字。
![]() 从堆中取出数字,从最上面的数字取出。
从堆中取出数字,从最上面的数字取出。

在堆中,最小值保存在顶部位置。
由于在顶部的数字被取出,我们需要组织堆的结构。
将结尾的数字移动到顶部。
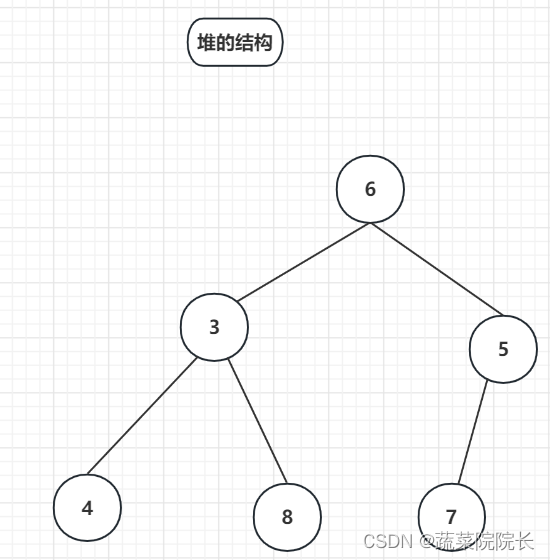
当子类数字小于父类数字时,相邻子类数字中较小的数字与父类数字交换。
由于父类 6 > 右侧子类 5 > 左侧子类 3 ,则左侧子类与父类交换。
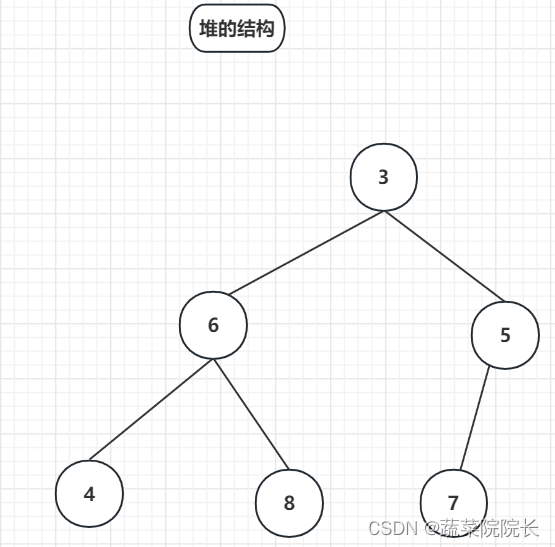
重复此操作,直到不发生替换。
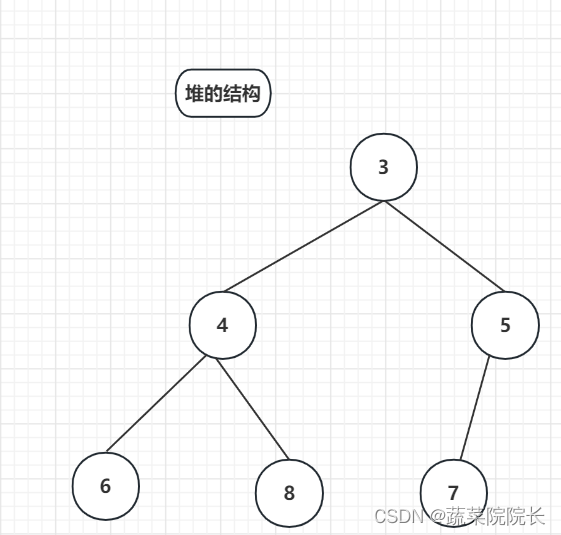
这样使用堆可以快速取出最小的数据。
但是,无法执行在树中间取出数据的操作。
堆用于如优先队列和戴克斯特拉算法等。
