本次目标解析网站如下:
陕西省政府采购网
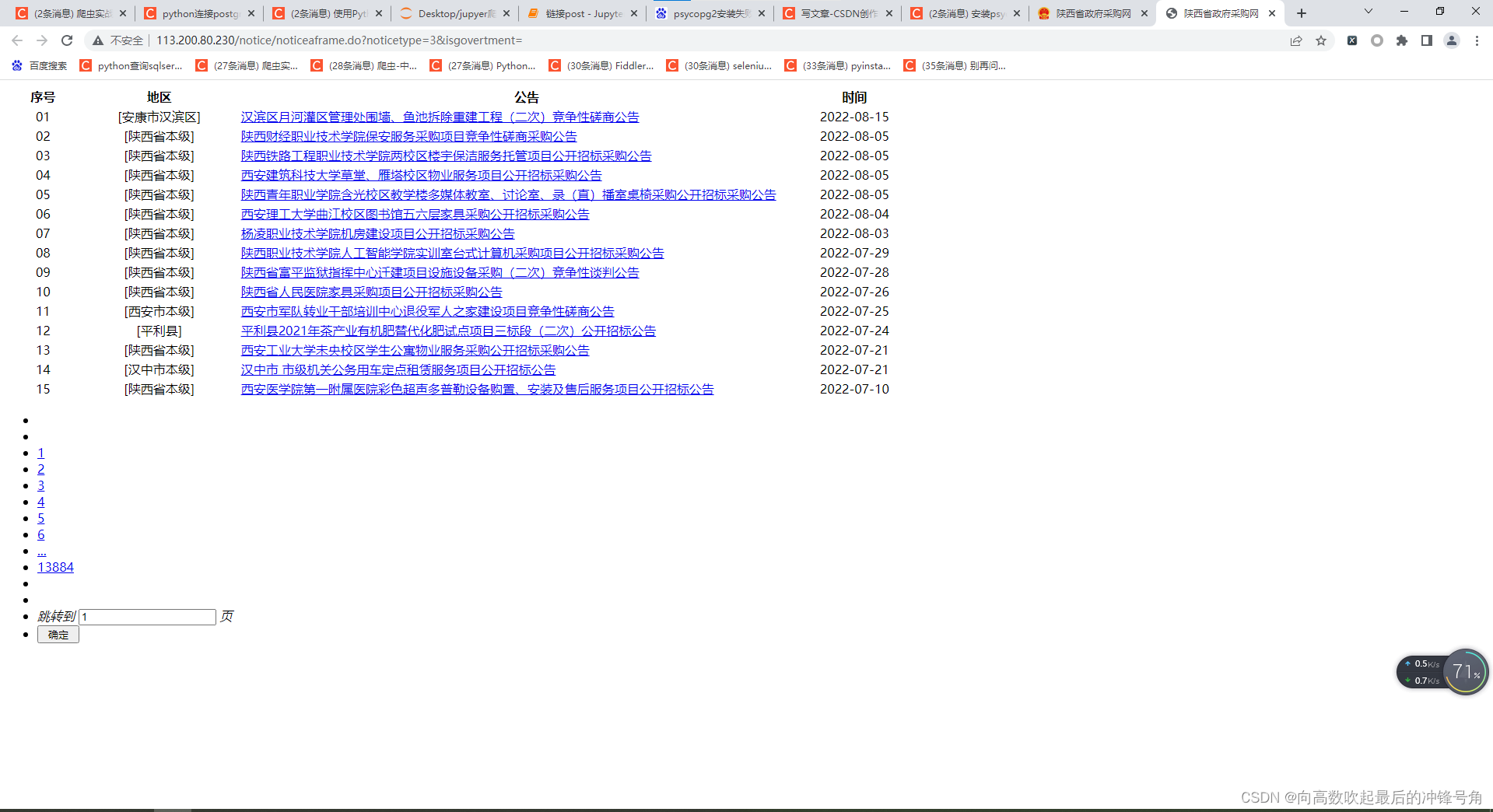
网站具体长这样
我们要的是
右下角部分的详细信息公告

打开这个界面后
点击鼠标右键
选择“检查”
无论是哪个浏览器这一步都选择“检查”
这里推荐使用谷歌浏览器
(准备插入一个安装谷歌浏览器的链接)
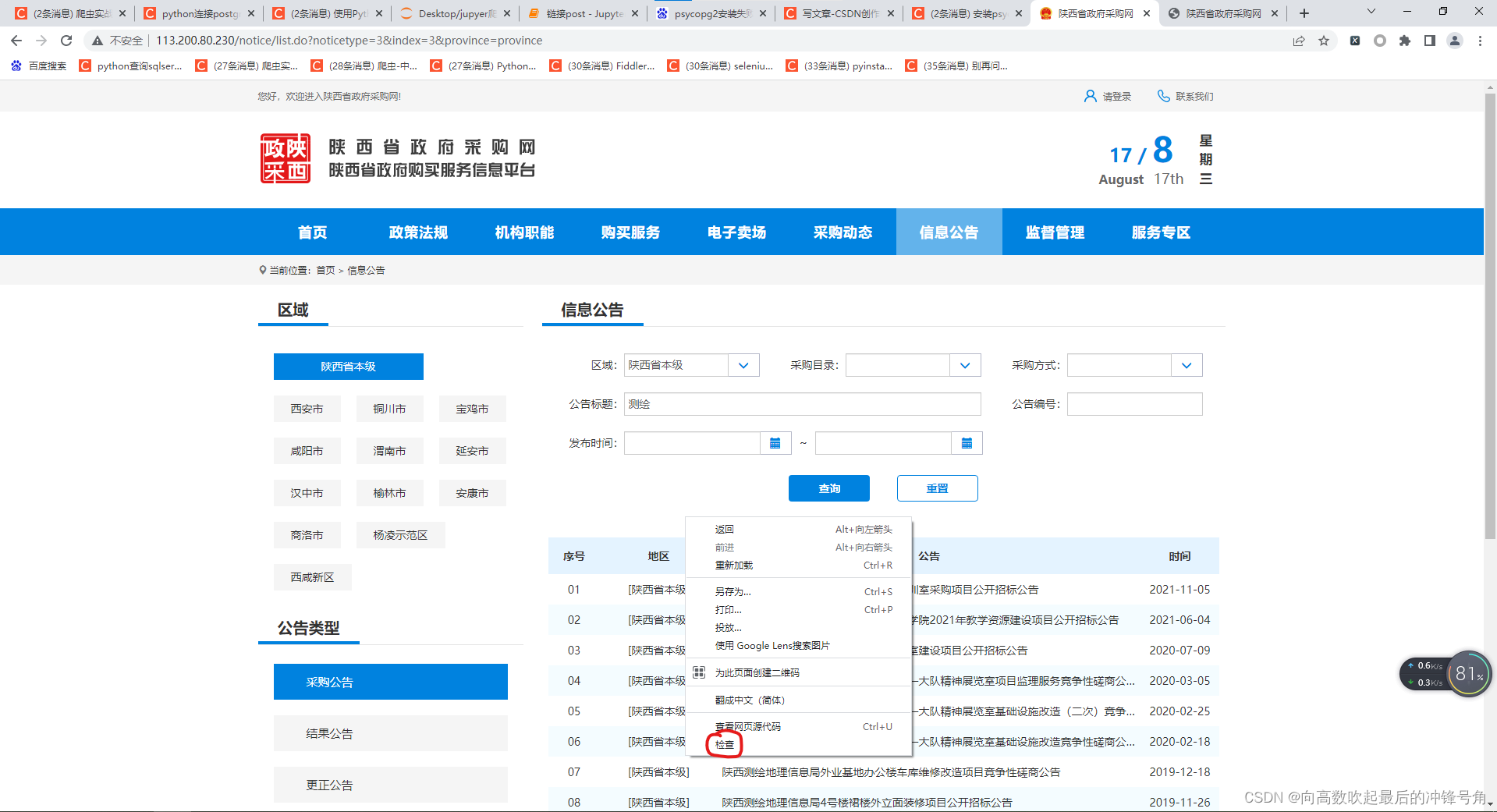
然后得到下图这个界面
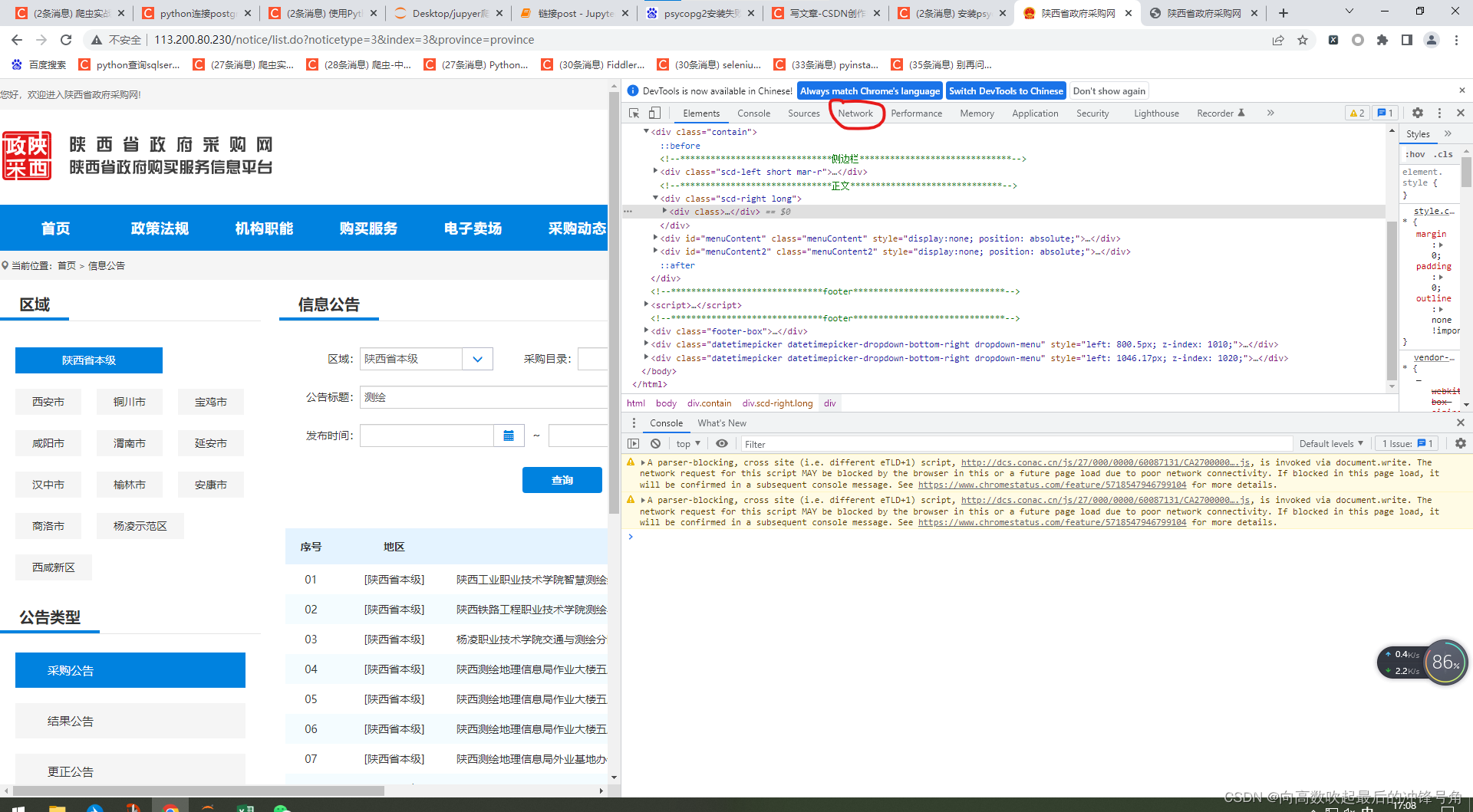
然后选择一下那个红圈圈上的network标签
可以得到
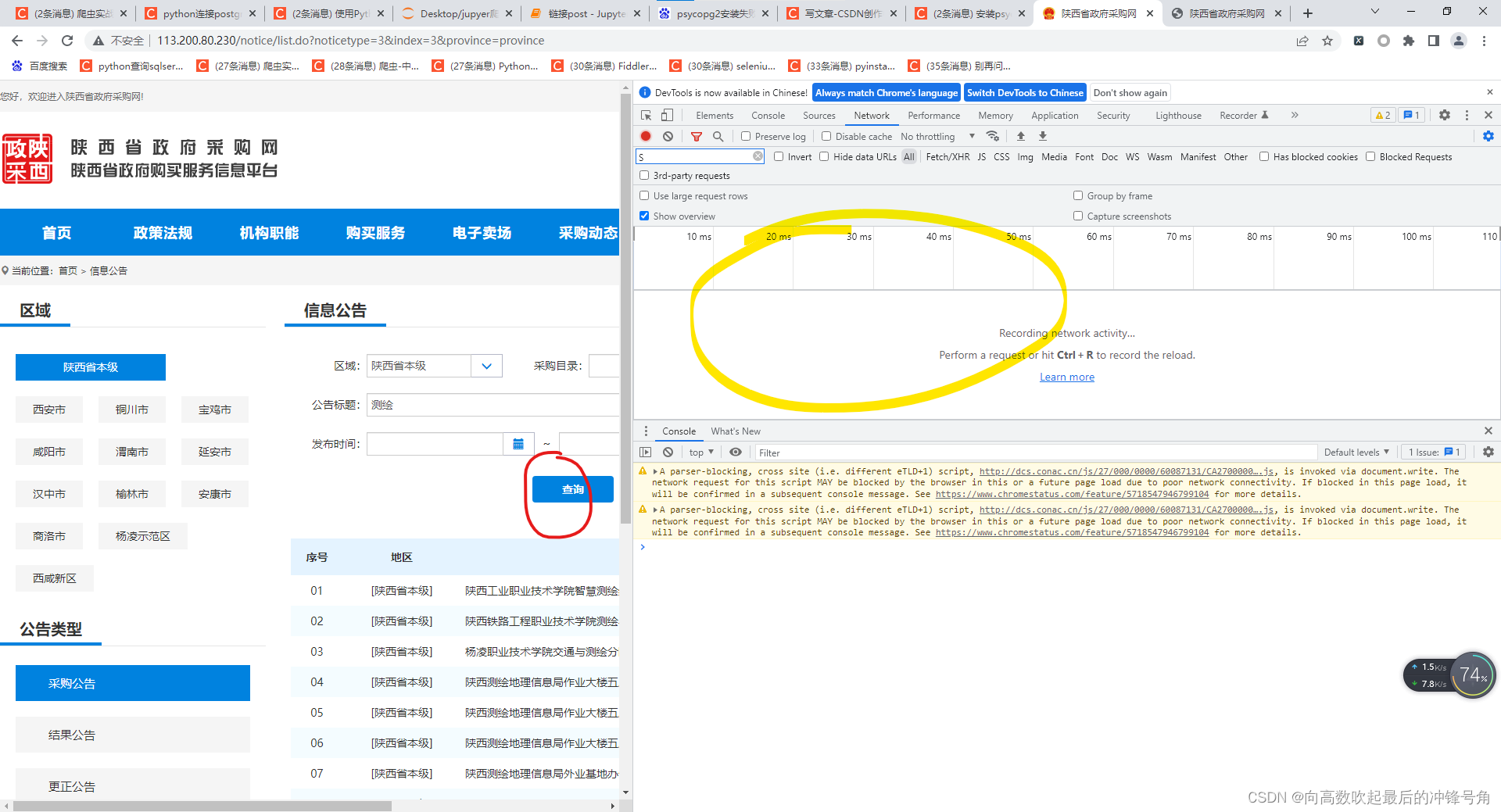
我们可以看到黄圈圈的部分是空的,于是点击红圈圈的部分,把网站刷新一下
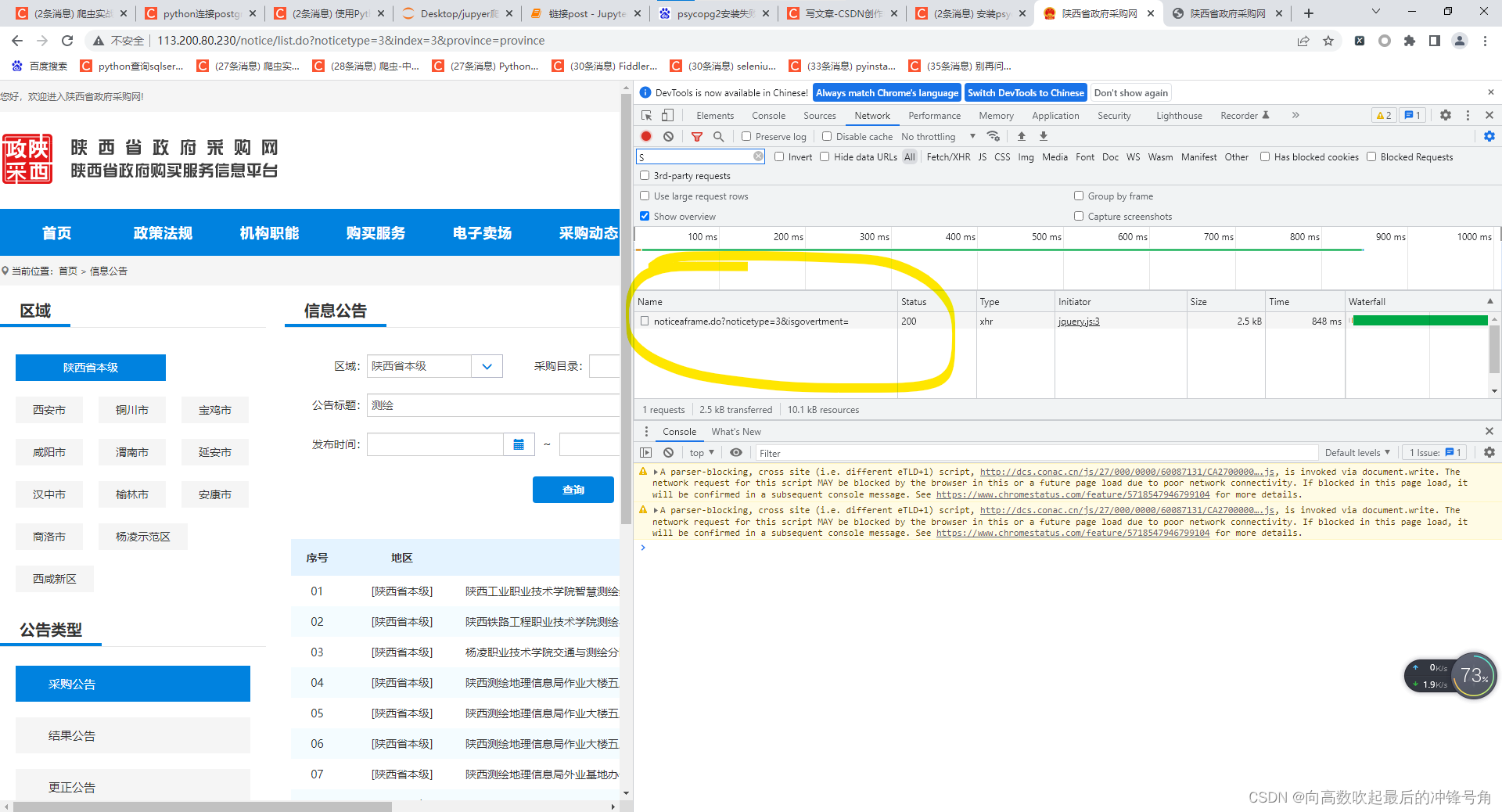
黄色圈圈的部分出现了东西
这个网站点击后这个部分只出现了一条东西,点击即可得到
如果出现了很多东西
点击下面这个链接
(这里准备插一条链接)
鼠标点击一下新出现的东西
发现出来个这
检查这个东西的网址
之前的网址
http://113.200.80.230/notice/list.do?noticetype=3&index=3&province=province
这个东西的网址
http://113.200.80.230/notice/noticeaframe.do?noticetype=3&isgovertment=惊奇的发现不光网页的“形状”变了
网址也变了
这个叫做异步加载
假如你经过如上操作发现网址没有变化
那么那就叫做同步加载
(这里插入一条异步加载和同步加载的解释链接)
然后我们依旧会惊奇的发现
即使网址变了,网页的“形状”也变了
但是我们所需要爬取的信息
依旧在这个网页中
所以
当找到真网址那一刻
就可以使用request请求了
真网址就是我们刚扒拉出来的这个网址
http://113.200.80.230/notice/noticeaframe.do?noticetype=3&isgovertment=request请求需要以下两个库
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为
把这两行代码复制过去运行一下
如果运行报错
那大概率说明你没有装这个库
需要运行
这两行代码
pip install requests
pip install lxml 然后进行耐心的等待
大概五分钟后(或者更短,取决于网速和运气,以及电脑的心情)
再运行这两行代码
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为基本就成功了
如果还是报错
这边建议直接给你的电脑磕一个
或者点击下面这两个链接查看具体情况
request库安装报错点击这个
正确安装requests库才能不报错[windows10/11环境]_Tomycl的博客-CSDN博客_安装requests库报错
lxml库安装报错点击这个
python安装lxml库出错_python安装lxml出错的解决方法_许小晴的博客-CSDN博客
安装好以后
在request之前
我们需要对我们request行为进行一些伪装
来迷惑这个网站
一般迷惑网站的思路
可以从
header cookie refer
三个角度考虑
其中最基础的就是header
(header的作用与意义)
一般普通网站只需要header就能解决
这个网站也是如此
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'}写一行这个代码就能解决
你本机的User-Agent这样找
爬虫向:header的作用与意义以及怎么找![]() http://t.csdn.cn/8DRLp
http://t.csdn.cn/8DRLp
如果需要用到大量header可以通过构建虚假header来解决
(插一条链接)
当然如果直接使用本代码提供的header也是可以的
url2 ="#这里粘贴真网址"
response2 = requests.get(url= url2,headers=headers)
response2 .encoding = 'utf-8'
wb_data_2 = response2.text
html = etree.HTML(wb_data_2)然后
输入
html能打印出东西就证明请求成功