一、实训的任务
1. 爬虫编写: 选择自己感兴趣的内容主页,抓取不同类别的文本语料(如不同类型电影影评,不同微博热点事件的相关微博,体育论坛中不同类别体育运动的主题帖,小红书等软件中的用户发布内容等),要求每种类型的语料抓取数量不少于500条。
2. 文本特征抽取:对每个文本进行分词,统计词频并计算每个文本中每个词的tfidf值。Tfidf概念参考http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
(其中,分词软件选择课堂上使用过的jieba。Tfidf等特征选择方法推荐自己编写代码,包括之后要使用的分类器,使用sklearn模块只能拿到基本分,自己编程分数高)
3. 可视化:使用matplotlib对数据分布进行展示,可统计任何数据(如tfidf值在[0-1]区间内各个阶段的分布,抓取的文本数据数量等),可使用折线图、柱状图等多种图形进行展示。
4. 对数据进行PCA降维,并用matplotlib对数据进行展示(PCA降维使用sklearn)
5.了解词袋模型,使用词袋模型对每个文本进行表示,分别使用监督学习方法:朴素贝叶斯模型、K近邻模型,无监督学习方法:层次聚类、K均值聚类方法,对文本进行分类或聚类,使用matplotlib对类别进行展示。
6. 比较四个模型的区别,并对四种模型的效果进行评估(查全率Recall、查准率Precision、F值)。
二、实训的要求
1.介绍抓取的内容;
2.将代码与结果呈现在报告中,为代码加上详细的注释,呈现自己对模型的理解;
3.详述模型之间的比较;
三、实训主要工作内容
(1)代码实现:

#爬取豆瓣电影各类电影影评
import requests
from lxml import etree
import json
import time
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36',
'Cookie': 'll="118092"; bid=o5fp9vJKkwE; __gads=ID=6f6967728a0d43ca-22b53e3dabc5004f:T=1610534082:RT=1610534082:S=ALNI_MZeFcZZY3MI4OkRdCK3WbxYo2SGvw; __yadk_uid=MgFVt6KG7iVEIjEcBw7gA1Bwo5mYBO0A; _vwo_uuid_v2=D1EB6A0EF9C5E188D4B5B877FFD37DC75|b9b5ad06d0f405efe5cc26f72d9fc69d; douban-fav-remind=1; _ga=GA1.2.220443010.1610534081; _vwo_uuid_v2=D1EB6A0EF9C5E188D4B5B877FFD37DC75|b9b5ad06d0f405efe5cc26f72d9fc69d; dbcl2="248942433:d3RetGd1rsE"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.24894; ck=VAo3; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1636037603%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DMctuipbR0LHu9aEklsCPzXAWNNUqSPuXQanWiOLbWGgYamMahdqS7zCDGkLrykRt%26wd%3D%26eqid%3Dacdd267300051430000000056183f3e0%22%5D; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utma=30149280.220443010.1610534081.1635514804.1636037603.12; __utmc=30149280; __utmz=30149280.1636037603.12.11.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.66655176.1610534081.1635514833.1636037603.5; __utmb=223695111.0.10.1636037603; __utmc=223695111; __utmz=223695111.1636037603.5.4.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; ct=y; __utmt=1; __utmb=30149280.4.10.1636037603; _pk_id.100001.4cf6=bec7c019f9f6d24d.1610534080.5.1636041481.1635515565.'
}

#获取电影影评
def crawling(id,f):
index = 0
start = 0
while True:
try:
# 未登陆爬取豆瓣影评服务器返回403禁止访问,使用账号登陆后加入Cookie后继续访问
url = 'https://movie.douban.com/subject/'+str(id)+'/comments?start=' + str(
start) + '&limit=20&status=P&sort=new_score'
if (start > 40): # 设置所要爬取的评论条数的上限
break
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
selector = etree.HTML(response.text)
comments = selector.xpath("//div[@id='comments']/div[@class='comment-item ']/div[@class='comment']")
if (len(comments) == 0):
break
for i in range(len(comments)):
index += 1
reviewer_name = comments[i].xpath("h3/span[@class='comment-info']/a/text()")[0]
comment_star = comments[i].xpath("h3/span[@class='comment-info']/span")[1].xpath("@class")[0] + ""
comment_time = comments[i].xpath("h3/span[@class='comment-info']/span[@class='comment-time ']")[0].xpath(
"string(.)").strip()
comment_content = comments[i].xpath("p/span[@class='short']")[0].xpath("string(.)").strip().replace('\n',
'').replace(
'\r', '')
f.write(comment_content+'\n')
start += 20
except Exception as e:
print(e)
break
sum_url='https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0&genres=剧情'
type_movie=['剧情','喜剧','动作','爱情','科幻','动画','悬疑','冒险','灾难','武侠','奇幻','西部','战争','历史','传记','歌舞','音乐','恐怖','犯罪']
#分别获取各类电影内的电影id
for tt in type_movie[-2:]:
sum_url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0&genres='+tt
reponse=requests.get(sum_url,headers=headers).text
reponse=json.loads(reponse)
text_dir='./data/'+tt+'.txt'
with open(text_dir,'a+',encoding='utf-8')as f:
for i in reponse['data']:
print(i['id'],i['title'])

