目录
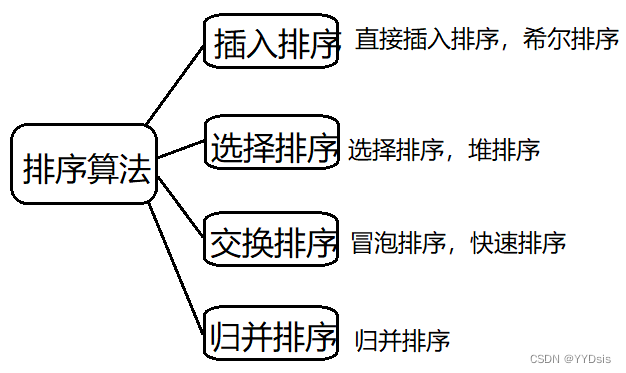
一.8种排序方式总览分析(带图)
1.按方式分类(比较排序)
*计数排序:非比较排序
二.8种排序方式详细解析
1.计数排序
注意:计数排序适合范围集中,且范围不大的整型数组排序。不适合范围分散或者非整型的排序,如:字符串、浮点数 等
步骤:
1.找到原数组最大的值,记作range
2.设置一个计数数组,遍历一遍原数组O(n),统计每个数据出现的次数。
3.遍历一遍计数数组O(range)
计数排序分为:相对映射型和非相对映射型(相对位置)
图示意:

2.冒泡排序
遍历有序区间的各个数,从其开始到结尾的区间内轮转交换,不断缩小区间。
原理:不断把大/小的数移到后面
注意点:为提高效率,当发现一次循环中没有数对交换,即可中止循环。
void BubbleSort(int*a,int n)
{
int i = 0,j=0;
for (j = 0; j<n; j++)
{
bool exchange = false;
for (i = 0; i < n-j; i++)
{
if (a[i + 1] < a[i])
{
Swap(&a[i + 1], &a[i]);
exchange = true;
}
}
//加入判断环节,提前终止,提高效率
if (exchange == false)
{
break;
}
}
}3.选择排序
遍历有序区间的各个数,找出其之后的最大/最小数并与该数之后的数进行替换。
代码的设计思路是设置left,right下标从数组两端向中间遍历,依次筛选出最大值和最小值mini,maxi,并分别与left,riight进行交换。
注意点:在交换过程中,left所处的位置可能正好被maxi标记,接下来下一步maxi与right的交换则会出错,right无法与正确的maxi交换。
解决方法:如果left和maxi重叠,交换后要修正
void SelectSort(int* a, int n)
{
int left = 0;
int right = n;
while (left < right)
{
int mini = left, maxi = right;
for (int i =left+1; i <= right; i++)
{
if (a[i] > a[maxi])
{
maxi = i;//移动下标
}
if (a[i] < a[mini])
{
mini = i;
}
}
Swap(&a[left], &a[mini]);
if (left == maxi)
{
maxi = mini;
}
Swap(&a[right], &a[maxi]);
left++;
right--;
}
}4.插入排序
遍历有序区间的各个数,把其视作临时变量tmp,分别于它前面的数进行对比,
其进一步优化即为“希尔排序”
注意点:此算法中,当tmp比第一个数大/小时,end会到-1的位置。所以采用图中标记用法。

//升序
void InsertSort(int* a, int n)//a 数组 n 个数
{
int i = 0;
for (i = 1; i < n; i++)
{
int end = i - 1;
int tmp = i;
while (end >= 0)
{
if (a[tmp] < a[end])
{
//整体后移
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
//填空
a[end + 1] = a[tmp];
}
}5.希尔排序
其可以理解为在插入排序的基础上进行预排序(分组插排)
注意点:图示辅助理解循环:
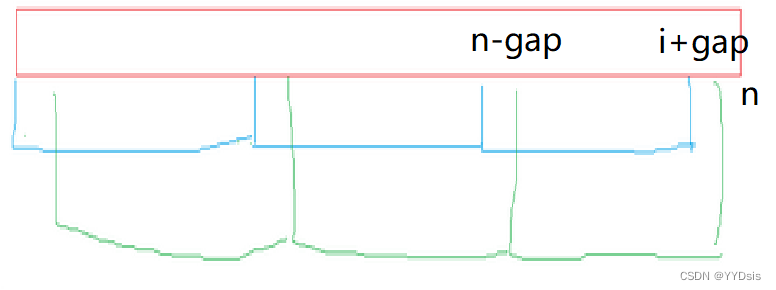
void ShellSort(int* a, int n)
{
//gap==1 插入排序
//gap>1预先排序
int gap=n;
//升序
while(gap>1)
{
gap = gap / 2;
//gap=gap/3+1 确保gap的跳跃到最后为1,
int i = 0;
for (i = 0; i < n-gap; i++)
{
int end = i;
int tmp = i+gap;
while (end >= 0)
{
if (a[tmp] < a[end])
{
//整体后移
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
//填空
a[end + gap] = a[tmp];
}
}
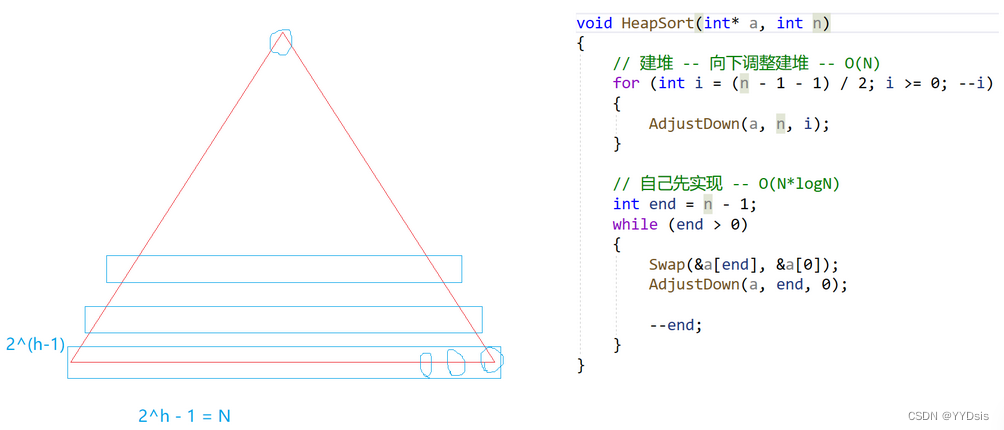
}6.堆排序
详情可见博主关于堆排详解:
7.快速排序(递归和非递归写法)
任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中的所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
注意点:当快速排序接近二分(二叉树)的递归模式时,效率最高。因此引入“三数取中”优化代码:
int GetMidNumi(int* a, int left, int right) { int mid = (left + right) / 2; if (a[left] < a[mid]) { if (a[mid] < a[right]) { return mid; } else if (a[left] > a[right]) { return left; } else { return right; } } else // a[left] > a[mid] { if (a[mid] > a[right]) { return mid; } else if (a[left] < a[right]) { return left; } else { return right; } } }
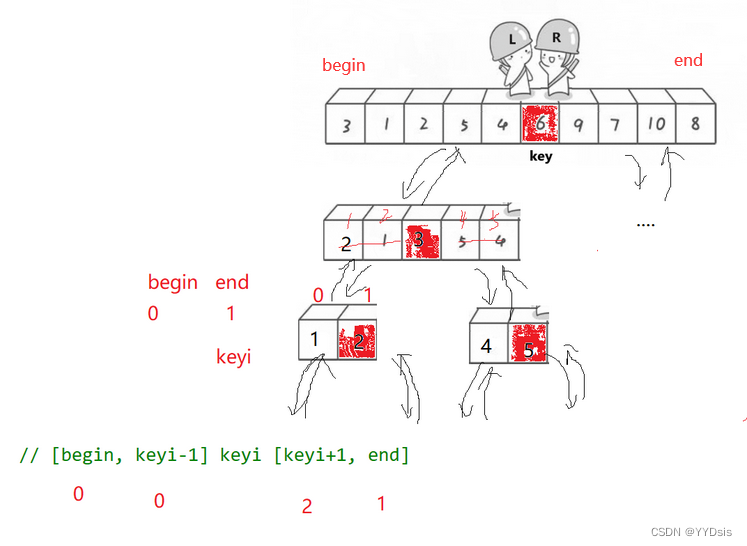
1.三种排序方式
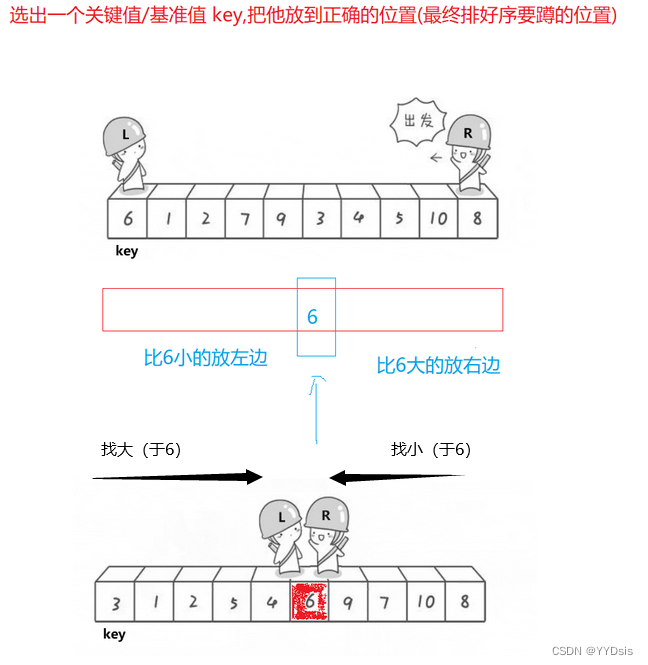
1.交换法
1.左边做key,右边先走——保证相遇位置比key小
ps:【右边先走找比key小的数,则其停止位置一定小于等于key】
2.由于左右相遇的位置一定比key小,把左边与相遇位置替换
图示:
代码:
2.挖坑法
1.先将左边第一个数据放在临时变量key中,原地形成一个坑位
2.右边先动,找小于key的数,放到坑位中,并且原地新生成一个坑位
3.当左右相遇时,将key填入最后一个坑位中

3.前后指针法(玩区间)
1.左边第一个数设为key,prev(延迟指针),cur(实时指针)
2.cur开始向右移动,找到比key小的值prev和cur同时移动
3.找到比key大的值只移动cur——保证prev和cur中间隔着一段比key大的区间
4.找到比key小的值时,交换prev下一个位置(比key大的区间)和cur位置的值——比key大的值翻到区间右边,把比key小的值翻到区间左边。
图示:

2.非递归写法(类比层序遍历用队列实现,这里用栈)
学习原因:递归的本质是不断开辟空间,当递归层数过多时可能会出现栈溢出的问题。因而引入非递归写法
实现原理:递归写法本质上是向下不断开辟空间,当达到终止条件时返回并归还空间。不采用递归的写法,即可以在原数组上直接对下标进行划分
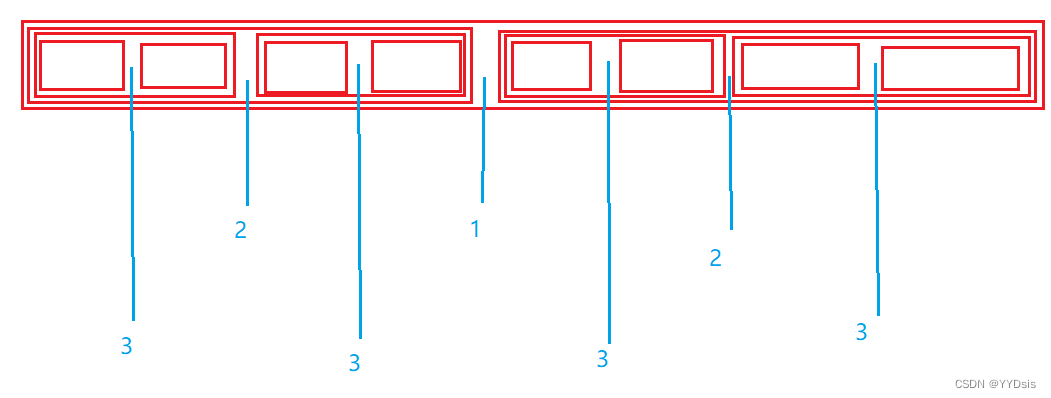
1.入尾标,入头标
2.标记begin,end后,进行头删,并算出keyi
3.此时,原数组被分割成【begin,keyi-1】keyi【keyi+1,end】。
分别对存在的区间进行同样的操作(压栈,出栈)即可。
图示:
PS:数字表示,可视作递归的层数。而实际上没有递归。
void quicksortnonr(int*a,int left,int right)
{
ST st;
StackInit(&st);
StackPush(&st, right);//表示end的先入栈
StackPush(&st, left);
while (!StackEmpty(&st))
{
int begin = StackTop(&st);
StackPop(&st);
int end = StackTop(&st);
StackPop(&st);
//得出keyi
int keyi = Partsort3(a, begin, end);//三数取中
//【begin,keyi-1】keyi【keyi+1,end】
if (keyi + 1 < end)
{
StackPush(&st, end);//表示end的先入栈
StackPush(&st, keyi+1);
}
if (keyi -1 >begin)
{
StackPush(&st, keyi - 1);//表示end的先入栈
StackPush(&st, begin);
}
}
StackDestroy(&st);
}8.归并排序(递归和非递归写法)
1.递归写法
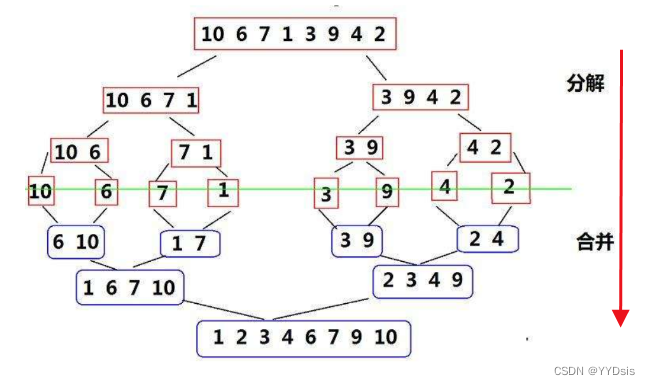
归并原理:两个有序数组进行比较,并尾插到新空间。
PS:结合递归后,即可细分到只剩两个数归并形成有序数组,两两合成新的有序序列,并拷贝到一块新空间(避免覆盖原数组),新空间的位置关系要与原数组对应
形象图示:

注意点:为提升效率,采用取中间数进行划分
图示:
void MergeSort(int* a, int begin, int end, int* tmp)
{
if (begin >= end)
return;
int mid = (begin + end) / 2;
MergeSort(a,begin,mid,tmp);
MergeSort(a,mid+1,end,tmp);
//拷贝回与原数组a相对应的位置
memcpy(a + begin,tmp + begin,sizeof(int) * (end - begin + 1));
}递归实现的逻辑:后序遍历
PS:后序遍历相关可查看博主相关博客:(62条消息) 二叉树的运用(递归)(遍历方式)(简洁.含代码,习题)_YYDsis的博客-CSDN博客

2.非递归写法(注意越界情况的分类讨论)
分析:与快排的非递归算法同理。当递归次数过多时,有可能会导致栈溢出。不妨在原数组的基础上,直接对下标对应区间范围内的数组进行归并,并拷贝回原数组。
形象图示:

注意点:有时候gap的选取会越界!
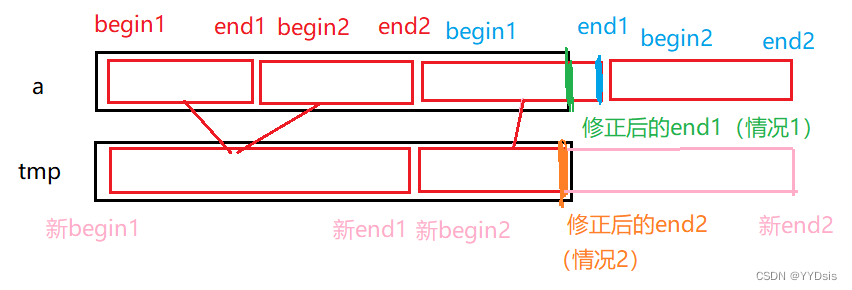
分析:本质上是不断选取【begin1,end1】【begin2,end2】
注意点:以下分析是在归并进行前,对下标对应空间进行讨论!
1.当begin1和end2和并后形成新begin1,end1时,若end1临界(begin2越界)/end1越界,则停止归并
2.当end1越界时,则对end1进行修正
形象图示:
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail\n");
return;
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
// [begin1,end1][begin2, end2]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;//((i+gap)+(gap-1))
//printf("[%d,%d][%d,%d] ", begin1, end1,begin2,end2);
//分类讨论情况
if (end1 >= n || begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;//修正end2区间
}
printf("[%d,%d][%d,%d] ", begin1, end1, begin2, end2);
int j = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
// 归并一部门拷贝一部分
memcpy(a+i, tmp+i, sizeof(int) *(end2-i+1));
}
printf("\n");
gap *= 2;
}
free(tmp);
}三.8种排序方式复杂度/稳定性分析
1.稳定性的概念
假定再待排序的记录序列中,存在多个具有相同关键字的记录,若经过排序,这些记录的相对次序保持不变,则称这种算法是稳定的。
2.分析
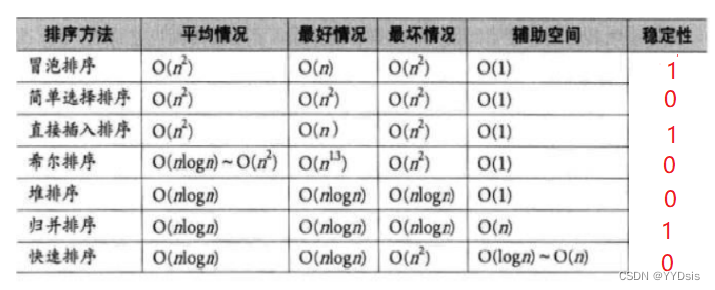
*计数排序较为特别,时间复杂度O(n)/O(range),空间复杂度为O(n)
1.简单选择排序不稳定的原因
特例:替换的数在两相同数同一边时

2.复杂度分析综述
1.希尔排序是直接插入排序基础上加了预处理。较为复杂,暂记结论。
2.直接插入排序,是取每一个数和前面所有数进行比对。无论如何都要先取,所以最好情况即有序情况即是n,最坏情况相当于一个数组的遍历,n^2。
3.快速排序当keyi每次都能取中间值时,接近二叉树,nlogn。keyi每次都取最左/右值时,即相当于一个数组的遍历,n^2。
4.归并排序,接近二叉树,nlogn。由于需要tmp新空间容纳归并后的新空间,空间复杂度为n
5.堆排序,分为堆调整(向上向下)和用删除思想堆排序两部分,根据数学计算知道后者复杂度为nlogn,即堆排整体为nlogn。