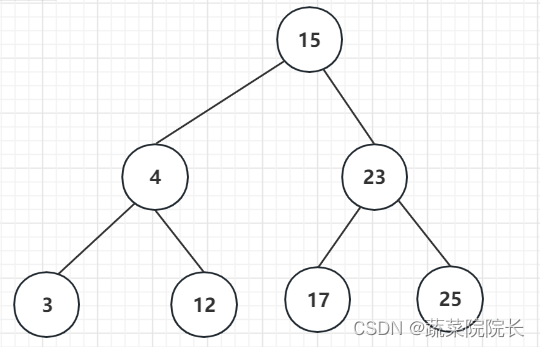
二叉查找树
一种数据结构。
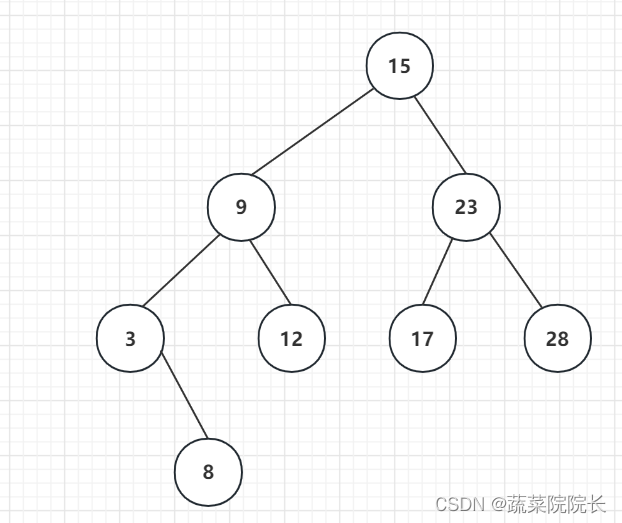
有编号的点称为“节点”。
二叉查找树有两个属性。
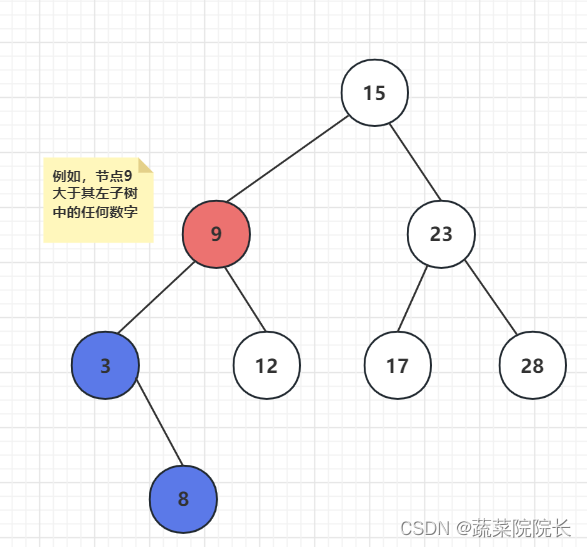
第一个属性是所有节点都比左子树中的节点大。

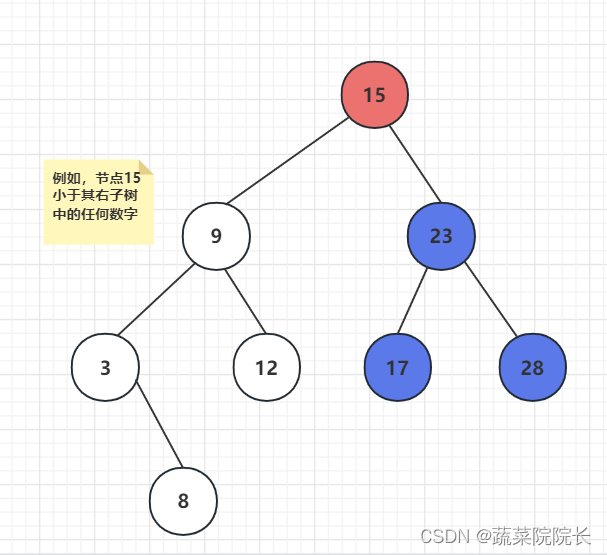
相反,它们的第二个属性是所有节点都小于其右子树中的节点。
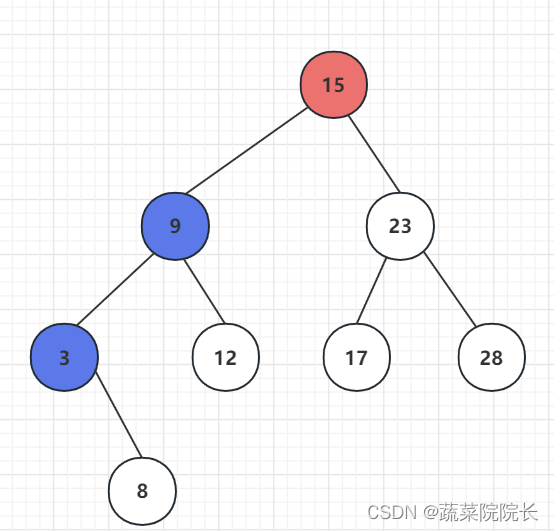
首先,二叉查找树最小节点位于最顶端节点的最左边的子树行的末尾。
相互,二叉查找树的最大节点位于最顶端节点的最右边的子树行的末尾。
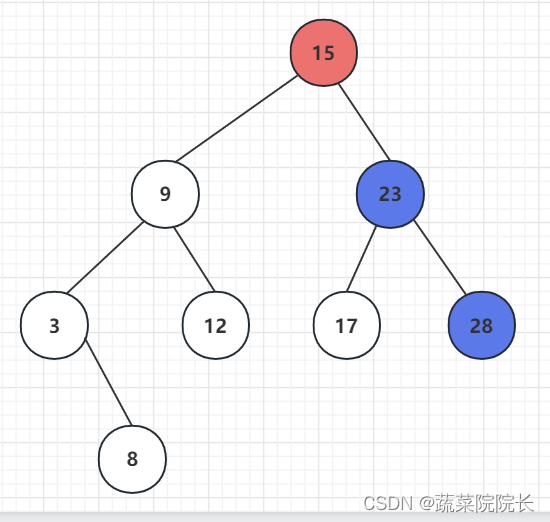
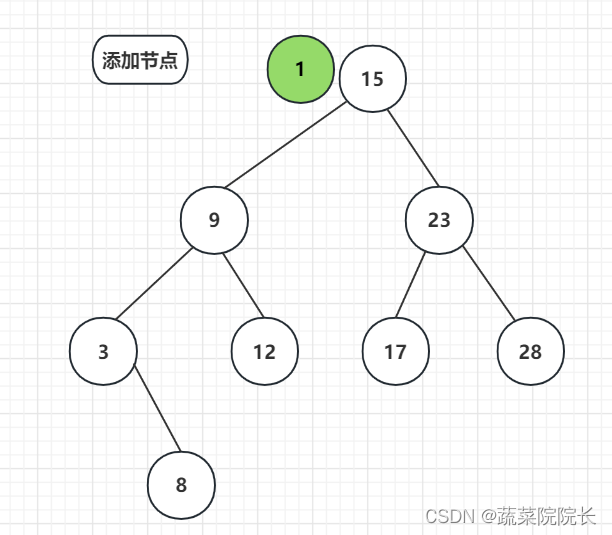
从二叉查找树的最顶端节点开始,以便找到附加节点的正确位置。
由于 1 < 15 ,向左走。
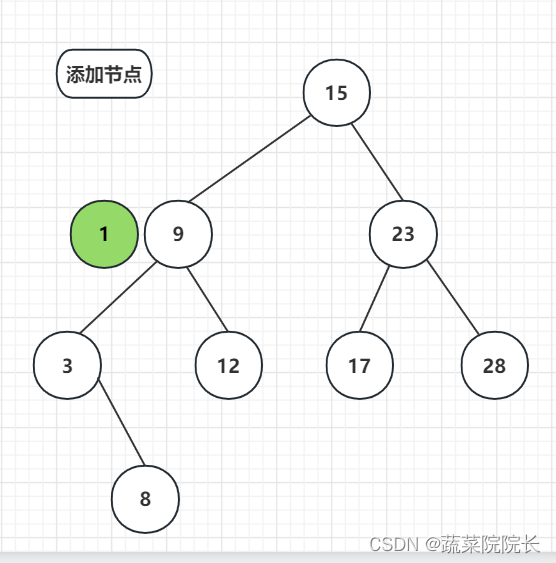
由于 1 < 9 ,继续向左走。
由于1 < 3 ,继续向左走,但因为没有节点在前方,所以我们将它添加为一个新节点。
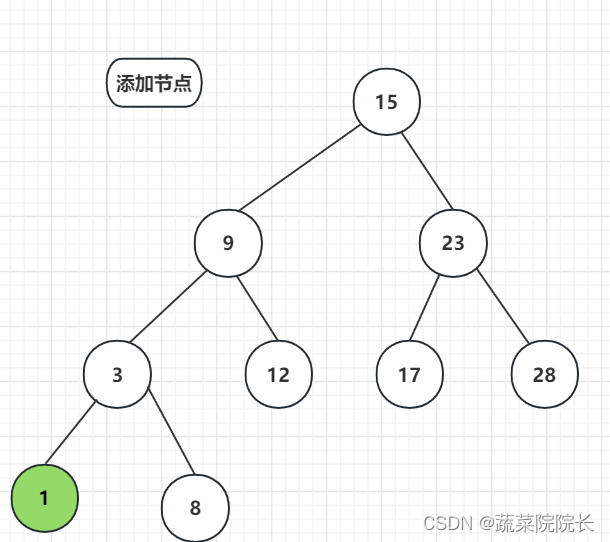
添加其他数字,以此类推。
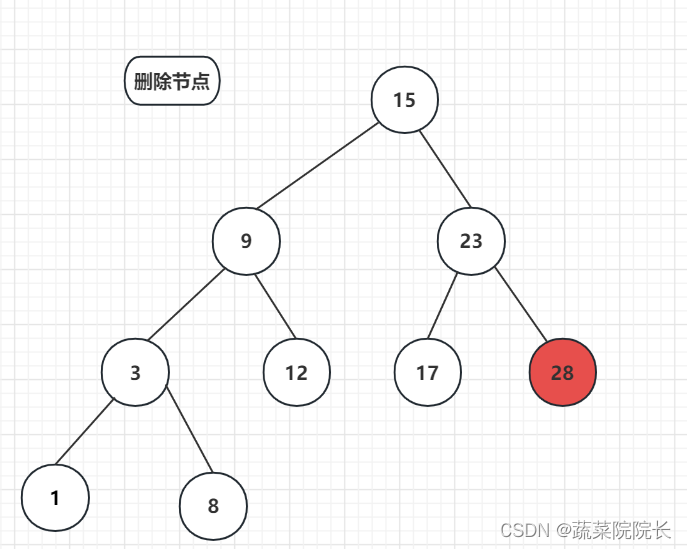
当节点没有子类时,只需要删除目标节点即可完成。
目标节点被删除,将子节点移动到已删除节点的位置即可。

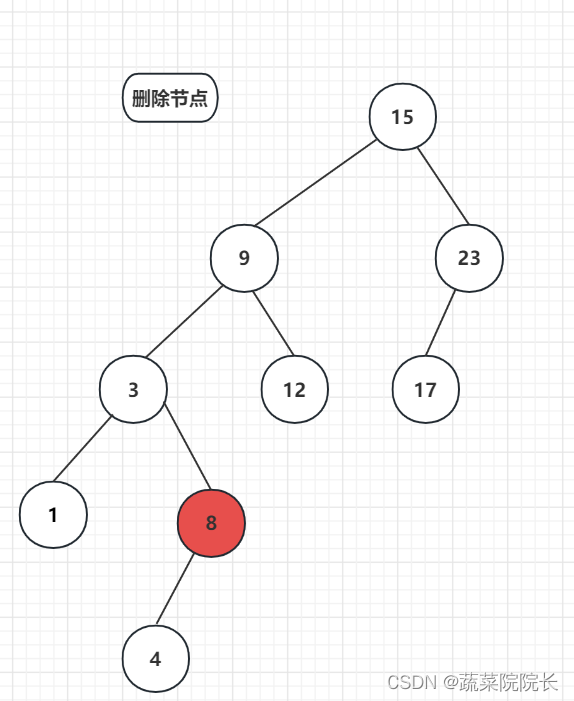
删除有两个子类节点时,首先删除目标节点。
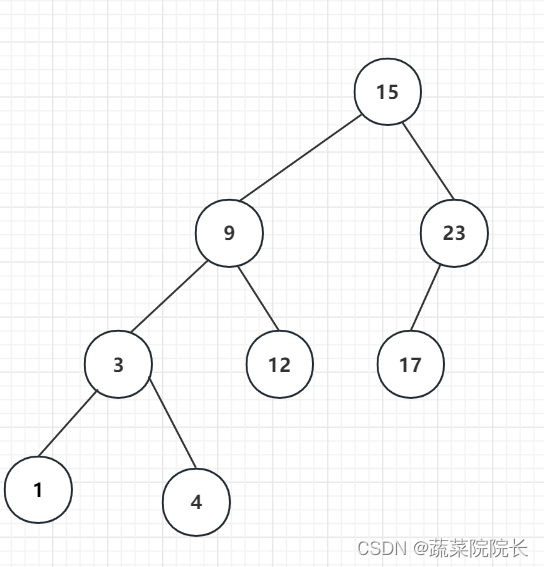
并从删除节点的左子树中找到最大节点,并将其移动到删除的节点的位置。
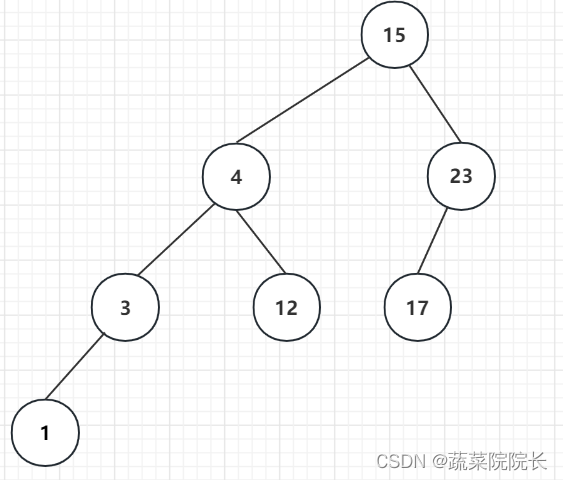
如果节点被移动 了也有它自己的子节点,那么递归地重复相同的过程。
而且,尽管我们使用了左侧最大的节点,但使用右侧子树中的最小节点也是如此。
使用二叉查找树可以实现高效搜索。
但是,如果树接近形成直线,其搜索效率将非常差,如线性搜索。

另一方面,一直保存良好平衡的二叉查找树称为“自平衡二叉查找树”,能够保存搜索效率。