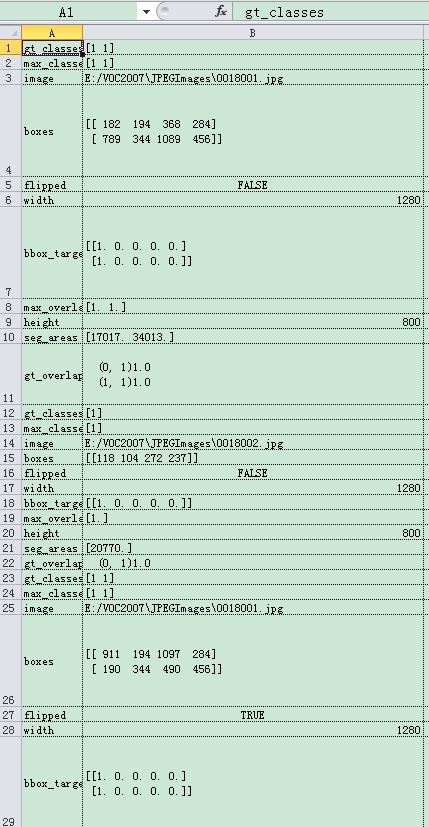
faster rcnn对数据进行训练时,Solverwrapper初始化时,self.bbox_means, self.bbox_stds= rdl_roidb.add_bbox_regression_targets(roidb)中的roidb归一化在训练样本很大时特别耗时,所以采用保存后读取文件的方式减少耗时,以保证训练中断后重新训练时,可以减少归一化操作的耗时。
import numpy as np
import csv
imgport re
------保存roidb到csv文件中-------------
def save_file(path,data):
length = len(data)
csvFile3 = open(path,'wb')
writer2 = csv.writer(csvFile3)
for i in range(length):
for key in data[i]:
writer2.writerow([key, data[i][key]])
csvFile3.close()
-------从csv文件中读取roidb数据------------
def get_train_roidb(path,num_train,num_cls):
print(path)
csvFile = open(path, 'r')
reader = csv.reader(csvFile)
data = []
outputunflipped = []
outputflipped = []
for item in reader:
data.append(item)
up = num_train*11
for k in range(num_train):
t = k*11
print('k is:',k)
first_elem = data[t][1]
gt_first_elem = first_elem.split('[')[1].split(']')[0]
gt_first_elem_list = [x for x in gt_first_elem if x != ' ']
#####计算有几个目标框#########
list_str = []
str_temp = ''
for x in gt_first_elem_list:
if x == ' ':
if str_temp != '':
list_str.append(str_temp)
str_temp = ''
continue
str_temp = ''
continue
str_temp += x
list_str.append(str_temp)
len_box = len(len_list)
######################
#list_str = re.aplit(r'[ ]+',gt_first_elem_list.split())
# len_box = len(len_list)
dictz = {}
for q in range(11):
po = data[t+q][1]
print('len of po is:',len(po))
print(po)
kp = len(list(filter(lambda x:x.find('[') !=-1,po)))
tt = []
if kp == 0:
if q ==10:
if len_box ==1:
gt = po.split('\t')
gt_list = [x for x in gt[0] if x != ' ']
row = []
row.append(int(gt_list[1]))
col = []
col.append(int(gt_list[3]))
ddata = []
ddata.append(float(gt[1]))
matrix = csr_matrix((ddata,(row,col)),shape = (len_box,num_cls),dtype = np.float32)
dictz[data[t+q][0]] = matrix
else:
tmp = po.split('\n')
row = []
col = []
ddata = []
for num in range(len(tmp)):
gt = tmp[num].split('\t')
gt_list = [x for x in gt[0] if x != ' ']
row.append(int(gt_list[1]))
col.append(int(gt_list[3]))
ddata.append(float(gt[1]))
matrix = csr_matrix((ddata,(row,col)),shape = (len_box,num_cls),dtype = np.float32)
dictz[data[t+q][0]] = matrix
elif q == 2:
dictz[data[t+q][0]] = po
elif q==5 or q ==8 :
dictz[data[t+q][0]] = int(po)
else:
dictz[data[t+q][0]] = po == 'True'
elif kp==1:
if len_box ==1:
gt = po.split('[')[1].split(']')[0]
if q == 0 :
tt.append(int(gt))
dictz[data[t+q][0]] = np.array(tt)
elif q==1:
tt.append(int(gt))
dictz[data[t+q][0]] = np.array(tt,dtype = np.int64)
elif q==7 or q==9:
tt.append(float(gt))
dictz[data[t+q][0]] = np.array(tt,dtype = np.float32)
else:
gt = po.split('[')[1].split(']')[0].split(' ')
gt_list = [x for x in gt if x != '']
if q == 0 :
for tr in range(len(gt_list)):
