目录
3. 使用LOAD DATA INFILE(OUTFILE)导入导出
4. 使用LOAD DATA INFILE(OUTFILE)导入导出注意事项
一、视图
1. 什么是视图
视图 (view) 也被称作虚表,即虚拟的表,是一组数据的逻辑表示,其本质是对应于一条SELECT语句,结果集被赋予一个名字,即视图名字。
视图本身并不包含任何数据,它只包含映射到基表的一个查询语句,当基表数据发生变化,视图数据也随之变化。使用视图查询数据时,数据库会从真实表中取出对应的数据。因此,视图中的数据是依赖于真实表中的数据的。一旦真实表中的数据发生改变,显示在视图中的数据也会发生改变。
作用:
视图可以从原有的表上选取对用户有用的信息,那些对用户没用,或者用户没有权限了解的信息,都可以直接屏蔽掉,作用类似于筛选。这样做既使应用简单化,也保证了系统的安全。
2. 视图与数据表的区别
-
存储方式:视图是数据的窗口,而表是内容。 数据表是实际存储数据的物理结构,而视图只是一个查询的结果集,并不实际存储数据,其结构和数据是建立在对数据中真实表的查询基础上的。
-
数据更新:对于数据表,我们可以直接对其进行插入、更新和删除等操作来修改底层数据。而对于视图,一般情况下是只读的,不能直接对其进行修改。但是在某些情况下,也可以通过视图进行更新操作,这种操作被称为可更新视图(Updatable View)。
-
结构定义:数据表具有明确的结构定义,包括列名、数据类型、约束条件等。而视图是基于一个或多个数据表的查询结果,因此它的结构是根据查询语句动态生成的。
-
存储空间:数据表在数据库中占据着一定的存储空间,而视图不占用额外的存储空间,它只是一个逻辑上的数据集合。视图的建立和删除只影响视图本身,不影响对应的基本表。
-
访问权限:通过设置权限,可以限制用户对数据表的操作权限。而对于视图,我们可以通过它来隐藏底层表的结构和数据,提供更安全的数据访问方式。
-
数据处理:数据表通常用于存储和管理大量的数据,支持各种复杂的数据操作,如聚合、排序、分组等。而视图一般用于简化对数据的查询操作,提供一个方便、易读的接口。
综上所述,视图和数据表在存储方式、数据更新、结构定义、存储空间、访问权限和数据处理等方面都存在一些差异。视图主要用于提供一种逻辑上的数据展现方式,简化复杂查询并保护敏感数据,而数据表则是实际存储和管理数据的物理结构。
3. 视图的优点
1. 逻辑数据独立性,聚焦特定的数据
在实际的应用过程中,不同的用户可能对不同的数据有不同的要求。
视图可以提供逻辑数据独立性,即应用程序与底层表的结构解耦。通过访问视图而不是直接访问底层表,即使底层表的结构发生变化,只需调整相应的视图定义,而不会影响应用程序的逻辑。
2. 简化数据访问
视图允许我们将复杂的查询逻辑封装到一个简洁的接口中。通过定义视图,可以隐藏底层表的结构和关联操作,使得用户只需执行简单的查询语句即可获取所需的数据,而无需了解复杂的数据库结构和查询语句。
3. 提高数据的安全性
视图是虚拟的,物理上是不存在的。通过视图,我们可以对敏感数据进行保护。通过控制视图的访问权限,可以限制用户只能查看或修改特定列或行的数据,从而确保敏感数据的安全性。
4. 共享所需数据
通过使用视图,每个用户不必都定义和存储自己所需的数据,可以共享数据库中的数据,同样的数据只需要存储一次。
5. 更改数据格式
通过使用视图,可以重新格式化检索出的数据,并组织输出到其他应用程序中。
6. 数据冗余和一致性
通过视图,可以消除数据冗余问题。当多个应用程序需要使用相同数据的子集时,可以创建视图来封装这些子集,从而减少数据冗余。此外,由于视图是基于底层表的查询结果生成的,因此视图的数据会随着底层表的数据变化而自动更新,确保数据的一致性。
总体而言,视图提供了一种灵活且安全的数据访问方式,能够简化复杂查询、提高数据安全性、减少数据冗余,并提供逻辑独立性。这些优点使得视图成为数据库中强大且重要的工具之一。
4. 创建视图
可以使用 CREATE VIEW 语句来创建视图。语法格式如下:
CREATE VIEW <视图名> AS <SELECT语句>
语法说明如下。
-
<视图名>:指定视图的名称。该名称在数据库中必须是唯一的,不能与其他表或视图同名。 -
<SELECT语句>:指定创建视图的 SELECT 语句,可用于查询多个基础表或源视图。
注意:
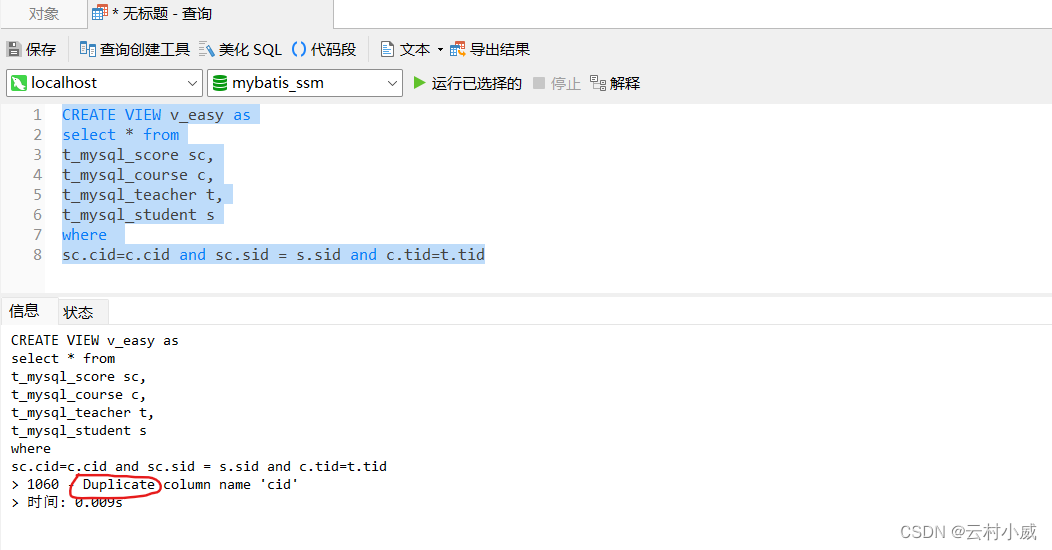
当创建视图时如遇错 Duplicate 说明表中出现相同字段名,因为我们经常需要设置这样的字段来与其他表进行关联,所以在建视图时,我们需修改指定查询的字段避免出现相同的字段。
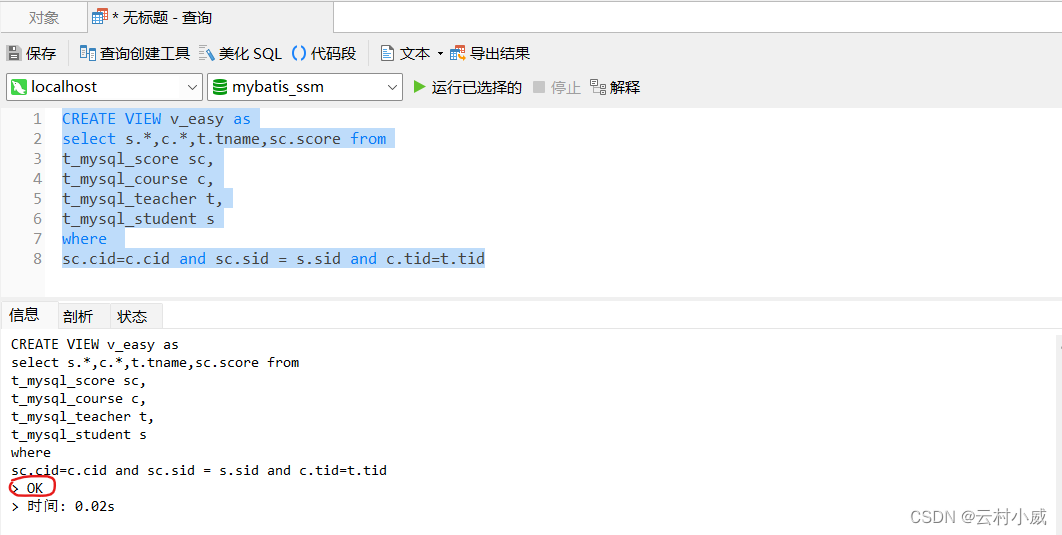
这样我们就可以根据视图名查询到该sql语句的数据

对于创建视图中的 SELECT 语句的指定存在以下限制:
-
用户除了拥有 CREATE VIEW 权限外,还具有操作中涉及的基础表和其他视图的相关权限。
-
SELECT 语句不能引用系统或用户变量。
-
SELECT 语句不能包含 FROM 子句中的子查询。
-
SELECT 语句不能引用预处理语句参数。
二、索引
1. 什么是索引
索引是数据库中用于提高数据检索效率的一种数据结构。它类似于书籍的目录,通过创建索引可以快速定位到特定的数据行,而无需扫描整个数据表。
在数据库中,索引是基于一个或多个列的值创建的,它们包含了列值和对应数据行的物理存储位置的映射关系。当执行查询操作时,数据库引擎可以使用索引来快速定位满足查询条件的数据行,从而加快查询速度。
2. 为什么要使用索引
索引就是根据表中的一列或若干列按照一定顺序建立的列值与记录行之间的对应关系表,实质上是一张描述索引列的列值与原表中记录行之间一 一对应关系的有序表。
索引是数据库中用来加快数据检索速度的重要工具,是数据库性能调优技术的基础。使用索引可以提高查询的效率,减少数据库系统的负载。常用于实现数据的快速检索!
在 MySQL 中,通常有以下两种方式访问数据库表的行数据:
1. 顺序访问
顺序访问是在表中实行全表扫描,从头到尾逐行遍历,直到在无序的行数据中找到符合条件的目标数据。
顺序访问实现比较简单,但是当表中有大量数据的时候,效率非常低下。例如,在几千万条数据中查找少量的数据时,使用顺序访问方式将会遍历所有的数据,花费大量的时间,显然会影响数据库的处理性能。
2. 索引访问
索引访问是通过遍历索引来直接访问表中记录行的方式。
使用这种方式的前提是对表建立一个索引,在列上创建了索引之后,查找数据时可以直接根据该列上的索引找到对应记录行的位置,从而快捷地查找到数据。索引存储了指定列数据值的指针,根据指定的排序顺序对这些指针排序。
简而言之,不使用索引,MySQL 就必须从第一条记录开始读完整个表,直到找出相关的行。表越大,查询数据所花费的时间就越多。如果表中查询的列有一个索引,MySQL 就能快速到达一个位置去搜索数据文件,而不必查看所有数据,这样将会节省很大一部分时间。
3. 索引优缺点
索引有其明显的优势,也有其不可避免的缺点。
优点
索引的优点如下:
-
通过创建唯一索引可以保证数据库表中每一行数据的唯一性。
-
可以给所有的 MySQL 列类型设置索引。
-
可以大大加快数据的查询速度,这是使用索引最主要的原因。
-
在实现数据的参考完整性方面可以加速表与表之间的连接。
-
在使用分组和排序子句进行数据查询时也可以显著减少查询中分组和排序的时间
缺点
增加索引也有许多不利的方面,主要如下:
-
创建和维护索引组要耗费时间,如果过度使用索引,数据库可能需要花费更多时间来维护和更新索引结构,从而影响整体性能。因此,需要根据具体情况选择适当的索引。
-
索引需要占磁盘空间,除了数据表占数据空间以外,每一个索引还要占一定的物理空间。如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸。
-
当对包含索引的列进行插入、更新或删除操作时,数据库不仅需要更新数据本身,还需要更新相应的索引。这可能导致更新操作变慢。
索引可以提高查询速度,但是会影响插入记录的速度。因为,向有索引的表中插入记录时,数据库系统会按照索引进行排序,这样就降低了插入记录的速度,插入大量记录时的速度影响会更加明显。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后,再创建索引。
综上所述,索引是提高数据库性能和查询效率的重要手段,但在使用索引时需要根据具体情况进行权衡和优化。
4. 何时不使用索引
-
表记录太少
-
经常增删改的表
-
数据重复且分布均匀的表字段,只应该为经常查询和最经常排序的数据列建立索引(如果某个数据类包含太多的重复数据,建立索引没有太大意义)
-
频繁更新的字段不适合创建索引(会增加IO负担)
-
where条件里用不到的字段不创建索引
5. 索引何时失效
-
like以通配符%开头索引失效
-
当全表扫描比走索引查询的快的时候,会使用全表扫描,而不走索引
-
字符串不加单引号索引会失效
-
where中索引列使用了函数(例如substring字符串截取函数)
-
where中索引列有运算(用了< or > 右边的索引会失效,用<= or >= 索引不会失效)
-
is null可以走索引,is not null无法使用索引(取决于某一列的具体情况)
-
复合索引没有用到左列字段(最左前缀法则,如果没用用到最左列索引,或中间跳过了某列有索引的列,索引会部分失效)
-
条件中有or,前面的列有索引,后面的列没有,索引会失效。想让索引生效,只能将or条件中的每个列都加上索引
6. 索引分类
6.1 普通索引
普通索引是最基本的索引,它没有任何限制;
-
创建索引语法:
create index index_name on table(column);
-
修改表结构方式添加索引:
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
-
删除索引
DROP INDEX index_name ON table
6.2 唯一索引
唯一索引与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
CREATE UNIQUE INDEX indexName ON table(column(length))
6.3 主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。简单来说:主键索引是加速查询 + 列值唯一(不可以有null)+ 表中只有一个。
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, PRIMARY KEY(ID) ) ;
6.4 组合索引
组合索引指在多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
这些是常见的索引分类,还有辅助索引、聚集索引等等...... 每种类型的索引都有其自身的特点和适用场景。在设计数据库时,根据具体的需求和数据访问模式,选择合适的索引类型非常重要。
三、数据的备份与恢复
1. 使用工具,类似Sqlyog、Navicat等导入导出数据。
1.1 使用工具 Navicat for MySQL导入
步骤1:

步骤2:

步骤3:

1.2 使用工具 Navicat for MySQL导出
步骤1:选择需要导出文件内容
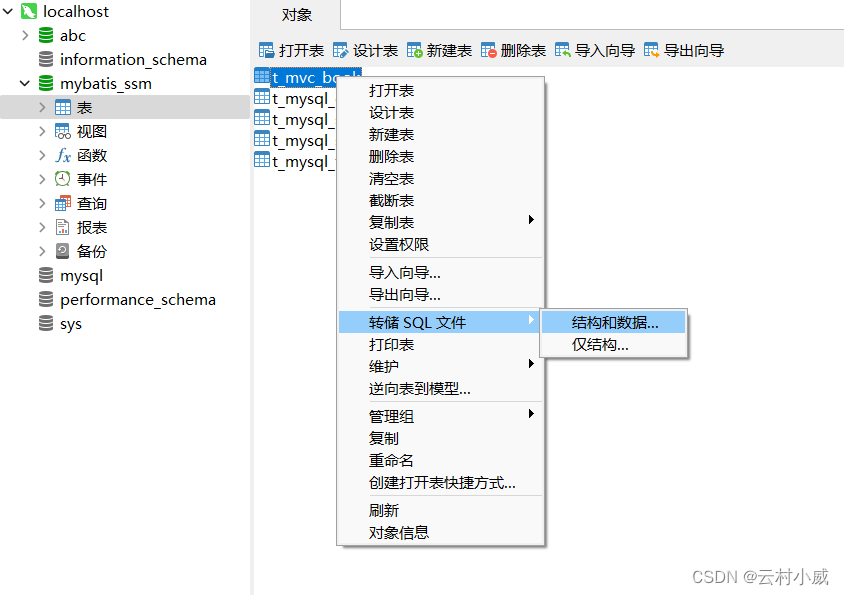
步骤2:选择需要导出的文件位置

❕ 使用Navicat工具导入导出因个人电脑性能而异处理时间有所差异。这种方式是最慢的!
2. 使用mysqldump导入导出
2.1 使用mysqldump导入
语法:mysqldump -u用户名 -p密码 数据库名 > 数据库名.sql(这个名字随便叫)
必须在mysql安装路径里的bin文件里运行cmd
1. 首先创建一个数据库
2. 使用数据库并设置编码集

3. 通过 source 命令输入sql路径即可

2.2 使用mysqldump导出
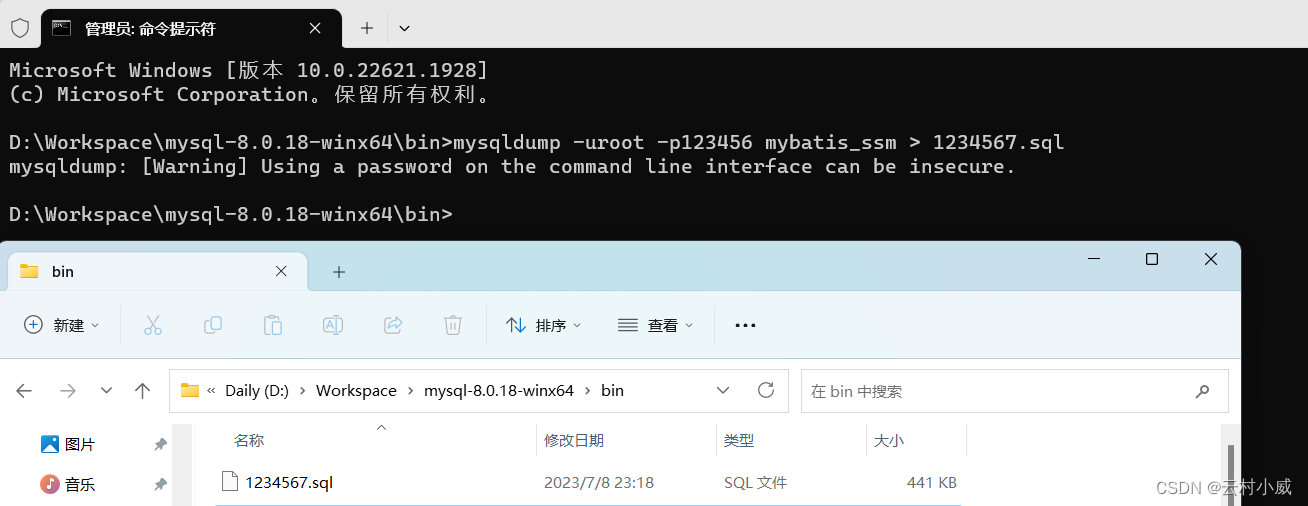
2.2.1 导出表数据和表结构
doc命令: mysqldump -u用户名 -p密码 数据库名 > 数据库名.sql
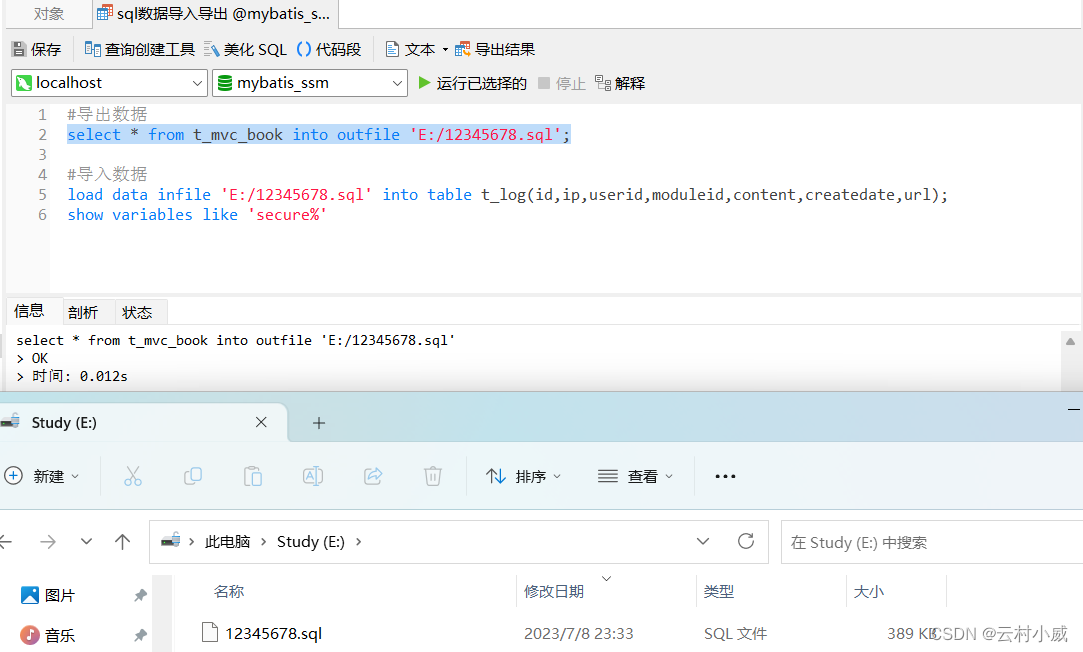
3. 使用LOAD DATA INFILE(OUTFILE)导入导出
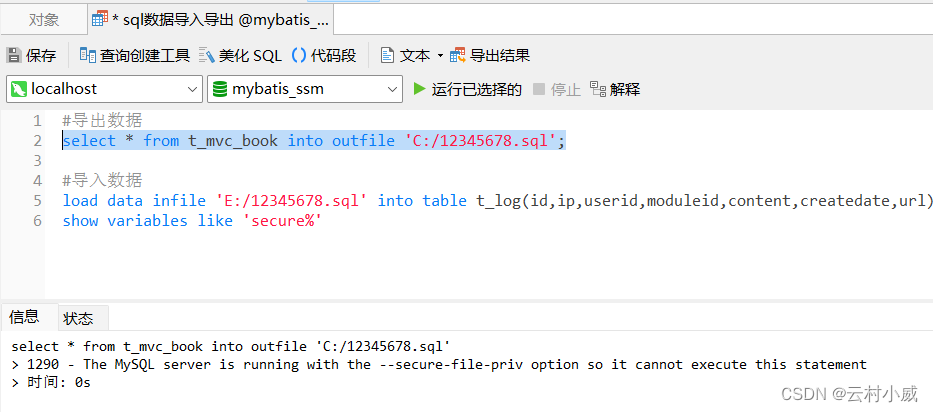
导出:select * from 表名 into outfile '/文件名.sql'
导入:load data infile '/文件名.sql' into table 表名(列名1,...)
4. 使用LOAD DATA INFILE(OUTFILE)导入导出注意事项:
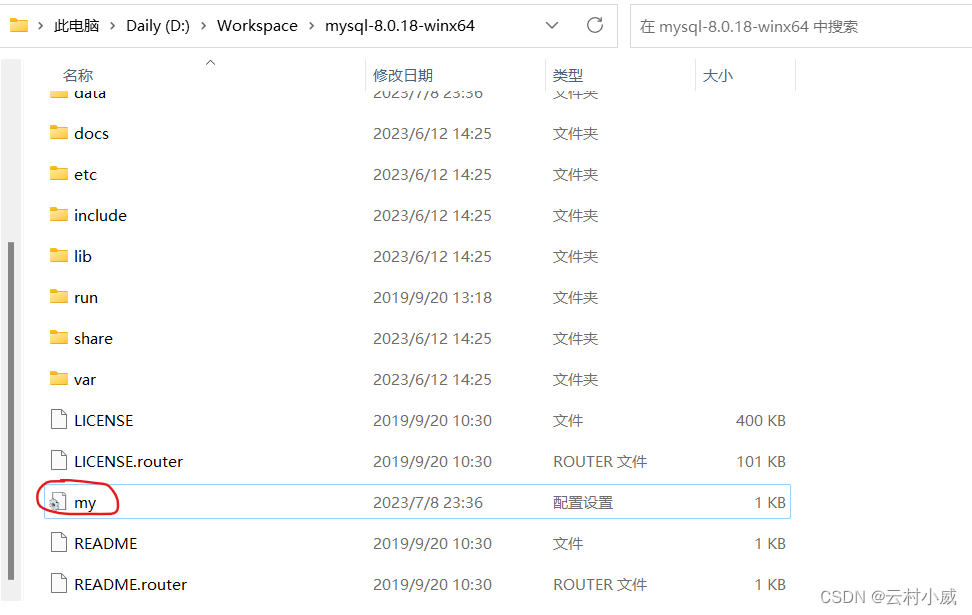
如果在my.ini 文件配置中没有设置 secure_file_priv=磁盘名 就没有权限导入导出数据
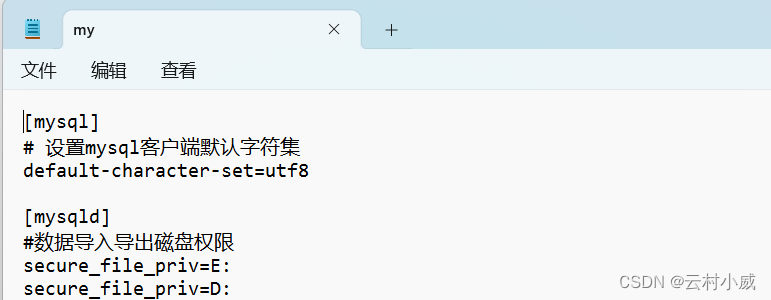
则会报一下错误