目录
为什么需要代码分析?
多人团队业务组中的代码质量卡控
假设目前业务的组员确定了对时间格式处理方式由 new Date 方法变为由 dayjs() 库,并且已经做了存量的修改替换。然而之后的转岗或新组员并不知道这个处理办法,直接在业务逻辑中添加了大量需要删除的代码。
又或者代码中可能存在不喜欢的使用方式,辛辛苦苦修改之后又需要写长篇文档来总结存档。这个时候对于增量代码来说,要么代码提交审查时逐一人工修改瑕疵,要么使用代码分析工具来查找问题代码并进行提示和修复。
多业务逻辑下的依赖治理
此外,代码分析工具同样能够解决多业务逻辑下的依赖治理问题。这里我们假设 api1 是一个公共的业务逻辑接口,里面的数据经常被不同业务使用。A 同学在开发中引入了此接口,但之后加入的同学却没有充分了解之前的代码。
这就会导致在某个需求中,他们也需要使用 api1 来获取数据,这时代码中就会存在两个或多个位置调用相同接口。这种情况会产生冗余,但如果不做特定的搜索或者被熟悉业务逻辑的同学发现,很难防范此类问题。
代码分析工具能够在每次提交前查找这个 api1 的引用情况,若存在重复使用,则会弹出警告并阻止提交。
制作一个代码分析工具的思路:
第一步,首先我们可以先讨论一些前置知识,当你的代码被解析成 AST 时都发生了什么
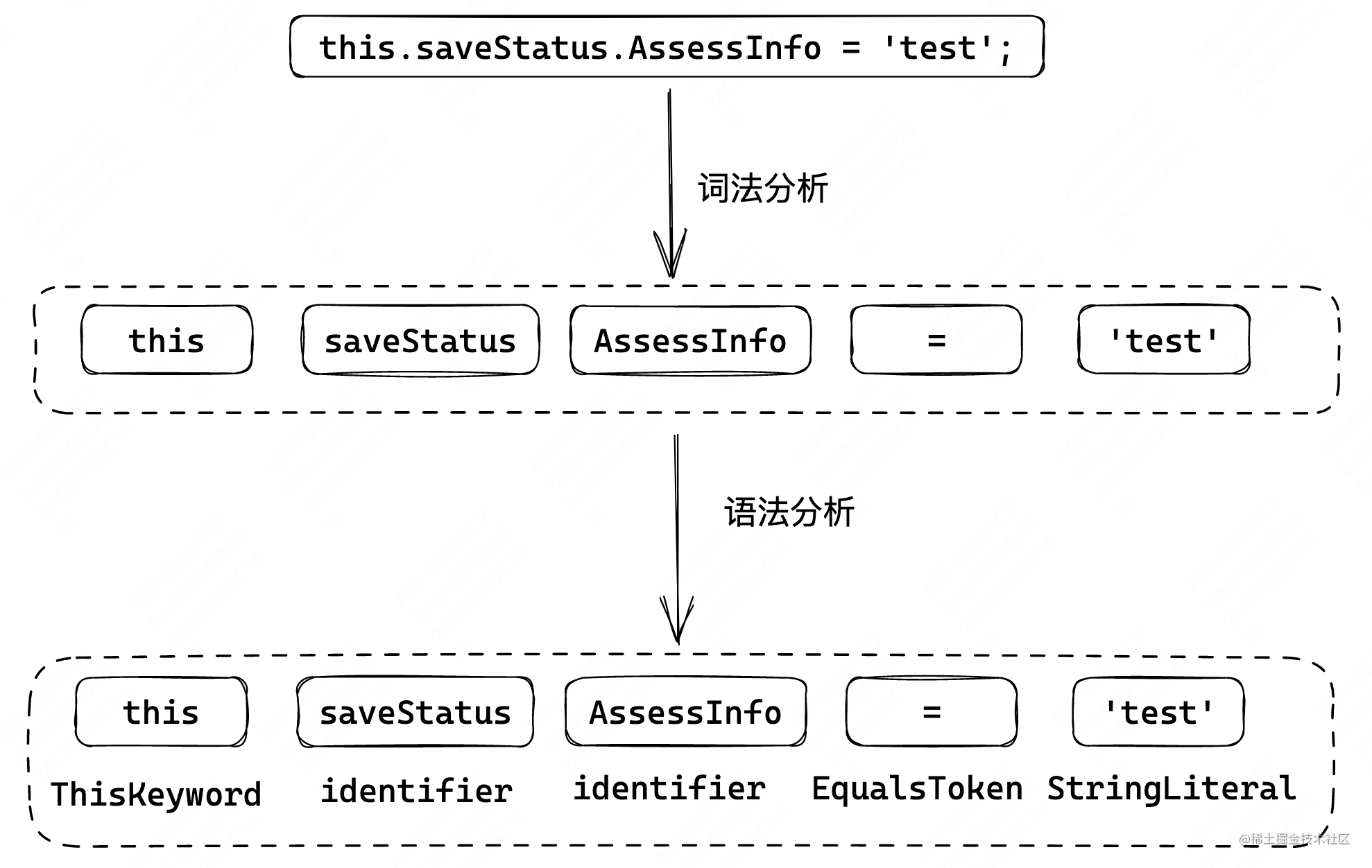
词法分析:
将输入的源代码字符串通过方法来一个一个字母的来读取字符,然后与定义好的 JavaScript 关键字符做比较,生成对应的Token。Token 是一个不可分割的最小单元。这些 Token 包括数字,标点符号,运算符等,这些词法单元之间都是独立的。最终,整个代码将被分割进一个tokens列表(或者说一维数组)。
语法分析:
语法分析会将词法分析出来的 Token 按照不同的语法结构如声明语句、赋值表达式等转化成有语法含义的抽象语法树结构。
了解了这些之后我们就可以制作需要 AST 来当做核心的代码分析工具。
设计思路:
通用的代码分析工具就是 ESLint,但是 ESLint 并不算是完全的代码分析工具,它还可以在扫描之后直接修复预制的错误逻辑,具体的方案可以参考之前写的一个文章。
在此之上我们每个项目组或者公司可能都会有自有的代码卡控平台,比如美团就有 BME/SCA,他们可以针对每个小组提供一些个性化的代码分析。
他们的原理其实都非常简单,通过内置/引入的编译工具将代码解析成 AST来做分析,然后将分析结果通过各种工具展示给开发者。 当然如果工具的作者比较肝,他可能就会加上修改的逻辑,则会在编译 & 分析的基础上来做转换逻辑,这也就是 ESLint 的修改过程。
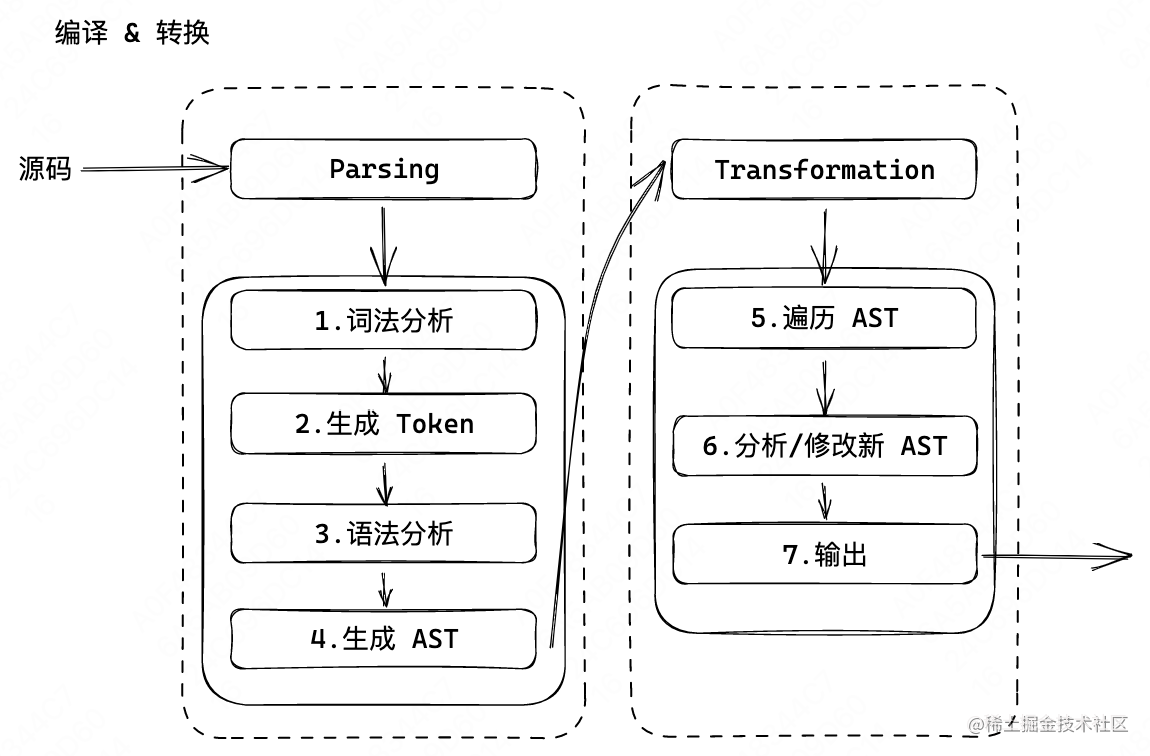
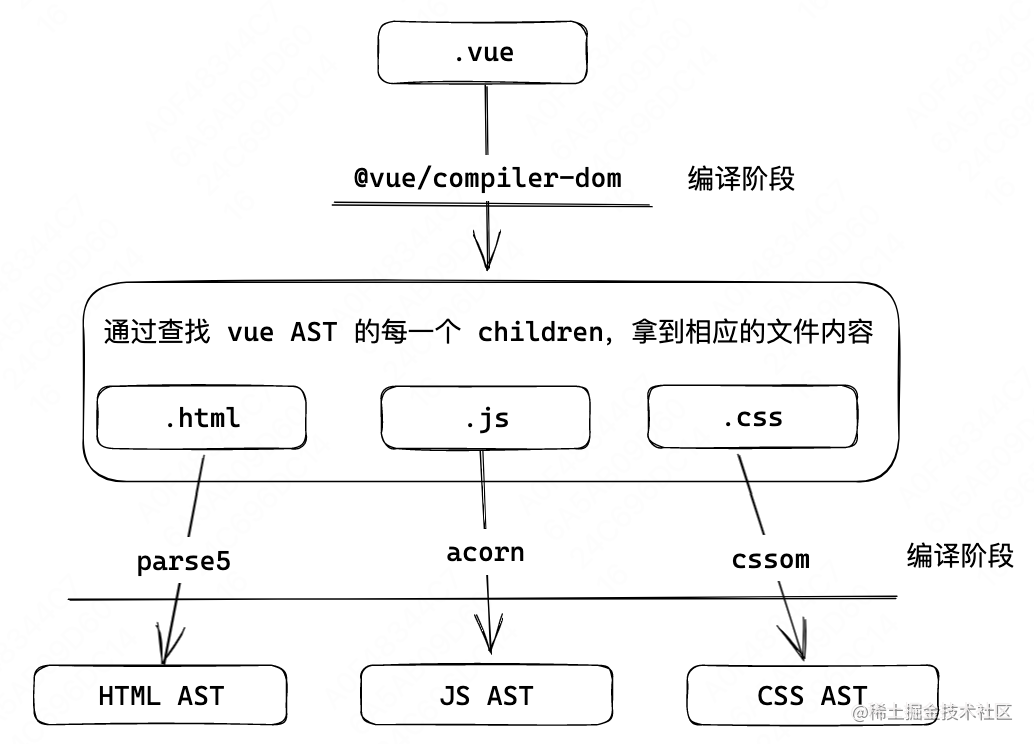
所有的分析、编译工具的核心原理都是上图。我们先不用去管具体的代码,目前只需要知道我们拿到 AST 是用来分析和编译的即可。
在代码分析工具中,我们要做的只是把文件的内容解析成 AST,拿到他的 AST 结构之后我们直接分析,并不做过多修改。
