参考源代码GitHub:
Deep-Dream/resnet.py at master · L1aoXingyu/Deep-Dream · GitHub
但是如果运行里面的代码的话,会报错:
TypeError: __init__() takes from 3 to 5 positional arguments but 9 were given所以改了一下,让它能运行了。(其实就是重写了ResNet50网络结构,让layers.append(block(self.inplanes, planes, stride, downsample)),只包含四项,而非九项)
uilt
from PIL import Image
# 使图片大小保持一致,等比缩放
def keep_image_size_open(path, size=(256, 256)):
img = Image.open(path) # 读取图片
temp = max(img.size) # 取最长边
mask = Image.new('RGB', (temp, temp), (0, 0, 0)) # mask掩码,全黑
mask.paste(img, (0, 0)) # 从原点开始粘贴
mask = mask.resize(size)
return mask
ResNet
import torch
from torch import nn
from torchvision import models
import torch.utils.model_zoo as model_zoo
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
class CustomResNet(ResNet): ##models.resnet.ResNet):
def forward(self, x, end_layer):
"""
end_layer range from 1 to 4
"""
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
layers = [self.layer1, self.layer2, self.layer3, self.layer4]
for i in range(end_layer):
x = layers[i](x)
return x
def resnet50(pretrained=False, **kwargs):
model = CustomResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
if __name__ == '__main__':
model = resnet50(pretrained=False)deepdream
import numpy as np
import torch
from util import showtensor
import scipy.ndimage as nd
from torch.autograd import Variable
def objective_L2(dst, guide_features):
return dst.data
def make_step(img, model, control=None, distance=objective_L2):
mean = np.array([0.485, 0.456, 0.406]).reshape([3, 1, 1])
std = np.array([0.229, 0.224, 0.225]).reshape([3, 1, 1])
learning_rate = 2e-2
max_jitter = 32
num_iterations = 20
show_every = 10
end_layer = 3
guide_features = control
for i in range(num_iterations):
shift_x, shift_y = np.random.randint(-max_jitter, max_jitter + 1, 2)
img = np.roll(np.roll(img, shift_x, -1), shift_y, -2)
# apply jitter shift
model.zero_grad()
img_tensor = torch.Tensor(img)
if torch.cuda.is_available():
img_variable = Variable(img_tensor.cuda(), requires_grad=True)
else:
img_variable = Variable(img_tensor, requires_grad=True)
act_value = model.forward(img_variable, end_layer)
diff_out = distance(act_value, guide_features)
act_value.backward(diff_out)
ratio = np.abs(img_variable.grad.data.cpu().numpy()).mean()
learning_rate_use = learning_rate / ratio
img_variable.data.add_(img_variable.grad.data * learning_rate_use)
img_variable = img_variable.clamp(0, 255)
img = img_variable.data.cpu().numpy() # b, c, h, w
img = np.roll(np.roll(img, -shift_x, -1), -shift_y, -2)
img[0, :, :, :] = np.clip(img[0, :, :, :], -mean / std,
(1 - mean) / std)
if i == 0 or (i + 1) % show_every == 0:
showtensor(img)
return img
def dream(model,
base_img,
octave_n=6,
octave_scale=1.4,
control=None,
distance=objective_L2):
octaves = [base_img]
for i in range(octave_n - 1):
octaves.append(
nd.zoom(
octaves[-1], (1, 1, 1.0 / octave_scale, 1.0 / octave_scale),
order=1))
detail = np.zeros_like(octaves[-1])
for octave, octave_base in enumerate(octaves[::-1]):
h, w = octave_base.shape[-2:]
if octave > 0:
h1, w1 = detail.shape[-2:]
detail = nd.zoom(
detail, (1, 1, 1.0 * h / h1, 1.0 * w / w1), order=1)
input_oct = octave_base + detail
print(input_oct.shape)
out = make_step(input_oct, model, control, distance=distance)
detail = out - octave_base
return outtrain
## 定义一些参数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
])
input_img = Image.open('./sky.jpg')
# input_img = cv2.imread('./cat.png')
print(input_img.size)
input_tensor = img_transform(input_img).unsqueeze(0) ## 输出的是【1,3,224,224】
input_np = input_tensor.numpy()
## 加载模型
model = resnet50(pretrained=True).to(device) ## True加载参数
for param in model.parameters():
param.requires_grad = False
a = dream(model, input_np)
# a = a.clamp(0, 1)
# print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
# print(a.shape)
decode_img = np.array((a))
decode_img = decode_img.squeeze(0)
decode_img = decode_img.transpose((1, 2, 0))
print(decode_img)
plt.imshow(decode_img) # 生成图片 3
plt.show()效果图
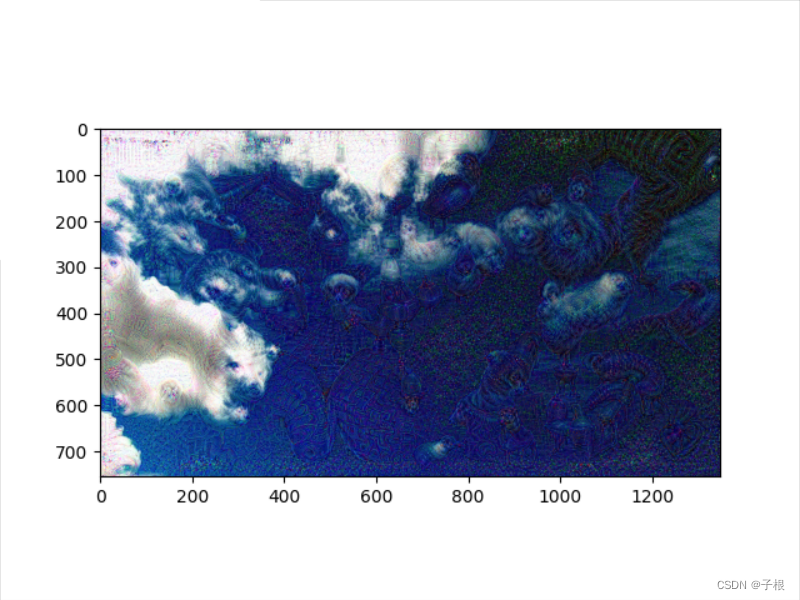
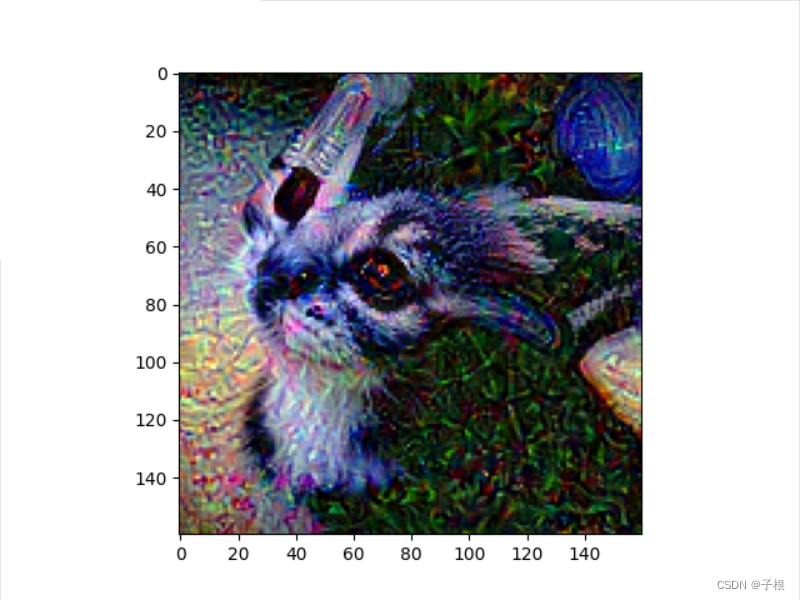
源图:

