描述
上一篇写的只是针对es做普通的CRUD,这次采用接口做CRUD,如果是小白的话,可以查看我以往的ES文章。
依赖项
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>6.8.12</elasticsearch.version>
</properties>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
操作
Entity实体
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
/**
* springboot-es >>> 【cn.ityao.es.entity】
*
* @author: tongyao
* @since: 2023-05-16 15:13
*/
@Data
@Document(indexName = "person_index", type = "person")
public class Person {
@Id
private String id;
@Field(type = FieldType.Keyword)//手动设置为keyword 但同时也就不能分词
private String name;
@Field(type = FieldType.Auto)//自动检测类型
private int age;
@Field(type = FieldType.Text, analyzer = "ik_smart", searchAnalyzer = "ik_max_word")//设置为text 可以分词
private String info;
}
Service,这里的Service需要继承一个CrudRepository类,<对应实体,主键ID类型>,接口名称自定义,跟Jpa类似。
import cn.ityao.es.entity.Person;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
/**
* springboot-es >>> 【cn.ityao.es.service】
*
* @author: tongyao
* @since: 2023-05-16 15:16
*/
public interface IPersonService extends ElasticsearchRepository<Person,String> {
//根据name查询
List<Person> findByName(String name);
//根据name和info查询
List<Person> findByNameAndInfo(String name, String info);
}
Controller
import cn.ityao.es.entity.Person;
import cn.ityao.es.service.IPersonService;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchResultMapper;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.aggregation.impl.AggregatedPageImpl;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Random;
/**
* springboot-es >>> 【cn.ityao.es.controller】
*
* @author: tongyao
* @since: 2023-05-16 15:17
*/
@RestController
public class PersonController {
@Autowired
private ElasticsearchRestTemplate elasticsearchTemplate;
@Autowired
private IPersonService iPersonService;
private String[] names = {
"诸葛亮", "曹操", "李白", "韩信", "赵云", "小乔", "狄仁杰", "李四", "诸小明", "王五"};
private String[] infos = {
"我来自中国的一个小乡村,地处湖南省", "我来自中国的一个大城市,名叫上海,人们称作魔都"
, "我来自杭州,这是一个浪漫的城市"};
/**
* 保存数据
*
* @return
*/
@GetMapping("saveUser")
public Object saveUser() {
//添加索引mapping索引会自动创建但mapping自只用默认的这会导致分词器不生效 所以这里我们手动导入mapping
Random random = new Random();
List<Person> users = new ArrayList<>();
for (int i = 0; i < 20; i++) {
Person person = new Person();
person.setId(i+"");
person.setName(names[random.nextInt(9)]);
person.setAge(random.nextInt(40) + i);
person.setInfo(infos[random.nextInt(2)]);
users.add(person);
}
Iterable<Person> users1 = iPersonService.saveAll(users);
return users1;
}
/**
* 通过id查询数据
*
* @return
*/
@GetMapping("getDataById")
public Object getDataById(@RequestParam(value = "id") String id) {
return iPersonService.findById(id);
}
/**
* 分页查询
*
* @return
*/
@GetMapping("getAllDataByPage")
public Object getAllDataByPage() {
//本该传入page和size,这里为了方便就直接写死了
//表示通过Id正序排序
Pageable page = PageRequest.of(0, 3, Sort.Direction.ASC, "id");
Page<Person> all = iPersonService.findAll(page);
return all.getContent();
}
/**
* 根据名字查询
*
* @param name
* @return
*/
@GetMapping("getDataByName")
public Object getDataByName(@RequestParam(value = "name") String name) {
return iPersonService.findByName(name);
}
/**
* 通过名字和Info取交集查询
*
* @param name
* @param info
* @return
*/
@GetMapping("getDataByNameAndInfo")
public Object getDataByNameAndInfo(String name, String info) {
//这里是查询两个字段取交集,即代表两个条件需要同时满足
return iPersonService.findByNameAndInfo(name, info);
}
/**
* 分词高亮查询
*
* @param value
* @return
*/
@GetMapping("getHightByUser")
public Object getHightByUser(@RequestParam(value = "value") String value) {
//根据一个值查询多个字段 并高亮显示 这里的查询是取并集,即多个字段只需要有一个字段满足即可
BoolQueryBuilder boolQueryBuilder= QueryBuilders.boolQuery()
.should(QueryBuilders.matchQuery("name",value))
.should(QueryBuilders.matchQuery("info",value));
NativeSearchQuery nativeSearchQuery=new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withHighlightFields(new HighlightBuilder.Field("name"),new HighlightBuilder.Field("info"))
.withHighlightBuilder(new HighlightBuilder().preTags("<span style='color:red'>").postTags("</span>"))
// 高亮分页,注释就是默认全部
/*.withPageable(PageRequest.of(0,3))*/
.build();
AggregatedPage<Person> aggregatedPage = elasticsearchTemplate.queryForPage(nativeSearchQuery, Person.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) {
ArrayList<Person> personArrayList = new ArrayList<Person>();
SearchHits hits = response.getHits();
for (SearchHit searchHit : hits) {
if (hits.getHits().length <= 0) {
return null;
}
Map<String, Object> sourceAsMap = searchHit.getSourceAsMap();
String id = sourceAsMap.get("id").toString();
String name = sourceAsMap.get("name").toString();
String info = sourceAsMap.get("info").toString();
Person person = new Person();
HighlightField contentHighlightField = searchHit.getHighlightFields().get("info");
if(contentHighlightField==null){
person.setInfo(info);
}else{
String highLightMessage = searchHit.getHighlightFields().get("info").fragments()[0].toString();
/*articleInfo.setInfo(StringUtil.stripHtml(highLightMessage).replaceAll("_",""));*/
person.setInfo(highLightMessage.replaceAll("_",""));
}
HighlightField nameHighlightField =searchHit.getHighlightFields().get("name");
if(nameHighlightField==null){
person.setName(name);
}else{
person.setName(searchHit.getHighlightFields().get("name").fragments()[0].toString());
}
person.setId(id);
personArrayList.add(person);
}
if (personArrayList.size() > 0) {
return new AggregatedPageImpl<T>((List<T>) personArrayList);
}
return null;
}
@Override
public <T> T mapSearchHit(SearchHit searchHit, Class<T> aClass) {
return null;
}
});
List<Person> list = aggregatedPage.getContent();
// 总数据量
long total = aggregatedPage.getTotalElements();
// 总页数
long totalPage = aggregatedPage.getTotalPages();
return list;
}
}
测试
先调用加入数据接口。
http://localhost:9200/saveUser
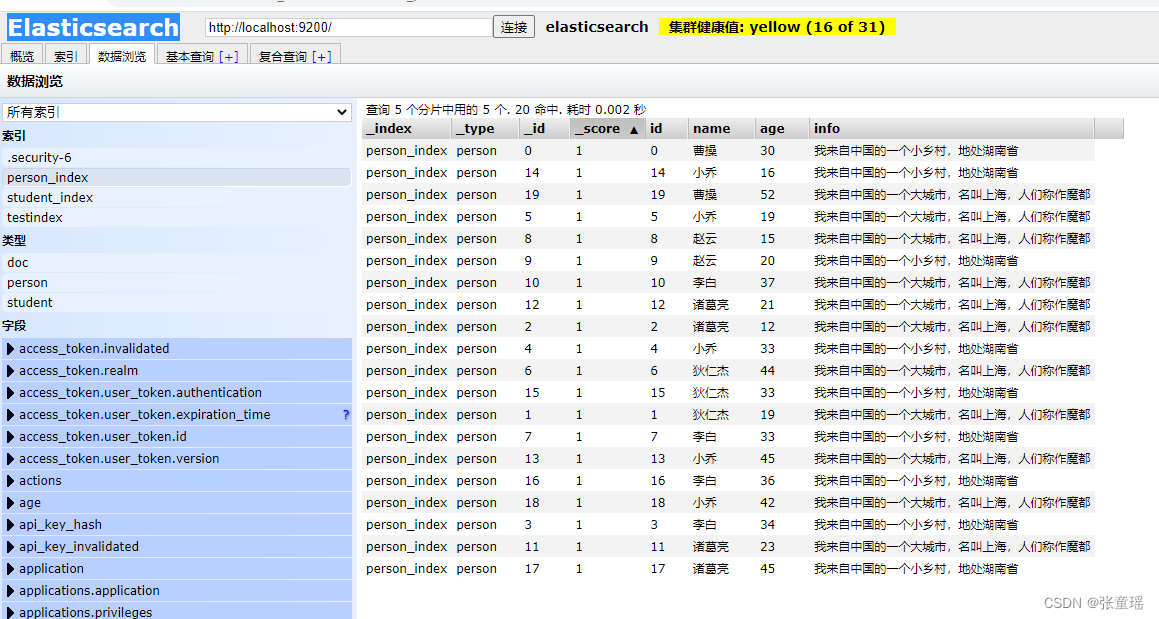
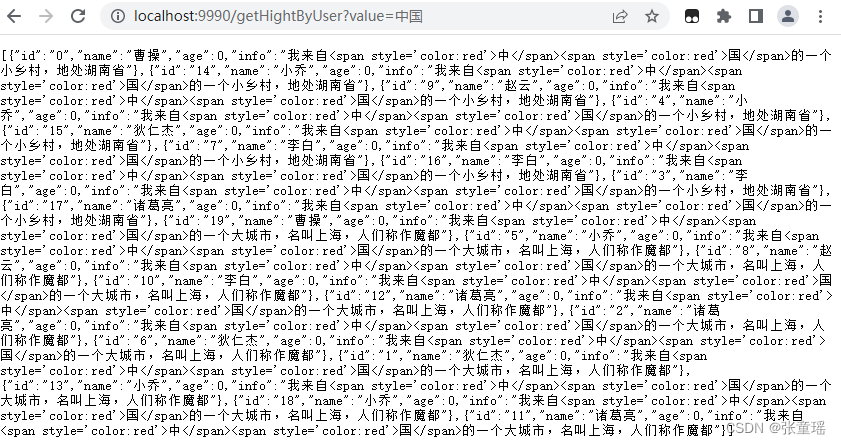
查询数据接口
http://localhost:9990/getHightByUser?value=中国
参考文章:https://blog.csdn.net/zhiyikeji/article/details/128908596