在代码编译工具中,在上图的步骤 6 对 AST 做了修改之后,我们还需要把修改后的 AST 结构编译回文件的格式,比如 ESLint 就会把拆解并修改完的结构重新组合成字符串输出。
这个过程在实际工具中更为复杂,比如现在的业务代码中基本没人直接写 JS 和 CSS,在我们项目的 Vue 文件中,一个文件由模板语言、script 标签内容、LESS 组成。那如果我们想拿到 AST 结构的话就需要更多的转化。
比如我现在手里有一个 Vue 文件,我想对他的 JS 和 CSS 做代码分析。那么我们需要先将这个 .vue 文件转换成基本的 .ts 或者 .js 文件。这里我们常用的是 @vue/compiler-dom。他会将 .vue 分成三个子对象,分别对应 template、script、style。也就是 HTML、JS、CSS。
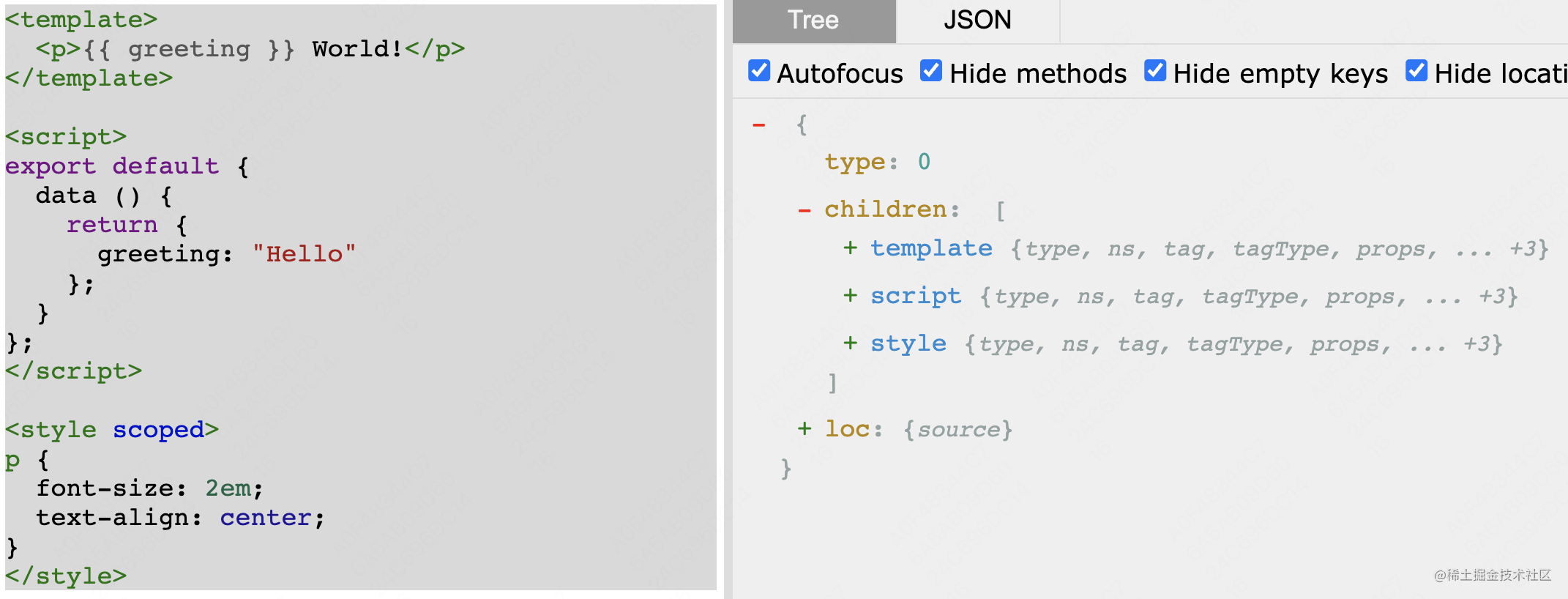
在 @vue/compiler-dom 解析的 JS 结构中,我们可以在内层的 content 字段中拿到相应的 JS 内容,我们将这个内容保存在内存或文件中。然后我们在使用相应的 JS 编译器来把这个文件的内容转换成 AST 就可以完成各种扩展语法的 AST 解析。
至此,我们结合上文就可以画出如下一个图。
但是现实中我们又并不是只有一个文件需要解析,一般情况下一个项目可能设计近百个 .vue 文件和 .ts/js 文件,那么我们就需要当前项目中的完整结构,对每一个单独的文件来进行 分析及处理。
我们想是实现一个代码分析的 CLI 工具,那么我们可以借助 node 的多线程/进程来减少这段解析的耗时。在这里我使用 work_thread 来做并行操作。我们再补上后续的分析逻辑,这个分析逻辑的核心就基本走通了。
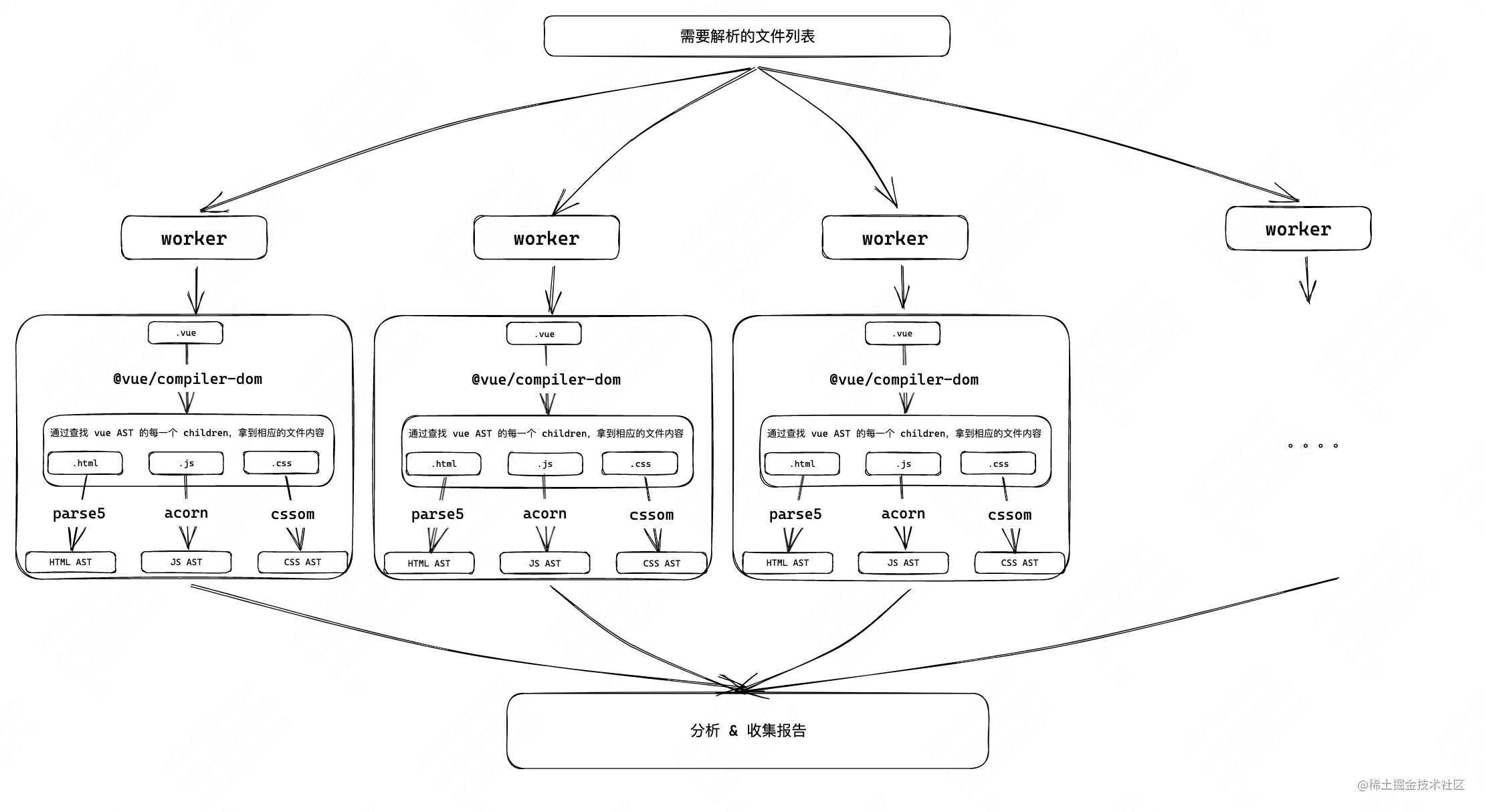
但是现阶段的各种工具,他的版本迭代不可能在一开始就想到所有的方式,都会留有一定的插槽来方便后续的扩展,所以这里我们可以用一个插件队列来控制插件的使用及时机,当然如果十分肝的话也可以加一大堆 hook .......

至此,基本的框架就已经搭好了。剩下的就是具体的工具可能会涉及到的不同的优化。
具体配置过程:
我们先从最简单的开始实现,比如我们的代码分析工具只需要扫描 TS 或者 Vue 文件,要查找到某些组内规定需要替换或以后也不许使用的方法,比如一些特定的字面量或者 TS 类型。
设置 CLI 配置 & 定位文件:
我们可以定义一个 IdentifierTarget,里面装载禁用的方法或 TS 类型。
module.exports = {
path: ["src"], // 扫描基础路径
IdentifierTarget: ["Date", "ConvertCurrentTableSchemesData"], // 要分析的方法或类型
}
拿到具体路径之后直接把所有符合的文件全数拉下来即可。
export scanFile = (path: string): string[] => {
const vueFiles = glob.sync(path.join(process.cwd(), `${scanPath}/**/*.vue`));
const tsFiles = glob.sync(path.join(process.cwd(), `${scanPath}/**/*.ts`));
const tsxFiles = glob.sync(path.join(process.cwd(), `${scanPath}/**/*.tsx`));
return {vueFiles, tsFiles, tsxFiles}
}
配置多线程 & 分析插件:
多线程配置有很多种方式,这里我们对每一个文件列表都单独使用一个 Promise.all 来控制进度,然后将 worker 的调用放入其中即可。如果文件过多还可以在分配线程之前使用队列开控制数量。
import { Worker } from "worker_threads";
const res = (await Promise.all(
scanFile.tsFiles.map((filePath) => {
return new Promise(async (resolve, reject) => {
// 如果是 vue 文件,我们可以在这个位置将 .vue 解析成 .ts,再传递给下面的代码一个 filePath 即可。
const = (await this.runPluginworker(
{
filePath,
type,
baseLine: 0, // 起始行数,针对 .vue 文件需要拆分解析的情况
hookMap: this.hookIdentifierMap,
analysisIdentifierTarget: this.IdentifierTarget,
originFilePath: "",
"../worker/identifierworker.js" // 子进程内解析 AST 的具体逻辑
)) as unknown as ReportDataType;
res = { ...identifierAnalysis };
resolve(res);
});
})
)) as unknown as ReportDataType[];
// 多线程调用
private runPluginworker = (
workerData: ReportDataType,
filePath: string
): Promise<ReturnType<ParseFilesForASTType>> => {
return new Promise((resolve, reject) => {
const worker = new Worker(path.join(__dirname, filePath), {
workerData: workerData,
});
worker.on("message", resolve);
worker.on("error", reject);
worker.on("exit", (code: number) => {
if (code !== 0)
reject(new Error(`Worker Thread stopped with exit code ${code}`));
});
});
};
在进程中,我们再会编写上面的核心代码(编译、分析),而插件中我们可以用来输出报告,当然如果你想的话也可以拿到分析的子节点继续分析。这里我们需要补充一下插件接入的逻辑。
因为我们要在子线程中执行插件,进程通信无法在非共享内存的情况下直接传递函数,因此我们可以在进程中存入插件地址,线程中拿到地址内具体的构造即可。
主进程:
this.hookIdentifierMap:Map<string, string> = new Map();
// 注册插件
private installPlugins: InstallPlugins = (plugins) => {
if (plugins.length == 0) return;
plugins.forEach((item) => {
const res = item();
if (
res.hookType == "identifierHook" &&
!this.hookIdentifierMap.has(res.mapName)
) {
this.hookIdentifierMap.set(res.mapName, res.mapPath);
}
});
};
插件的具体结构我们可以定义成这样子:
const identifierCheck: workOutsideHookFunc = () => {
const mapName = "IdentifierCheckPlugin";
const analysisDetail: workPluginContextType["queueReportReuslt"] = {};
// 在分析实例上下文挂载副作用
const isApiCheck: workCallbackFunc = (config) => {
try {
// pluginFunc 是调用具体的报告逻辑
const res = pluginFunc(config, analysisDetail);
return res;
} catch (e: any) {
return {
queueIntercept: true, // 当前插件是否会阻塞执行队列
queueReportReuslt: analysisDetail, // 当前插件的分析内容,包括行数、源文件路径、调用次数等
};
}
};
return {
mapName: mapName, // 插件名称
mapPath: path.join(__dirname, "./workIdentifierPlugin.js"), // 插件路径
pluginCallbackFunction: isApiCheck, // 插件执行函数
hookType: "identifierHook", // 插件类型
};
};
const pluginFunc: IdentifierPluginFuncType<workPluginFuncArg> = (
{ AST, baseLine, filePath, analysisIdentifierTarget, originFilePath },
analysisDetail
) => {
// 具体的报告逻辑
}
子线程使用这个插件的时候,我们拿到是主线程传递的 hookIdentifierMap 结构,这个结构中有插件的文件路径和命名,我们拿到具体的插件函数并且依次调用即可,我们首先要在子线程中拿到具体的函数:
//work.ts
const hookQueue: FuncList[] = await getFunc(hookMap);
// 获取插件函数
export async function getFunc(
hookInfoMap: Map<FilePathType, PluginFuncType>
): Promise<HookFuncReturnType> {
const afterHookFunc: HookFuncType[] = [];
hookInfoMap.forEach((value: FilePathType, key: PluginFuncType) => {
afterHookFunc.push({
value,
key,
});
});
return await Promise.all(
afterHookFunc.map((item) => {
return new Promise(async (resolve, reject) => {
const fileDetail = await import(item.value);
const fileFunc = fileDetail.default().pluginCallbackFunction;
resolve({
pluginName: item.key,
pluginFunc: fileFunc,
});
});
})
);
}
拿到了具体的插件执行函数队列之后,我们只需要在合适的位置执行我们的插件队列即可,这个合适的位置就是 AST 遍历阶段我们定位到的目标。
// 插件调用队列
function callHook(
hookQueue: FuncList[],
workInfo: workInfoType,
index: number,
reportSingleworker: ReportDataType
): ReportDataType {
if (hookQueue.length == 0) return reportSingleworker;
const ch = hookQueue[index];
const res = ch.pluginFunc(workInfo);
const { queueIntercept, queueReportReuslt } = res;
reportSingleworker[ch.pluginName] = queueReportReuslt;
if (queueIntercept && index < hookQueue.length - 1) {
return callHook(hookQueue, workInfo, index + 1, reportSingleworker);
} else {
return reportSingleworker;
}
}
具体的代码解析工作:
我们这里主要关注 Vue、TS 文件如何解析成 AST 结构。
Vue 文件如何解析成 TS 文件
通过 @vue/compiler-dom我们可以获取 Vue 解析后的内容,我们在这个内容中提取出 script 标签中的内容即可,这部分就是一个单独的 TS 文件。参照之前的 AST 结构来逐层剥离即可

import vueCompiler from "@vue/compiler-dom";
const parseVue: ParseTsType = (fileName) => {
// 获取 Vue 文件的具体内容
const vueCode = getCode(fileName);
// 解析 Vue 文件至 AST
const result = vueCompiler.parse(vueCode);
// 拿到 AST 的 chilren 参数,这里面存储了 HTML、script、style 内容
const children = result.children as any[];
// 获取 script 代码片段
let tsCode = "";
let baseLine = 0;
children.forEach((element) => {
if (element.tag && element.tag == "script") {
const _children = element.children;
tsCode = _children[0]?.content;
}
});
// 文件写到本地,等待下一步将本地的 .ts 文件解析
};
TS 文件如何解析成 AST 结构
这里我们直接调用 typescript 内置的方法就可以获取到 TS 文件的上下文结构,我们再从结构中获取我们关注的类型校验即可。
import ts from "typescript";
// 创建 tsContext 编译上下文,是 TS 代码分析的基础
const tsContext = ts.createProgram([filePath], {});
// 通过 Program 获取代码文件对应的 SourceFile 对象,也就是 AST
const AST = tsContext.getSourceFile(filePath);
// 用于通过 program 获取 Checker 控制器,该控制器用来类型检查、语义检查等;
const typeChecking = tsContext.getTypeChecker();
我们可以从 AST 结构中获取相当多的属性值,这里可以浅浅看一下:

如何在 AST 中找到目标字面量
TS 的编译方法中有一个 forEachChild 方法,这个方法会拿到当前 AST 节点下的所有子节点,并且他的第二个参数是他的回调函数,在这里我们可以接受他的子节点。
function forEachChild<T>(node: Node, cbNode: (node: Node) => T | undefined, cbNodes?: (nodes: NodeArray<Node>) => T | undefined): T | undefined;
我们可以通过递归的形式来写出一个可以由上至下查找全部子节点的函数
function dfs(node: tsCompiler.Node) {
tsCompiler.forEachChild(node, dfs);
// 这里做具体的字面量查找
}
dfs(AST as tsCompiler.Node);
在每一个找到的节点中可以继续使用 TS 提供的各种校验方法开查看是否是我们期望的字面量,比如我现在有一个 Date 字面量需要查找。我们可以通过这个网站查找到当前节点的所有内置参数。
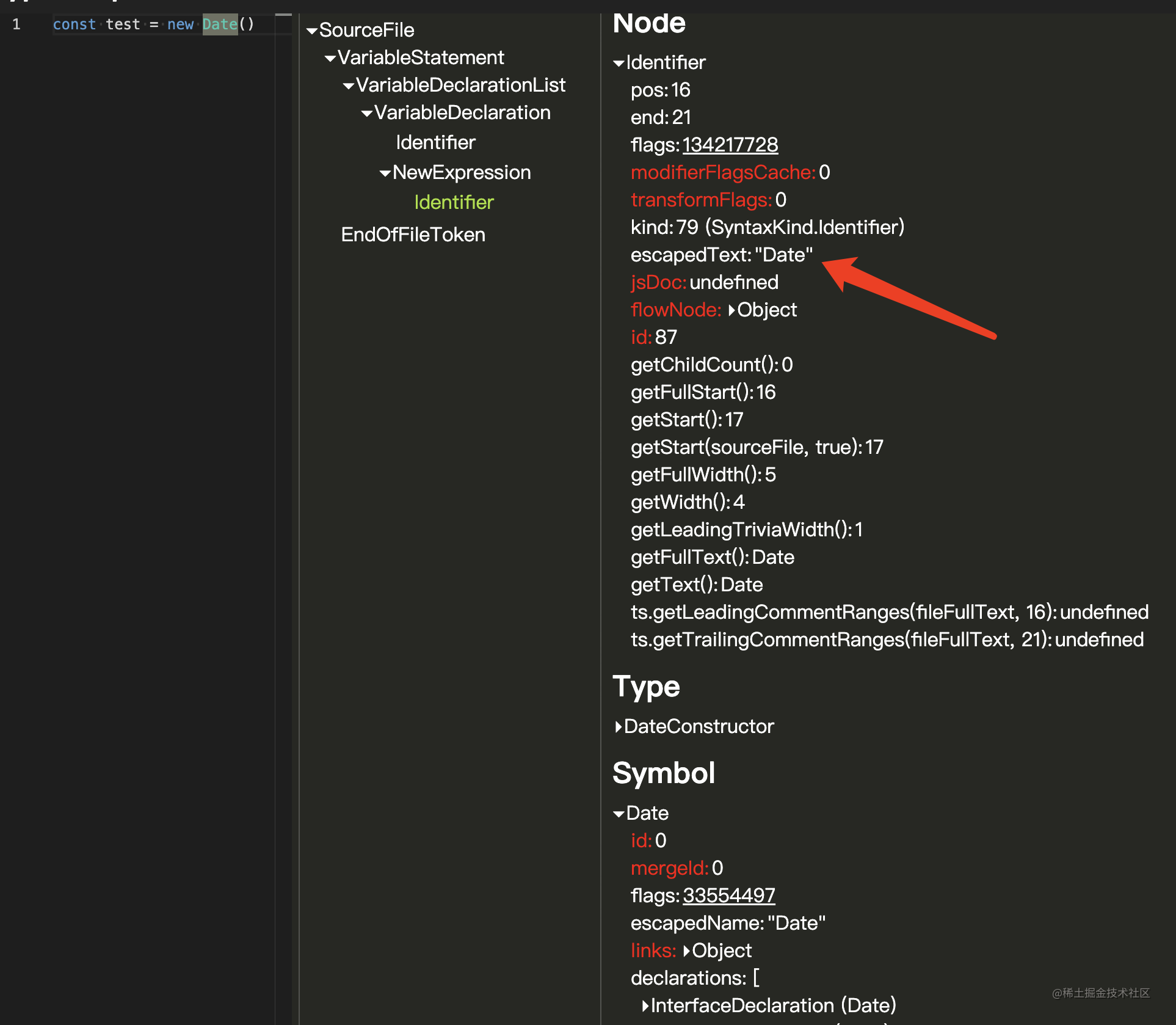
然后我们就可以 checked 到特定的目标,简化的逻辑如下:
function dfs(node: tsCompiler.Node) {
tsCompiler.forEachChild(node, dfs);
if (!AST) return analysisDetail;
if (
tsCompiler.isIdentifier(node) &&
targetIndetifier.includes(node.escapedText) // 当前节点的内容就是目标字面量
&& !tsCompiler.isTypeReferenceNode(node.parent)
&& !tsCompiler.isImportSpecifier(node.parent)
&& !Reflect.has(node, "moduleSpecifier") // 排除特殊及诶单的干扰
) {
return // 不是当前节点,返回之前的报告即可
}
// 如果是目标值,这里可以做细致的参数报告。
}
}
dfs(AST as tsCompiler.Node);
至此其实非常简单的代码分析就做完了。然后我们可以使用 table 库来优化一下输出结构即可:
import table from "table";
function reportOutput(report: ReportType) {
console.log("|-生成时间:", chalk.green(report.analysisTime));
const tableContext: any[] = [["插件名称", "详情", "", ""]];
// 拿到报告生成的对象,用 table 优化一下控制台输出就好了
Reflect.ownKeys(report["pluginAnalysis"]).forEach((item) => {
// 做具体的报告处理
}
});
const config = {
border: table.getBorderCharacters("ramac"),
columns: { }, // table 的参数配置
};
let reportOutput = table.table(tableContext, config);
console.log(reportOutput);
}

结尾
最后给大家推荐一个学习前端的平台,开通黑金卡即可观看所有视频!只需39元.
下方有联系方式