#获取电影影评
crawling(i['id'],f)
time.sleep(2)

#读取数据,生成DataFrame
type_movie=['剧情','喜剧','动作','爱情']#,'科幻','动画','悬疑','冒险','灾难','武侠','奇幻','西部','战争','历史','传记','歌舞','音乐','恐怖','犯罪']
text_list=[]
label_list=[]
for num in range(0,len(type_movie)):
file_path='./data/'+type_movie[num]+'.txt'
with open(file_path,encoding='utf-8')as f:
content=f.read()
for word in content.split('\n'):
a=[]
a.append(word)
a.append(num)
text_list.append(a)
tfidf=pd.DataFrame(text_list,columns=['text','label'])
tfidf.head()

#jieba分词,去停用词
with open('stopwords.txt',encoding='utf-8')as f:
s_content=f.read()
ss=s_content.split('\n')
#该步骤由于没有使用sklearn封装函数 故受用时间很长约40秒
sum_out_str_list=[]
n=0
for sentence in tfidf['text']:
outstr=''
sentence_depart=jieba.cut(str(sentence).strip())
for word in sentence_depart:
if word not in ss:
if word != '\t':
outstr += word+' '
sum_out_str_list.append(outstr)
tfidf.loc[:,('text')]=sum_out_str_list
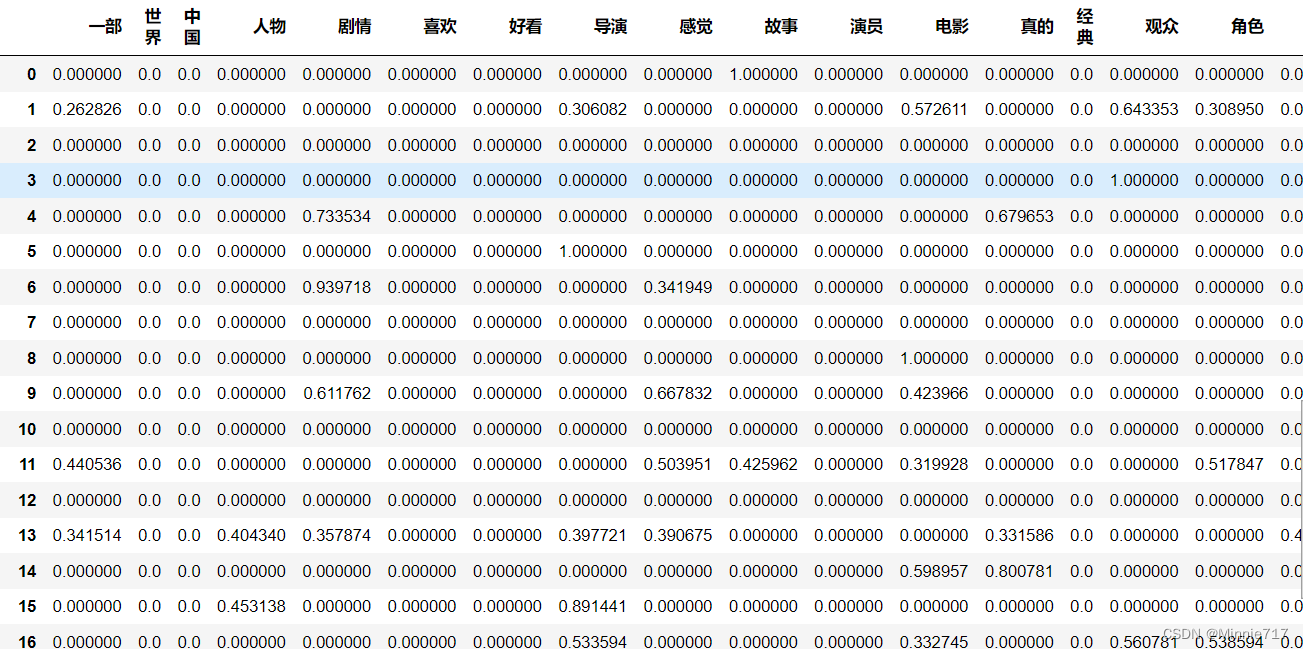
tfidf_model=TfidfVectorizer(max_features=18)
tfidf_df=pd.DataFrame(tfidf_model.fit_transform(tfidf['text']).todense())
tfidf_df.columns=sorted(tfidf_model.vocabulary_)
tfidf_df.head()

#计算tfidf 提取文本特征
tfidf_model=TfidfVectorizer(max_features=1000)
tfidf_df=pd.DataFrame(tfidf_model.fit_transform(tfidf['text']).todense())
tfidf_df.columns=sorted(tfidf_model.vocabulary_)
tfidf_model1=TfidfVectorizer(max_features=50)
tfidf_df1=pd.DataFrame(tfidf_model1.fit_transform(tfidf['text']).todense())
tfidf_df1.columns=sorted(tfidf_model1.vocabulary_)
tfidf_df.head()
#PCA降维
from sklearn .decomposition import PCA
pca=PCA(2)
pca.fit(tfidf_df)
reduced_tfidf=pca.transform(tfidf_df)
reduced_tfidf
import matplotlib.pyplot as plt
import matplotlib
import matplotlib.font_manager as fm
myfont = fm.FontProperties(fname="msyh.ttc", size=14)
matplotlib.rcParams["axes.unicode_minus"] = False
scatter=plt.scatter(reduced_tfidf[:,0],reduced_tfidf[:,1],c=tfidf['label'],cmap='coolwarm')
plt.show()

#将文本用词袋模型表示
from sklearn.feature_extraction.text import CountVectorizer
def vectorize_text(corpus,n):
bag_of_words_model=CountVectorizer(max_features=n)
#统计词频
dense_vec_matrix=bag_of_words_model.fit_transform(corpus).todense()
#转换为dataframe
bag_of_word_df=pd.DataFrame(dense_vec_matrix)
#添加列名
bag_of_word_df.columns=sorted(bag_of_words_model.vocabulary_)
return bag_of_word_df
df_1=vectorize_text(sum_out_str_list,2500)
df_2=vectorize_text(sum_out_str_list,25)
#朴素贝叶斯模型
from sklearn import metrics
import numpy as np
from sklearn.naive_bayes import MultinomialNB
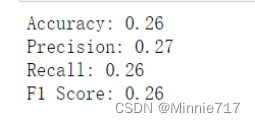
def get_metrics(true_labels, predicted_labels):
print('Accuracy:', np.round(
metrics.accuracy_score(true_labels,
predicted_labels),2))
print('Precision:', np.round(
metrics.precision_score(true_labels,
predicted_labels,
average='weighted'),2))
print('Recall:', np.round(
metrics.recall_score(true_labels,
predicted_labels,
average='weighted'), 2))
print('F1 Score:', np.round(
metrics.f1_score(true_labels,
predicted_labels,
average='weighted'), 2))
data = np.array(df_1.iloc[:])
x, y = data[:,:-1], tfidf['label']#特征 标签
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2) # 二八划分
nb=MultinomialNB()
nb.fit(x_train,y_train)
predictions=nb.predict(x_test)
get_metrics(true_labels=y_test,predicted_labels=predictions)

#K近邻模型
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
def get_metrics(true_labels, predicted_labels):
print('Accuracy:', np.round(
metrics.accuracy_score(true_labels,
predicted_labels),2))
print('Precision:', np.round(
metrics.precision_score(true_labels,
predicted_labels,
average='weighted'),2))
print('Recall:', np.round(
metrics.recall_score(true_labels,
predicted_labels,
average='weighted'), 2))
print('F1 Score:', np.round(
metrics.f1_score(true_labels,
predicted_labels,
average='weighted'), 2))
data = np.array(df_1.iloc[:])
X, y = data[:,:-1], tfidf['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1) # 二八划分
#print(X_train.shape)
#print(y_train)
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train, y_train)
y_predict =knn.predict(X_test)
get_metrics(y_test,y_predict)
#K聚类Kmeans
from sklearn.cluster import KMeans, MiniBatchKMeans
def train(X, true_k=10, minibatch=False, showLable=False):
# 使用采样数据还是原始数据训练k-means,
if minibatch:
km = MiniBatchKMeans(n_clusters=true_k, init='k-means++', n_init=1,
init_size=1000, batch_size=1000, verbose=False)
else:
km = KMeans(n_clusters=true_k, init='k-means++', max_iter=300, n_init=1,
verbose=False)
km.fit(X)
result = list(km.predict(X))
print('Cluster distribution:')
print(dict([(i, result.count(i)) for i in result]))
return -km.score(X)
#指定簇的个数k
def k_determin(tfidf_df):
true_ks=[]
scores=[]
#中心点的个数从3到200(根据自己的数据量改写)
for i in range(3, 20, 1):
score = train(tfidf_df, true_k=i)# / len(dataset)
print(i, score)
true_ks.append(i)
scores.append(score)
plt.figure(figsize=(8, 4))
plt.plot(true_ks, scores, label="error", color="red", linewidth=1)
plt.xlabel("n_features")
plt.ylabel("error")
plt.legend()
plt.show()
def main():
'''在最优参数下输出聚类结果'''
dataset = get_dbdata()
X, vectorizer = transform(dataset, n_features=500)
score = train(X, vectorizer, true_k=25, showLable=True) / len(dataset)
print(score)
#层次聚类
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
dist = df_2.corr()
import matplotlib.pyplot as plt
import matplotlib as mpl
from scipy.cluster.hierarchy import ward, dendrogram
linkage_matrix = ward(dist) #使用Ward聚类预先计算的距离定义链接矩阵
fig, ax = plt.subplots(figsize=(10, 6)) # set size
ax = dendrogram(linkage_matrix, orientation="right")#, labels=tfidf['label'][:25]);
plt.tick_params(
axis= 'x', # 使用 x 坐标轴
which='both', # 同时使用主刻度标签(major ticks)和次刻度标签(minor ticks)
bottom='off', # 取消底部边缘(bottom edge)标签
top='off', # 取消顶部边缘(top edge)标签
labelbottom='off')
plt.tight_layout() # 展示紧凑的绘图布局

对文本的层次聚类分析:

五、实训的收获和体会
整体而言,构建的模型在对文本的分类方面无法很好的提高其准确率。原因为以下几点:
(1):文本类型过于繁多,部分文本类型相似度极高;
(2):单一文本内的语料过少,导致模型训练时形成常见词的权重很高,而真正属于本文本类型的特征权重影响被大大削弱,导致对文本分类的准确度大大降低;
(3):本次的文本分类模型构建的并不复杂,并没有针对本语料调整词袋模型内语料特征向量,这是本次实训内容的缺点同样也是痛点;
(4):分词并去停用词后,仍有大量的干扰词汇存在文本中,在接下来的模型训练中亦产生了大量的影响。
本次实训建立的监督学习方法:朴素贝叶斯模型、K近邻模型:在文本的分类的过程中可以很明显的显示出来其各自的优缺点:
K近邻模型:
优点:精度高、对异常值不敏感
缺点:计算复杂度高、空间复杂度高
朴素贝叶斯的主要优点有:
1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
2)对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
朴素贝叶斯的主要缺点有:
1) 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
4)对输入数据的表达形式很敏感。
而对于无监督学习聚类模型中:层次聚类模型中与K均值聚类方法相比:
K均值聚类方法:算法快速、简单;对大数据集有较高的效率并且是可伸缩性的;对本次的文本聚类的效果较好;
层次聚类模型:时间复杂度高,对复杂的词袋模型,需要的计算条件都远远大于K均值聚类方法,需要的时间也是较为长的。
六、参考文献
[1]张文强. 网络数据采集技术的研究与应用[D]. 华北电力大学(北京), 2018.
[2]李晓红. 中文文本分类中的特征词抽取方法[J]. 计算机工程与设计, 2009.
[3]黄岷昊, 丁浪, 张雪莲. 基于Python的网络爬虫及文本可视化[J]. 电脑编程技巧与维护(7):2.
[4]张荑阳, 毛红霞. 基于python的豆瓣电影数据采集与分析可视化[J]. 电子制作, 2021(16):3.
[5]冯悦悦. 基于Python的豆瓣电视剧统计分析[D]. 湘潭大学, 2019.
[6]张少军, 曾嘉. 利用Python爬虫分析影评与舆情关系的启示[J]. 东南传播, 2019, 000(008):76-78.