tt.append(int(gt_list[tr]))
dictz[data[t+q][0]] = np.array(tt)
elif q==1:
for tr in range(len(gt_list)):
tt.append(int(gt_list[tr]))
dictz[data[t+q][0]] = np.array(tt,dtype = np.int64)
elif q==7 or q==9:
for tr in range(len(gt_list)):
tt.append(float(gt_list[tr]))
dictz[data[t+q][0]] = np.array(tt,dtype = np.float32)
else:
if len_box == 1:
gt = po.split('[')[2].split(']')[0].split(' ')#one box
#print('len_box =1 kp>1 gt is:',gt)
gt_list = [x for x in gt if x != '']
wt = []
if type(eval(gt_list[0]))==int :
for tr in range(len(gt_list)):
if gt_list[tr] != '':
tt.append(int(gt_list[tr]))
wt.append(tt)
dictz[data[t+q][0]] = np.array(wt,dtype = np.uint16)
elif type(eval(gt_list[0]))==float:
for tr in range(len(gt_list)):
if gt_list[tr] != '':
tt.append(float(gt_list[tr]))
wt.append(tt)
dictz[data[t+q][0]] = np.array(wt,dtype = np.float32)
else:
tmp = po.split('\n')
gt_tmp = tmp[0].split('[')[2].split(']')[0].split(' ')#one box
gt_tmp_list = [x for x in gt_tmp if x != '']
ut = []
for num in range(len(tmp)):
if num == 0:
gt = tmp[num].split('[')[2].split(']')[0].split(' ')#one box
gt_list = [x for x in gt if x != '']
elif num == len_box-1:
gt = tmp[num].split('[')[1].split(']')[0].split(' ')#one box
gt_list = [x for x in gt if x != '']
else:
gt = tmp[num].split('[')[1].split(']')[0].split(' ')#one box
gt_list = [x for x in gt if x != '']
if type(eval(gt_list[0]))==int :
for tr in range(len(gt_list)):
if gt_list[tr] != '':
ut.append(int(gt_list[tr]))
elif type(eval(gt_list[0]))==float:
for tr in range(len(gt_list)):
if gt_list[tr] != '':
ut.append(float(gt_list[tr]))
if type(eval(gt_tmp_list[0]))==int:
dictz[data[t+q][0]] = np.array(ut,dtype = np.uint16).reshape((len_box,-1))
else:
dictz[data[t+q][0]] = np.array(ut,dtype = np.float32).reshape((len_box,-1))
u = up+k*10
print('u is:',u)
dictf = {}
for q in range(10):
print('q is:',q)
po = data[u+q][1]
kp = len(list(filter(lambda x:x.find('[') !=-1,po)))
print('po is:',po)
print('kp is:',kp)
tt = []
if kp == 0:
if q ==9:
if len_box == 1:
gt = po.split('\t')
gt_list = [x for x in gt[0] if x != ' ']
row = []
row.append(int(gt_list[1]))
col = []
col.append(int(gt_list[3]))
sdata = []
sdata.append(float(gt[1]))
matrix = csr_matrix((sdata,(row,col)),shape = (len_box,num_cls),dtype = np.float32)
dictf[data[u+q][0]] = matrix
else:
tmp = po.split('\n')
row = []
col = []
ddata = []
for num in range(len(tmp)):
gt = tmp[num].split('\t')
gt_list = [x for x in gt[0] if x != ' ']
row.append(int(gt_list[1]))
col.append(int(gt_list[3]))
ddata.append(float(gt[1]))
matrix = csr_matrix((ddata,(row,col)),shape = (len_box,num_cls),dtype = np.float32)
dictf[data[u+q][0]] = matrix
elif q == 2:
dictf[data[u+q][0]] = po
elif q==5 or q ==8 :
dictf[data[u+q][0]] = int(po)
else:
dictf[data[u+q][0]] = po == 'True'
elif kp==1:
if len_box ==1:
gt = po.split('[')[1].split(']')[0]
# gt_list = [x for x in gt if x != ' ']
#print('len_box = 1 kp =1 gt is:',gt)
if q == 0 :
tt.append(int(gt))
dictf[data[u+q][0]] = np.array(tt)
elif q==1:
tt.append(int(gt))
dictf[data[u+q][0]] = np.array(tt,dtype = np.int64)
elif q==7:
tt.append(float(gt))
dictf[data[u+q][0]] = np.array(tt,dtype = np.float32)
else:
gt = po.split('[')[1].split(']')[0].split(' ')
print('kp == 1 gt is:',gt)
if q == 0 :
for tr in range(len(gt)):
tt.append(int(gt[tr]))
dictf[data[u+q][0]] = np.array(tt)
elif q==1:
for tr in range(len(gt)):
tt.append(int(gt[tr]))
dictf[data[u+q][0]] = np.array(tt,dtype = np.int64)
elif q==7:
for tr in range(len(gt)):
tt.append(float(gt[tr]))
dictf[data[u+q][0]] = np.array(tt,dtype = np.float32)
else:
if len_box == 1:
gt = po.split('[')[2].split(']')[0].split(' ')
gt_list = [x for x in gt if x != '']
wt = []
if type(eval(gt_list[0]))==int :
for tr in range(len(gt_list)):
if gt_list[tr] != '':
tt.append(int(gt_list[tr]))
wt.append(tt)
dictf[data[u+q][0]] = np.array(wt,dtype = np.uint16)
elif type(eval(gt_list[0]))==float:
for tr in range(len(gt_list)):
if gt_list[tr] != '':
tt.append(float(gt_list[tr]))
wt.append(tt)
dictf[data[u+q][0]] = np.array(wt,dtype = np.float32)
else:
tmp = po.split('\n')
gt_tmp = tmp[0].split('[')[2].split(']')[0].split(' ')
gt_tmp_list = [x for x in gt_tmp if x != '']
ut = []
for num in range(len(tmp)):
if num == 0:
gt = tmp[num].split('[')[2].split(']')[0].split(' ')
gt_list = [x for x in gt if x != '']
elif num == len_box-1:
gt = tmp[num].split('[')[1].split(']')[0].split(' ')
gt_list = [x for x in gt if x != '']
else:
gt = tmp[num].split('[')[1].split(']')[0].split(' ')
gt_list = [x for x in gt if x != '']
if type(eval(gt_list[0]))==int :
for tr in range(len(gt_list)):
if gt_list[tr] != '':
ut.append(int(gt_list[tr]))
elif type(eval(gt_list[0]))==float:
for tr in range(len(gt_list)):
if gt_list[tr] != '':
ut.append(float(gt_list[tr]))
if type(eval(gt_tmp_list[0]))==int:
dictf[data[u+q][0]] = np.array(ut,dtype = np.uint16).reshape((len_box,-1))
else:
dictf[data[u+q][0]] = np.array(ut,dtype = np.float32).reshape((len_box,-1))
outputunflipped.append(dictz)
outputflipped.append(dictf)
output = outputunflipped + outputflipped
return output
if __name__ == '__main__':
path = 'E:/VOC2007/card/normdata.csv'
csvFile = open(path, 'r')
reader = csv.reader(csvFile)
row = np.array(list(reader)).shape[0])
num_train = row/21
num_cls = 12#训练的类别数+1
output = get_train_roidb(path,num_train,num_cls)
faster rcnn中roidb数据为:
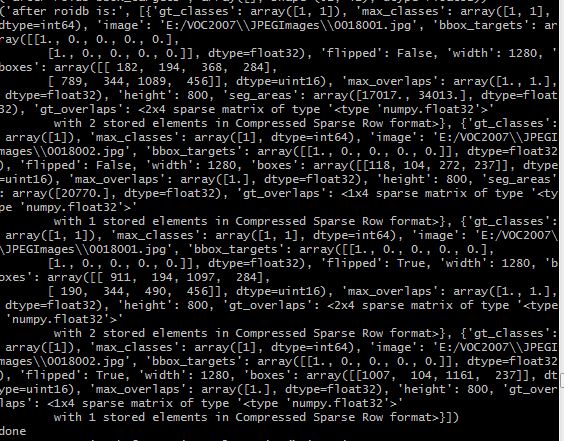
写入csv后,保存形式为: