本篇博客主要是关于函数的重载、匿名函数、函数的执行原理与闭包。
目录
一、函数创建的三种方式
方式一:声明方式
直接使用function对函数进行声明。
function 函数名(形参1,...){
函数体;
return;
}通过这种方式创建的函数有声明提前。
方式二:直接量方式
使用var关键字定义一个变量,将一个函数赋值给这个变量就是直接量方式。
var 函数名=function(){
函数体
}变量名就是函数名。
通过这种方式创建的函数没有声明提前。
方式三:构造函数方式
使用new function的方式进行创建。
var 函数名=new Function("形参1","形参2",..."函数体;return xxx")无论参数实际是什么类型;创建函数时的每一部分都必须用""包裹。
通过该种创建的函数没有声明提前,不可以在函数之前调用该函数。
何时使用该种方式?
如果函数体不是固定的,而是字符串动态拼接的时候。
注意:不论是哪种方式创建函数,调用都是函数名()方式。
二、函数的重载
1、什么是重载?
- 重载就是:在代码中存在多个函数名相同的函数,但参数的个数不相同,根据你传参的数量来判断需要哪个函数并自动的调用。
- 重载的主要作用就是减少程序员的负担,减轻记忆函数名等API的烦恼。
2、JS中是否支持重载?
答案是:不支持。
根据JS的语法来看,如果给多个函数起相同的函数名,那么,后一个函数会覆盖前一个函数的内容。当程序员调用函数时,会发现只会执行最后一个。
解决办法:使用函数的arguments对象。
3、JS函数中的arguments对象
- arguments是函数中自带的对象,不需要程序员创建,只要创建了函数就可以使用该对象;
- arguments是一个伪数组对象;
- arguments的作用主要就是接收所有调用函数时传递的实参;
何时使用arguments?
- 不知道要传多少参数时;
- 需要根据传参的不同(传参的数量、参数的类型等)判断执行什么代码时;
function introduce() {
console.log(arguments.length);
// 既然是伪数组,就可以使用.length了
// 还可以使用遍历
// 只是不能使用数组的方法
}
var res = introduce("xxx", "18", "睡觉");三、匿名函数
- 匿名函数就是:没有函数名的函数。
- 匿名函数只会在代码中执行一次,因为没有变量引用着,在函数执行结束之后,就会自动的释放内存,如果想重复执行多次,只有重复写相同的代码或者循环。
匿名函数的调用分为两类:自调和回调。
1、匿名函数自调
只会执行一次,函数执行完毕之后就会自动释放内存,可以替代全局写法,节省内存,不用手动的去释放变量的内存。
语法:(匿名函数)()
(function () {
console.log("我是匿名函数的自调用");
})();要注意的是:虽说匿名函数结束会自动释放其中的内存,但不会释放在其中给某个元素绑定事件的内存。
(function(){
btn.onclick=function(){
console.log("我是按钮,我被点击了")
}
})()其中的btn的onclick事件不会被释放,在匿名函数结束之后依旧可以使用。
2、匿名函数回调
某个方法传入的实参是一个匿名函数,该形参不需要我们程序员调用,会在主函数内预先设置好调用位置,待传入匿名函数实参后自动执行。
比如:数组.sort()。
当想要将多位小数或者汉字、字母、字符串等按照从大到小或者从小到大的顺序进行排列时,就需要传入一个回调函数,并返回结果。
var arr=[5,6,9,3,4,1,2,7,55,11,2,5,66,99]
arr.sort(function(a,b){
return a-b
//return b-a
})四、函数的执行原理(重难点)
讲了很多关于函数的东西,其中有个很重要的点:函数执行完毕,内存自动释放。那么这其中的原理是什么?
执行原理的简单理解
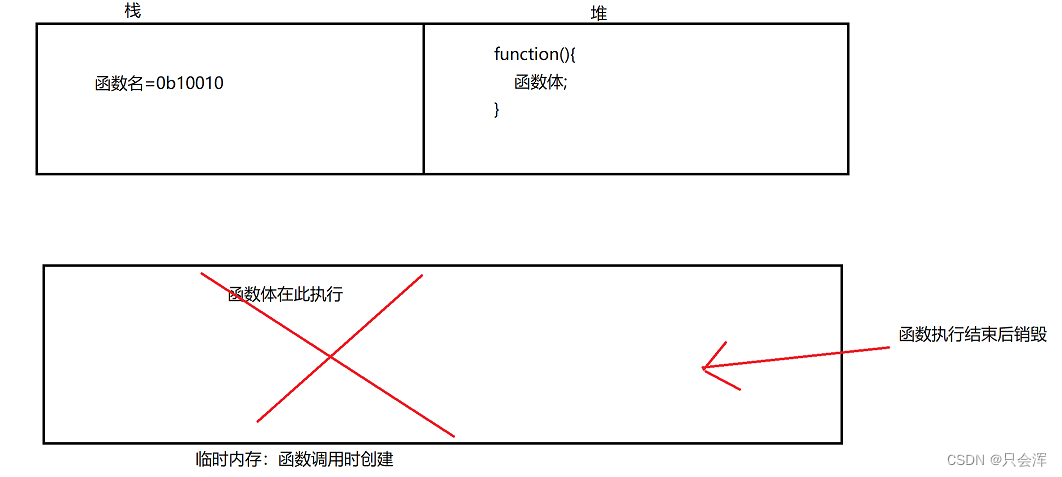
1、函数定义时:
在函数定义阶段,函数名保存在内存的栈区中,function和函数体保存在内存的堆区中,在栈区的函数名保存着堆区函数体的地址。
2、函数调用时:
- 在函数调用时,计算机内部会生成一个临时内存来保存函数体;
- 在函数体执行完毕之后,该临时内存会被销毁,包括变量等,所以在函数外部无法获取到在函数内部定义的变量等,这也是为什么说函数执行结束,内存自动释放的原因;
- 函数每调用一次,就会创建一个新的临时内存,每次的临时内存地址不相同;
执行原理的详细理解
1、程序加载时
- 创建执行环境栈(ECS),是用于保存函数的调用顺序的数组;
- 首先压入全局执行环境(全局EC),全局EC中引用着全局对象window;
- window对象中保存着全局变量;
2、程序定义时
- 创建函数对象:封装代码段;
- 在函数对象中定义了一个scope属性,保存着函数来自的作用域;
- 全局函数的scope都是window;
3、程序调用前
- 在ECS中压入新函数的EC;
- 创建新函数的活动对象(AO),AO中保存着本函数调用的局部变量;
- 在该函数的EC中创建scope chain(作用域链)属性,引用着函数的AO;
- AO的parent属性为函数的scope引用的对象;
4、程序调用时
产生了变量的使用规则:
- 优先使用局部变量;
- 局部变量没有就找上级要;
- 上级没有就找全局要;
- 全局没有就报错;
5、程序调用结束
程序调用结束后,函数的EC出栈,函数的AO自动释放销毁,局部变量也就销毁了。

在详细理解中的AO(函数的活动对象)其实就是简单理解中的临时内存,在函数调用结束后自动释放。
五、函数的闭包(重难点)
1、如何保存临时空间
在函数的执行原理中,我们了解到:函数执行时会产生一个临时内存(或者说是AO),在函数调用结束后会自动释放销毁。这也导致了我们无法获取和使用函数内部的临时变量。
所以我们要想用函数内的变量,也就是要将该临时内存留住,不让其自动释放。
那么如何让这个临时空间不被释放呢?
-
函数有返回值
-
返回值必须是复杂类型
-
返回值要赋值给外面的变量
以上三个条件要同时满足才可以,因为外部有变量在引用该返回值,不会触发JS中的垃圾回收机制。
当不销毁的临时内存空间变多之后,会把内存占满,所以在函数外部使用完函数内部的变量之后,需要及时的清除引用。
// 函数的定义阶段
// function f1() {
// var name = "张三";
// console.log(name);
// }
// // 函数的调用
// f1();
// 临时区域不被销毁的情况
function test() {
var name = "张三";
console.log(name);
// 在name被打印结束之后,name还是被销毁
var obj = {
a: 1,
b: 2,
};
return obj;
// obj满足上述三个条件,所以不会被销毁
}
var res = test();
console.log(res);
res.a++;
res.a++;
res.a++;
console.log(res);
var res2 = test();
console.log(res == res2); //false2、函数闭包的实现
函数闭包的概念就是在前一点的基础之上进行改变:
- 两个函数进行嵌套;
- 外层函数内创建了临时变量;
- 在这个函数内使用return返回一个新的函数并被外界所引用;
- 该新函数引用了外层函数的临时变量;
满足以上四个条件,即形成闭包,函数的AO就不会被自动释放。
function outer() {
var name = "xxx";
return function () { //这里不一定是匿名函数
console.log(name);
};
}
var res = outer();
res();3、闭包的优缺点
优点:让临时变量永驻内存,保护一个可以反复使用的局部变量;
缺点:使用不当有可能会造成内存泄露,所以在闭包使用完毕之后,也需要将引用内存释放;
为什么说让“临时变量永驻内存”是优点?
简单地说:可以减少重复代码的书写。
// 闭包优点的体现
// 当我们想要跳转到某个网站下的不同页面时
/*
网站的主要网址:www.xxx.com
网站的子页1:www.xxx.com/子页1.html;
网站的子页2:www.xxx.com/子页2.html;
网站的子页3:www.xxx.com/子页3.html;
网站的子页4:www.xxx.com/子页4.html;
要跳转到不同子页的话,就要不停的重复www.xxx.com,比较麻烦,且重复代码比较多。
*/
function differIndex(url) {
return function (path) {
// 形参也是函数内部的临时变量,所以形成闭包之后形参也不会被释放
return url + "/" + path;
};
}
var res = differIndex("www.xxx.com");
console.log(res("子页1.html"));
console.log(res("子页2.html"));
console.log(res("子页3.html"));
console.log(res("子页4.html"));
// 调用结束之后,将引用释放
res = null;4、闭包的应用
闭包可以用于防抖和节流,但这里我不会去写关于防抖和节流的东西,我从另一个例子来说明闭包的作用。
首先准备一个无序列表:
<ul>
<li>111</li>
<li>222</li>
<li>333</li>
</ul>然后给每个li标签添加点击事件:
/*
点击每一个li,打印对应的索引值
如果仅仅是以下的写法:
for (var i = 0; i < lis.length; i++) {
lis[i].onclick = function () {
console.log(i);
};
}
打印出来的i都只会是lis的长度,因为循环在网页已加载完的瞬间就已经执行完毕了,
所以i就会自增到lis的长度。
那么如何利用闭包实现点击每个li,打印对应的索引值呢?
for (var i = 0; i < lis.length; i++) {
lis[i].onclick = (function (index) {
return function () {
console.log(index);
};
})(i);
}
将原本=右边的匿名函数变成自执行匿名函数,同时将i传入进去。
在自执行匿名函数内的第一层函数就相当于闭包的外层函数,
通过该外层函数的形参保存自执行匿名函数传递的实参,
然后外城函数内部返回一个函数,并打印外层函数的形参,形成闭包
这样就实现了需要的效果。
*/
var lis = document.getElementsByTagName("li");
for (var i = 0; i < lis.length; i++) {
lis[i].onclick = (function (index) {
return function () {
console.log(index);
};
})(i);
}