网络爬虫开发实战源码:https://github.com/MakerChen66/Python3Spider
原创不易,本文禁止抄袭、转载,多年爬虫实战开发经验总结,侵权必究!
一、requests库
爬虫利器
下载官网:https://2.python-requests.org/en/master
安装方式:
- 在命令行中输入:
pip install requests - Mac用户输入:
pip3 install requests
一个简单的例子:
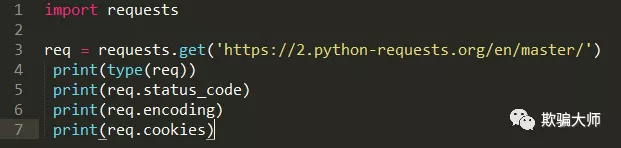
输出如下:

status:状态码
encoding:编码方式
cookies:Cookies
常用状态码:
| 状态码 | 含义 |
|---|---|
| 200 | 请求成功 |
| 301 | 资源(网页等)被永久转移到其他URL |
| 404 | 请求的资源(网页等)不存在 |
| 500 | 内部服务器错误 |
Cookies:可以理解为遗留信息 Cookies用途:
- 会话状态管理(如用户登录状态,购物车,游戏分数或其他需要记录的信息)
- 个性化设置(如用户自定义设置,主题等)
- 浏览器行为跟踪
request库 提供http的所有基本请求方式
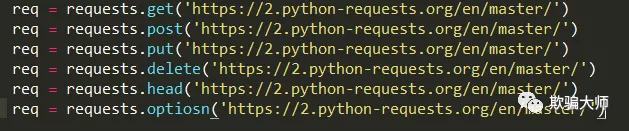
Get请求:可利用params参数为获得的网址添加参数以及参数值:

输出结果:

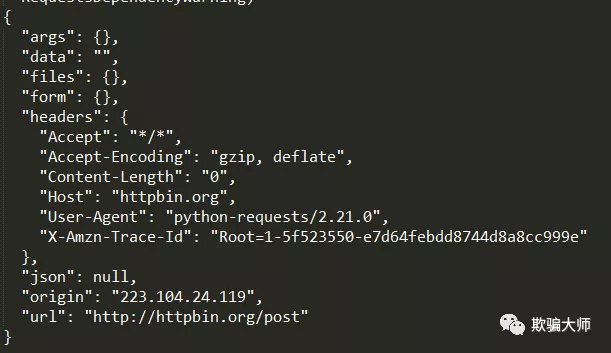
Post请求:利用data参数为post添加参数

输出结果为HTML文本形式
超时配置:利用timeout变量来配置最大请求时间

会话对象:
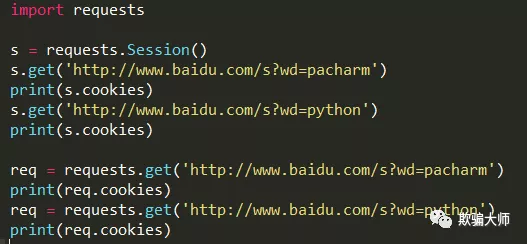
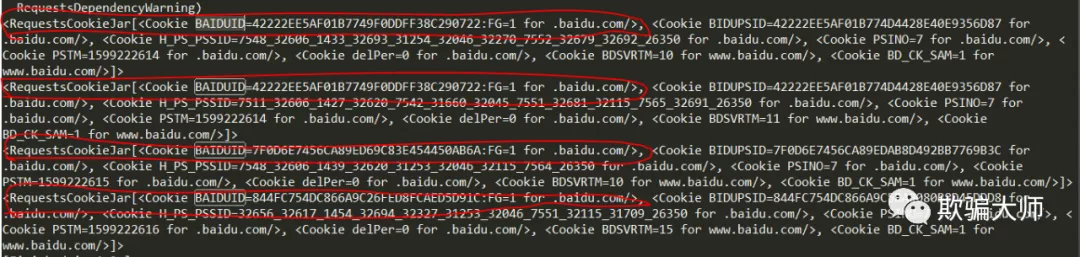
注意输出中的BAIDUID的值,体会“会话对象”的含义
设置代理:proxies参数使用代理

输出结果:
或者Windows下通过 网络设置:

Mac或者Linux下在终端输入:
export HTTP_PROXY="http://101.6.162.19"
export HTTPS_PROXY="http://101.6.162.19"
上传文件:


以上两种方法都行
二、原文链接
本人原创公众号原文链接:阅读原文
原创不易,如果觉得有点用,希望可以随手点个赞,拜谢各位老铁!
三、作者Info
作者:小鸿的摸鱼日常,Goal:让编程更有趣!
原创微信公众号:『小鸿星空科技』,专注于算法、爬虫,网站,游戏开发,数据分析、自然语言处理,AI等,期待你的关注,让我们一起成长、一起Coding!
转载说明:本文禁止抄袭、转载,违者必究!扫描二维码关注公众号,回复: 15865524 查看本文章