OPT 的大小从 125M 到 175B 参数,达到 GPT-3 量级,并且对所有的实验代码做了完整的开源!OPT-175B 的性能做到了和 GPT-3 相当,但是只需要 1/7 carbon footprint 的训练代价。完整开源的 GPT-3 复刻版
本文介绍来自 Meta AI 的 OPT 模型,它所基于的背景是 GPT-3 这个强大的语言模型。虽然 GPT-3 在 Zero-Shot Learning 和 Few-Shot Learning 方面表现出了卓越的能力,但是训练的耗资巨大,其作者团队也并未将其权重完整开源给社区用户,导致很多相关的研究并不是那么容易进行了。而且 GPT-3 由于规模过大,普通的社区用户受限于算力和资金,想要手动复现一个类似的东西也并不容易。
Open Pretrained Transformers (OPT) 就是为了解决这个问题,它是一整套基于 Transformer Decoder 的大语言模型,对 GPT-3 最大 175B 的模型做了一个复刻版。 OPT 的大小从 125M 到 175B 参数,达到 GPT-3 量级,并且对所有的实验代码做了完整的开源!OPT-175B 的性能做到了和 GPT-3 相当,但是只需要 1/7 carbon footprint 的训练代价。OPT 团队甚至还发布了训练日志 (logbook),详细说明了他们在什么时间段做了什么?为什么这么做?以及做出决策的背景。
论文名称:OPT: Open Pre-trained Transformer Language Models
论文地址:
https://arxiv.org/pdf/2205.01068.pdf
代码链接 (huggingface/transformers):
https://github.com/huggingface/transformers/blob/v4.19.0/src/transformers/models/opt/modeling_opt.py
以 GPT-3 为代表的大语言模型 (Large language models, LLMs) 在海量文本集合上训练,展示出了惊人的涌现能力以及零样本迁移和少样本学习能力。大语言模型还存在很多的问题,比如提高鲁棒性的问题,生成内容存在偏差和毒性的挑战。进一步研究就需要知道模型内部的机制,虽然在某些情况下,公众可以通过付费 API 与这些模型交互,但完整的模型访问权限目前仅限于少数实验室,并未开放给所有的社区用户。这也就限制了很多研究人员研究大语言模型内部的机理以及为什么工作,阻碍了大语言模型的相关研究。
OPT 做到了什么
Open Pretrained Transformers (OPT) 就是为了解决这个问题,它是一整套基于 Transformer Decoder 的大语言模型,对 GPT-3 最大 175B 的模型做了一个复刻版。OPT 的大小从 125M 到 175B 参数,达到 GPT-3 量级,并且对代码做了完整的开源。
OPT 模型力求匹配 GPT-3 类模型的性能和大小,同时也在数据收集和高效训练中应用上一些最新的方法和实践。作者开发这组 OPT 模型的目的是提升社区对于 GPT 类大语言模型的复现能力,促进可复现的研究,以及为领域中带来更多的声音。而且,我们要是想进行 LLM 更深一步的研究,比如 LLM 的风险,有害性,偏见和毒性,而凡此种种研究都必须模型开源之后才可以进行。
OPT 团队不仅发布了 125M 和 66B 参数量大小的 OPT 模型的全部参数,还对学术界的研究人员,隶属于政府、公民社会的人开放了 175B 参数的 OPT 模型,它使用 992 块 80GB 的 A100 GPU 训练,甚至还发布了训练日志 (logbook) 和所基于的代码:
Logbook:
https://github.com/facebookresearch/metaseq/blob/main/projects/OPT/chronicles/OPT175B_Logbook.pdf
Code Base:
https://github.com/facebookresearch/metaseq
OPT-175B 的性能做到了和 GPT-3 相当,但是只需要 1/7 carbon footprint 的训练代价,但其实这个成本也已经不低了。本文作者认为整个 AI 社区,即学术研究人员、民间团体、政策制定者和行业必须共同努力围绕负责任的 AI 制定明确的方针政策,因为这些模型在多种下游语言任务中占据核心地位。语言模型也应该能够被访问到,这样才能进行相关可重复的研究,社区一起共同推动该领域向前发展。
OPT 模型 图1:OPT 模型
图1:OPT 模型
OPT 训练策略
OPT 预训练语料库
预训练语料库包含以下。
RoBERTa:使用 RoBERTa 语料库的 BookCorpus 和 Stories 子集,和更新的 CCNews 版本。
Pile:使用 Pile 语料库的子集 CommonCrawl,DM Mathematics,Project Gutenberg,HackerNews,OpenSubtitles,OpenWebText2,,USPTO 和 Wikipedia。作者去掉了 Pile 的其他子集,因为这样可以减轻训练不稳定的风险。
PushShift.io(https://PushShift.io) Reddit:使用 Pushshift.io(https://pushshift.io/) 语料库的子集 Reddit。
所有语料库之前都被收集或过滤以包含主要英文文本,但通过 CommonCrawl 在语料库中仍然会出现少量非英语数据。作者对预训练语料库中的重复文档进行了删除操作,发现在 Pile 内部包含许多重复的文档,并建议未来的研究人员对该数据集进行额外的重复数据删除处理。
Tokenizer 使用 GPT-2 byte level BPE tokenizer,最终的训练数据量包含约 180B tokens。
OPT 训练过程
这里作者描述了他们在训练过程中遇到的问题,主要是以下3个。
1. 硬件故障: OPT 大模型使用了 992 块 80GB 的 A100 GPU 作训练,那这么多的 GPU 就不可避免地会出现一些故障,尤其是训练 OPT-175B 模型时。硬件故障导致至少 35 次手动重启,在手动重启期间,暂停训练运行,排查问题,然后加载上一个 Checkpoint 的参数继续训练。作者估计一共重启了大概 70+ 次。
2. 损失函数不收敛: 当发现损失函数变得不再收敛,即出现训崩了的情况时,OPT 作者首先降低学习率,然后加载更早的 Checkpoint 的参数重启训练。实际的学习率如下图2所示。在训练的早期,作者还注意到将梯度裁剪从 1.0 降低到 0.3 有助于训练的稳定性。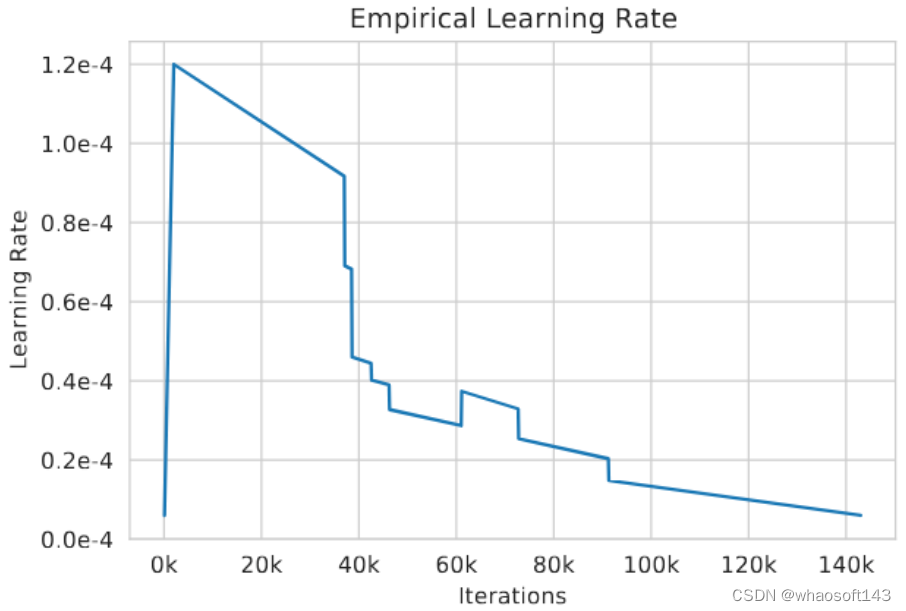 图2:实际的学习率
图2:实际的学习率
3. 其他训练策略: 作者还尝试了其他一些训练策略,比如优化器使用原始的 SGD (很快把参数优化到平台期,所以又恢复到 AdamW),重置 dynamic loss scalar,并切换到较新的 Megatron 版本。
OPT 评测结果
Prompting & Few-Shot 实验结果
OPT 在16个数据集上做了评测:HellaSwag, StoryCloze, PIQA, ARC Easy and Challenge, OpenBookQA , WinoGrad, WinoGrande , 以及 SuperGLUE。
Zero-Shot 结果如下图3所示。总体而言,OPT 的平均性能遵循 GPT-3 的趋势。对于比较的 10 个任务,OPT 的性能大致匹配 GPT-3,并且在 3 个任务 (ARC Challenge 和 MultiRC) 中表现不佳。在 WIC 中,OPT 模型总是优于GPT-3 模型。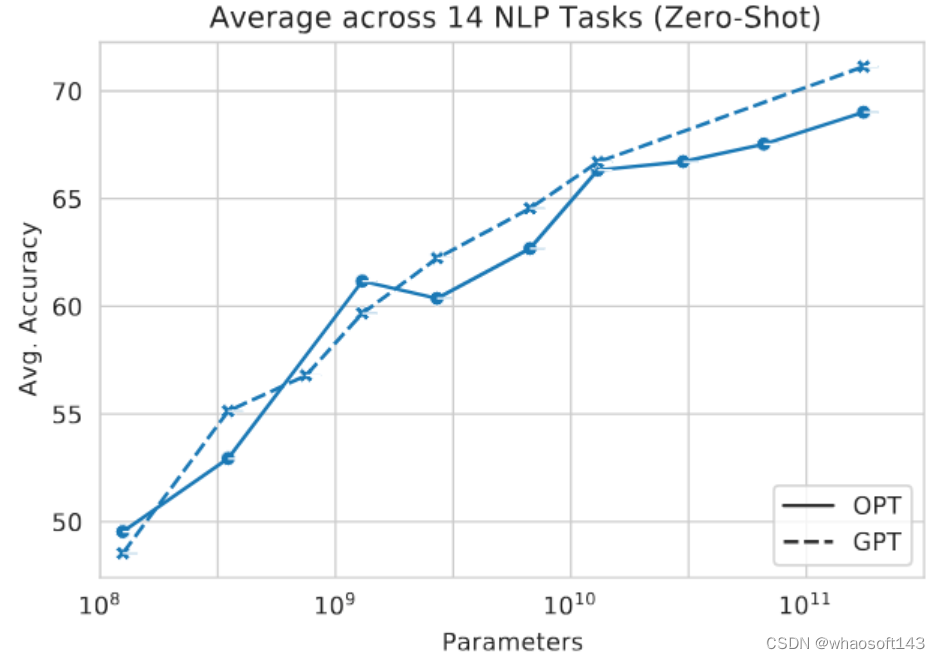 图3:Zero-Shot 结果
图3:Zero-Shot 结果
Multi-Shot 结果如下图4所示,OPT 模型的表现类似于 GPT-3 模型,不论是 Zero-Shot 还是 One-Shot 的结果,OPT 均稍稍落后于 GPT-3 模型,但性能在很大程度上取决于每个任务。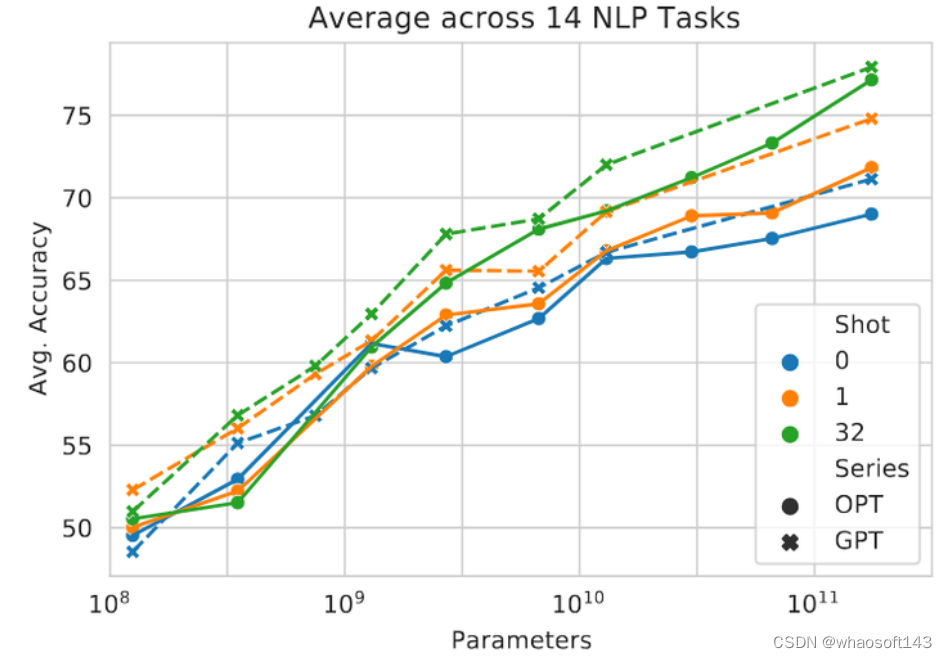 图4:Multi-shot 结果
图4:Multi-shot 结果
对话实验结果
几个评测的数据集:ConvAI2,Wizard of Wikipedia,Empathetic Dialogues,Blended Skill Talk 和 Wizard of Internet。对比的模型包括了经过微调的 BlenderBot 1,以及它的预训练对标 Reddit 2.7B,微调的 R2C2 BlenderBot。评测的手段是 Perplexity and Unigram F1 (UF1)。
实验结果如下图5所示,可以看到 OPT-175B 在所有任务上都显着优于无监督 Reddit 2.7B 模型,与完全监督的 BlenderBot 1 模型相比也具有竞争力,尤其是在 ConvAI2 数据集。在 Wizard-of-Internet 数据集上,OPT-175B 也取得了最低的 Perplexity。 whaosoft aiot http://143ai.com  图5:对话实验结果
图5:对话实验结果
OPT 的局限性
作者观察到 OPT-175B 也同样有着其他 LLM 所包含的一些局限性。
比如,作者发现 OPT 当指令是声明性说明或填空疑问句时效果不佳,当使用此类指令提示时,模型往往会输出一些 "从此类指令开始的对话的模拟",而不是 "真正要回答的答案"。针对这个问题,InstructGPT 给出了一些解决的方案。OPT-175B 生成的结果也往往是重复的,很容易陷入循环中。未来的工作可能希望结合更现代的策略来减少重复和改进生成内容的多样性。
与其他的 LLM 类似,作者发现 OPT 也会有一些不正确的回复,这点在一些信息准确性很重要的应用里面是有害的。作者相信 OPT-175B 如果未来融入一些检索增强 (retrieval-augmentation) 的技术手段也会获益。
作者还发现即使是给一些相对无害的提示,OPT-175B 还是具有很高的生成有毒语言和生成带有有害刻板印象内容的倾向。但鉴于 OPT 的主要目标作为 GPT-3 的复刻版,因此放松了这方面的要求。
总体而言,作者仍然觉得这项技术对于商业部署来说是过早的。
首先是训练数据这块,他们认为应该对训练数据提供更多的审查,以便更合理地使用数据。当前的做法是给模型喂入尽可能多的数据,有多少给多少。
其次是评测这块,虽然现在的评测比较全面,但作者觉得应该具有更精简的评测方法,以确保评测结果的可复现。而且,Prompt 的设置和 Few-Shot 的数量也会影响模型的表现,作者希望 OPT 模型的发布能让更多的许多研究人员处理这些重要问题。