环境使用
- Python 3.8
- Pycharm
模块使用
- requests
- jieba 结巴分词
- wordcloud 词云
数据来源分析
明确需求 <数据来源分析>
-
采集数据是什么东西? 通过那个url地址得到想要数据的内容
-
抓包分析: 浏览器自带工具 --> 开发者工具
I. F12 或者 鼠标右键点击检查 选择 network 点击第二页
II. 复制评论内容, 在开发者工具里进行搜索, 可以直接找对应评论数据包
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100029079354&score=0&sortType=5&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1

数据获取代码实现
发送请求
url = 'https://***屏蔽一下不然不给过.com'
# 请求参数 --> 字典数据类型 构建完整键值对
data = {
# 'callback': 'fetchJSON_comment98',
'productId': '100029079354',
'score': '0',
'sortType': '5',
'page': page,
'pageSize': '10',
'isShadowSku': '0',
'rid': '0',
'fold': '1',
}
# 模拟浏览器 --> headers 请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求 requests 模块 get 方法<请求方式>
# 等号左边: url/params/headers 属于get函数里面形式参数 等号右边 url/data/headers 传入进去参数/变量
response = requests.get(url=url, params=data, headers=headers)
获取数据
服务器返回响应数据
- response 响应对象
- response.text 获取响应文本数据
- response.json() 获取响应json字典数据
解析数据
字典数据类型: 通过键值对提取数据内容 <字典取值>
根据冒号左边的内容[键], 提取冒号右边的内容[值]
# for循环遍历 把列表里面元素一个一个提取出来
for i in response.json()['comments']:
content = i['content']
print(content)
保存数据
python学习交流Q群:770699889 ### 源码领取
with open('口红评论.txt', mode='a', encoding='utf-8') as f:
# 写入数据内容
f.write(content)
f.write('\n')
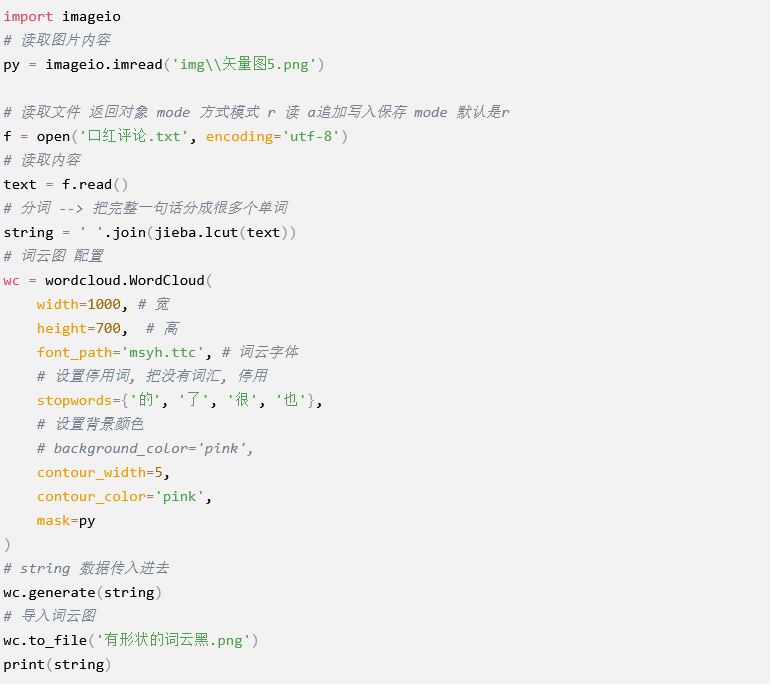
词云代码

好啦,今天的分享到这里就结束了,对文章有问题的可以留言或者私信
