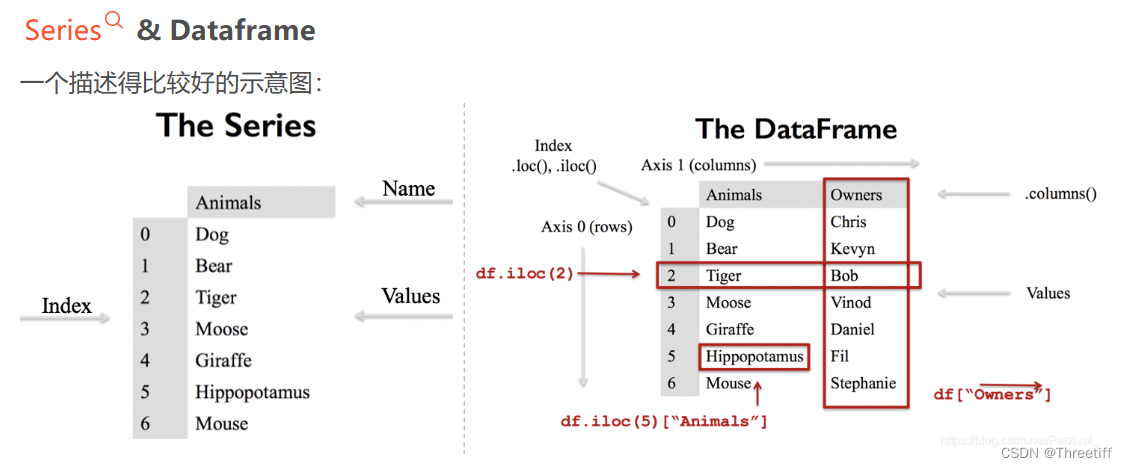
一维数据的Dataframe是series
对于Dataframe而言:
行是indexs,列是columns
1、创建Dataframe
- 创建空Dataframe
import pandas as pd
df = pd.DataFrame()
- 1、用字典创建Dataframe
# 1 直接创建
data = {'name':['apple','egg','watermelon'],'color':['red','yellow','green'],'num':[30,40,50]}
df1 = pd.DataFrame(data)
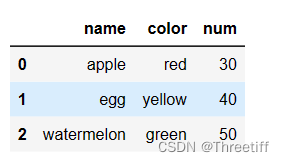
- 2、自定义列顺序(列的顺序可以发生变化)
# 2 自定义列顺序(列的顺序可以发生变化)
# 利用columns
df2 = pd.DataFrame(data,columns=['name','num','color'])
df2
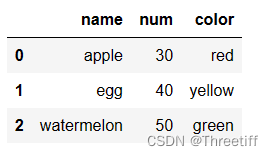
- 3、自定义行索引名
# 利用index
# 自定义行索引名
df3 = pd.DataFrame(data,index=['No.1','No.2','No.3'])
df3
# 或者使用range(start,end,interval)函数,生成的序列不包含end
df3_1= pd.DataFrame(data,index=range(0,6,2))

- 4、列名数超过原数据则创建空列(行索引不可以超过行数)
# 列名数超过原数据则创建空列
# data数据只有三列,多的一列将创建新的一列,默认是NaN
df4 = pd.DataFrame(data,columns=['name','num','color','price'])

2、获取行/列名列表【注意是列表】
- 1、行列表
df3 = pd.DataFrame(data,index=['No.1','No.2','No.3'])
print(df3._stat_axis.values)
print(df3._stat_axis.values.tolist()) # 转为列表
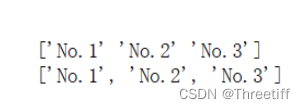
- 2、列列表
# 方法1
list(df3)
# 方法2
df3.columns.values.tolist()

3、索引和切片
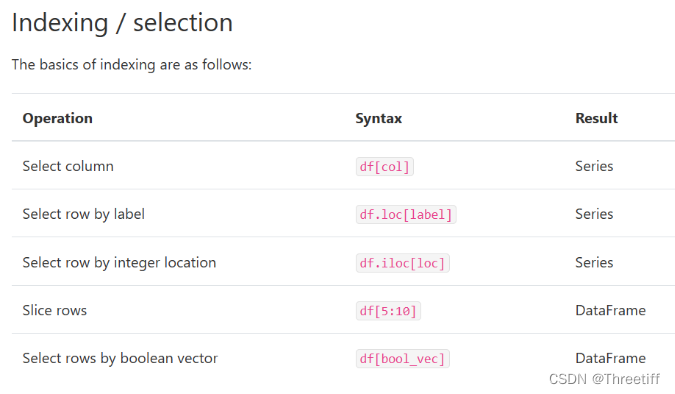
loc:location,根据行/列名索引
iloc:integer location,根据行/列数索引
- 1、行(只能借助loc和iloc,不可以使用行名)
# loc
# 读取特定行特定列的数据
df3.loc[['No.1','No.3'],['name','color']] # []先行后列
# 进行切片,包括末尾的数据
df3.loc['No.1':'No.3','name':'color']
# **************************************************
# iloc
df3.iloc[2] # 得到第3行全部数据
df3.iloc[1:] # 得到第2行以后全部数据, 行切片
# 根据值查找行索引
df3[df3['name']=='apple'].index # 得到'name'列下为'apple'的行索引'index'
df3[df3['name']=='apple'].index

- 2、列(可使用列名;也可以使用loc/iloc)
df3['name'] # 得到该列所有数据
df3.loc[:,'name':'num'] # 得到从'name'列到'num'列的所有数据
df3.iloc[:,1] # 得到第1列所有数据

- 3、行+列
df3.iloc[1:,-2:] # 从第1行到最后,从倒数第2列到最后
# 范围搜索
df3[df3['num']>30] # 搜索num>30的所有行
df3['name'][df3['num']>30] # num>30的所有行的'name'信息

4、添加列
dataframe内的每一列的数据类型是series
- 1、添加空列
df3['price'] = '' # 方法一
df3['price'] = pd.Series(dtype='int',index=['No.1','No.2','No.3']) # 方法二
df3['price'] = 0 # 方法三 全部赋值为0

注意:不能用空列表[]初始化
- 2、添加/在指定位置插入列
对索引顺序没有要求,直接添加的话,默认放在最后
df3['price']=[1,2,3] # 对索引顺序没有要求

对索引顺序有要求的用Series添加
# 如果使用Series不指定索引,将全部初始化为NAN
df3['price']=pd.Series([1,2,3])
# 如果使用Series指定索引index,可实现初始化
df3['price']=pd.Series([1,2,3],index=['No.2','No.1','No.3'])
# 索引和前面的值是对应的

5、删除行/列
- 1、行
利用drop()函数
df3.drop('No.3') # 只这样的话,不会删除原始数据
df3.drop('No.3',inplace=True) # 这样的话,会删除原始数据
# 或者
df4 = df3.drop('No.3') # 新得到的df4将不包含No.3'这一行

- 2、列
利用del函数
del df3['price'] # 直接在原数据上删除列

利用drop()函数
# 注意:axis=0,默认参数是删除行
# axis=1,删除列
# inplace=True:直接删除原数据
df3.drop('num', axis=1, inplace=True)

6、 读取/写入csv、excel为dataframe
- 1、读取数据
read_csv()
# 参数
pandas.read_csv(filepath_or_buffer, *, sep=_NoDefault.no_default,
delimiter=None, header='infer', names=_NoDefault.no_default,
index_col=None, usecols=None, squeeze=None,
prefix=_NoDefault.no_default, mangle_dupe_cols=True, dtype=None,
engine=None, converters=None, true_values=None, false_values=None,
skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None,
na_values=None, keep_default_na=True, na_filter=True, verbose=False,
skip_blank_lines=True, parse_dates=None, infer_datetime_format=False,
keep_date_col=False, date_parser=None, dayfirst=False,
cache_dates=True, iterator=False, chunksize=None,
compression='infer', thousands=None, decimal='.',
lineterminator=None, quotechar='"', quoting=0, doublequote=True,
escapechar=None, comment=None, encoding=None,
encoding_errors='strict', dialect=None, error_bad_lines=None,
warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False,
low_memory=True, memory_map=False, float_precision=None, storage_options=None)
read_excel()
# 参数
pandas.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None, usecols=None, squeeze=None,
dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None,
na_values=None, keep_default_na=True, na_filter=True,
verbose=False, parse_dates=False, date_parser=None,
thousands=None, decimal='.', comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
- 2、写入dataframe
df.to_excel(sheet_name='sheet1',startcol=0,index=False)
df.to_csv("test.csv", index=False)
7、其他操作
查看前几行
df3.head() # 默认5行,可传入数值指定行数
学习链接: