语音合成中的Lora,插件式speaker开发,语音克隆的未来~
论文链接:
https://arxiv.org/abs/2211.00585
论文标题:
Adapter-Based Extension of Multi-Speaker Text-to-Speech Model for New Speakers
发表时间:
2022年11月1日
文章贡献:
First, we pre-train a base multi-speaker TTS model on a large and diverse TTS dataset. To extend model for new speakers, we add a few adapters – small modules to the base model. We used vanilla adapter [15], unified adapters [16, 17, 18], or BitFit [19]. Then, we freeze the pre-trained model and fine-tune only adapters on new speaker data.
• We propose a new adapter-based framework for efficient tuning of TTS model for new speakers without forgetting previously learned speakers.
提出基于适配器框架的TTS模型,能通过微调实现新的发音人,而且不会遗忘模型中已存在的发音人。
• We validate our design through comprehensive ablation study across different types of adapters modules, amounts of training data, and recording conditions.
通过综合烧蚀验证方案:不同类型适配器模块、大量训练数据、甚至录音条件。
• We demonstrate that adapter-based TTS tuning performs similarly to full fine-tuning while demanding significantly less compute and data.
证明了基于适配器的TTS调优与全模型微调有同样的质量,同时所需的计算和数据要少得多。
核心架构:

The proposed pipeline for adaptation of multi-speaker TTS model for new speakers.
(a) Pre-train a multi-speaker FastPitch model.
多发音人预训练模型
(b) Freeze weights of pre-trained FastPitch model and add adapter modules.
冻结预训练模型权重,添加adapter
(c) Only the adapters are fine-tuned for new speaker.
针对新发音人,微调时只训练adapter
(d) Inference by sharing the same model and plugging the lightweight, speaker-specific module.
推理时,在预训练模型中插入发音人专有的adapter权重:插件式发音人
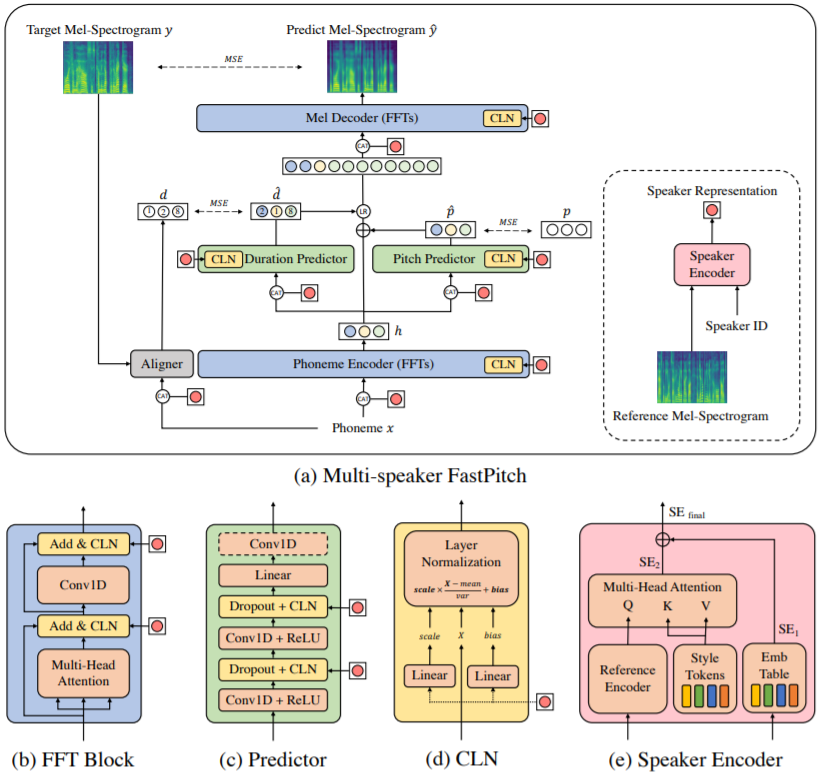
Architecture of proposed multi-speaker FastPitch.It is composed of phoneme encoder, mel decoder, duration and pitch predictor, aligner, and speaker encoder. We control speaker identity by using conditional layer normalization (CLN) and concatenating inputs with speaker representation.

Illustration of parameter-efficient tuning modules in transformer architecture. LoRA and Prefix Tuning are only used in FFTs while Adapter and BitFit can be applied to any components in FastPitch.
代码实现(部分展示):
https://github.com/NVIDIA/NeMo/pull/6416
Adds FastPitch pre-training with CLNs and fine-tuning with adapters.
Changelog
-
Adds multi-speaker FastPitch pre-training with Conditional Layer Normalization
-
nemo/collections/tts/modules/fastpitch.py
-
nemo/collections/tts/modules/transformer.py
-
nemo/collections/tts/modules/submodules.py
-
Add adapter modules for FastPitch fine-tuning
-
nemo/collections/tts/models/fastpitch.py
-
nemo/collections/tts/modules/fastpitch.py
-
nemo/collections/tts/modules/transformer.py
-
nemo/collections/tts/modules/aligner.py
-
nemo/collections/tts/parts/mixins/__init__.py
-
nemo/collections/tts/parts/mixins/fastpitch_adapter_mixins.py
-
Add config and fine-tuning python script
-
examples/tts/conf/fastpitch_speaker_adaptation.yaml
-
examples/tts/fastpitch_finetune_adapters.py
-
Fix aligner
nan loss bug
-
nemo/collections/tts/losses/aligner_loss.py
nemo/collections/tts/modules/adapters.py
# Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.from typing import List, Optionalfrom omegaconf import DictConfigfrom nemo.collections.asr.parts.utils import adapter_utilsfrom nemo.collections.tts.modules.aligner import AlignmentEncoderfrom nemo.collections.tts.modules.fastpitch import TemporalPredictorfrom nemo.collections.tts.modules.transformer import FFTransformerDecoder, FFTransformerEncoderfrom nemo.core.classes import adapter_mixinsclass FFTransformerDecoderAdapter(FFTransformerDecoder, adapter_mixins.AdapterModuleMixin):""" Inherit from FFTransformerDecoder and add support for adapter"""def add_adapter(self, name: str, cfg: dict):cfg = self._update_adapter_cfg_input_dim(cfg)for fft_layer in self.layers: # type: adapter_mixins.AdapterModuleMixinfft_layer.add_adapter(name, cfg)def is_adapter_available(self) -> bool:return any([FFT_layer.is_adapter_available() for FFT_layer in self.layers])def set_enabled_adapters(self, name: Optional[str] = None, enabled: bool = True):for FFT_layer in self.layers: # type: adapter_mixins.AdapterModuleMixinFFT_layer.set_enabled_adapters(name=name, enabled=enabled)def get_enabled_adapters(self) -> List[str]:names = set([])for FFT_layer in self.layers: # type: adapter_mixins.AdapterModuleMixinnames.update(FFT_layer.get_enabled_adapters())names = sorted(list(names))return namesdef _update_adapter_cfg_input_dim(self, cfg: DictConfig):cfg = adapter_utils.update_adapter_cfg_input_dim(self, cfg, module_dim=self.d_model)return cfgclass FFTransformerEncoderAdapter(FFTransformerDecoderAdapter, FFTransformerEncoder, adapter_mixins.AdapterModuleMixin):""" Inherit from FFTransformerEncoder and add support for adapter"""passclass AlignmentEncoderAdapter(AlignmentEncoder, adapter_mixins.AdapterModuleMixin):""" Inherit from AlignmentEncoder and add support for adapter"""def add_adapter(self, name: str, cfg: dict):for i, conv_layer in enumerate(self.key_proj):if i % 2 == 0:cfg = self._update_adapter_cfg_input_dim(cfg, conv_layer.conv.out_channels)conv_layer.add_adapter(name, cfg)for i, conv_layer in enumerate(self.query_proj):if i % 2 == 0:cfg = self._update_adapter_cfg_input_dim(cfg, conv_layer.conv.out_channels)conv_layer.add_adapter(name, cfg)def is_adapter_available(self) -> bool:return any([conv_layer.is_adapter_available() for i, conv_layer in enumerate(self.key_proj) if i % 2 == 0]+ [conv_layer.is_adapter_available() for i, conv_layer in enumerate(self.query_proj) if i % 2 == 0])def set_enabled_adapters(self, name: Optional[str] = None, enabled: bool = True):for i, conv_layer in enumerate(self.key_proj):if i % 2 == 0:conv_layer.set_enabled_adapters(name=name, enabled=enabled)for i, conv_layer in enumerate(self.query_proj):if i % 2 == 0:conv_layer.set_enabled_adapters(name=name, enabled=enabled)def get_enabled_adapters(self) -> List[str]:names = set([])for i, conv_layer in enumerate(self.key_proj):if i % 2 == 0:names.update(conv_layer.get_enabled_adapters())for i, conv_layer in enumerate(self.query_proj):if i % 2 == 0:names.update(conv_layer.get_enabled_adapters())names = sorted(list(names))return namesdef _update_adapter_cfg_input_dim(self, cfg: DictConfig, module_dim: int):cfg = adapter_utils.update_adapter_cfg_input_dim(self, cfg, module_dim=module_dim)return cfgclass TemporalPredictorAdapter(TemporalPredictor, adapter_mixins.AdapterModuleMixin):""" Inherit from TemporalPredictor and add support for adapter"""def add_adapter(self, name: str, cfg: dict):cfg = self._update_adapter_cfg_input_dim(cfg)for conv_layer in self.layers: # type: adapter_mixins.AdapterModuleMixinconv_layer.add_adapter(name, cfg)def is_adapter_available(self) -> bool:return any([conv_layer.is_adapter_available() for conv_layer in self.layers])def set_enabled_adapters(self, name: Optional[str] = None, enabled: bool = True):for conv_layer in self.layers: # type: adapter_mixins.AdapterModuleMixinconv_layer.set_enabled_adapters(name=name, enabled=enabled)def get_enabled_adapters(self) -> List[str]:names = set([])for conv_layer in self.layers: # type: adapter_mixins.AdapterModuleMixinnames.update(conv_layer.get_enabled_adapters())names = sorted(list(names))return namesdef _update_adapter_cfg_input_dim(self, cfg: DictConfig):cfg = adapter_utils.update_adapter_cfg_input_dim(self, cfg, module_dim=self.filter_size)return cfg"""Register any additional information"""if adapter_mixins.get_registered_adapter(FFTransformerEncoder) is None:adapter_mixins.register_adapter(base_class=FFTransformerEncoder, adapter_class=FFTransformerEncoderAdapterif adapter_mixins.get_registered_adapter(FFTransformerDecoder) is None:adapter_mixins.register_adapter(base_class=FFTransformerDecoder, adapter_class=FFTransformerDecoderAdapter)if adapter_mixins.get_registered_adapter(AlignmentEncoder) is None:adapter_mixins.register_adapter(base_class=AlignmentEncoder, adapter_class=AlignmentEncoderAdapter)if adapter_mixins.get_registered_adapter(TemporalPredictor) is None:adapter_mixins.register_adapter(base_class=TemporalPredictor, adapter_class=TemporalPredictorAdapter)