信息
number headings: auto, first-level 2, max 4, _.1.1
name_en: w2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training
name_ch: W2V-BERT:结合对比学习和Mask语言建模进行自监督语音预训练
paper_addr: https://ieeexplore.ieee.org/document/9688253/
doi: 10.1109/ASRU51503.2021.9688253
date_read: 2023-05-02
date_publish: 2021-12-13
tags: [‘深度学习’,‘音频’]
author: Yu-An Chung, MIT & Google Brain
1 读后感
w2v-BERT是音频的表示学习。模型可用于优化语音识别。可以看作对w2v 2.0 的延展。
2 摘要
文中提出自监督的语音表示学习w2v-BERT,它结合了对比学习和Mask语言模型,前者使用模型将输入的连续语音信号离散化为一组有限的可辨别的语音标记;后面通过Mask方法生成结合上下文的语音表示。
相对于之前模型,w2v-BERT结合了两个不同模型,实现了end-to-end 训练。w2v-BERT 优于 wav2vec 2.0 30% 以上。
3 介绍
主要贡献
- 提出 w2v-BERT,可以同时直接优化对比损失和掩码预测损失,用于端到端的自监督语音表示学习。
- 展示了 w2v-BERT 在 LibriSpeech 任务上产生了最先进的性能。
- 展示了 w2v-BERT 在真实世界识别任务(语音搜索)任务中,对于wav2vec 2.0 的明显优势。
- 经验上证实了对比学习和Mask预测的必要性。
4 方法
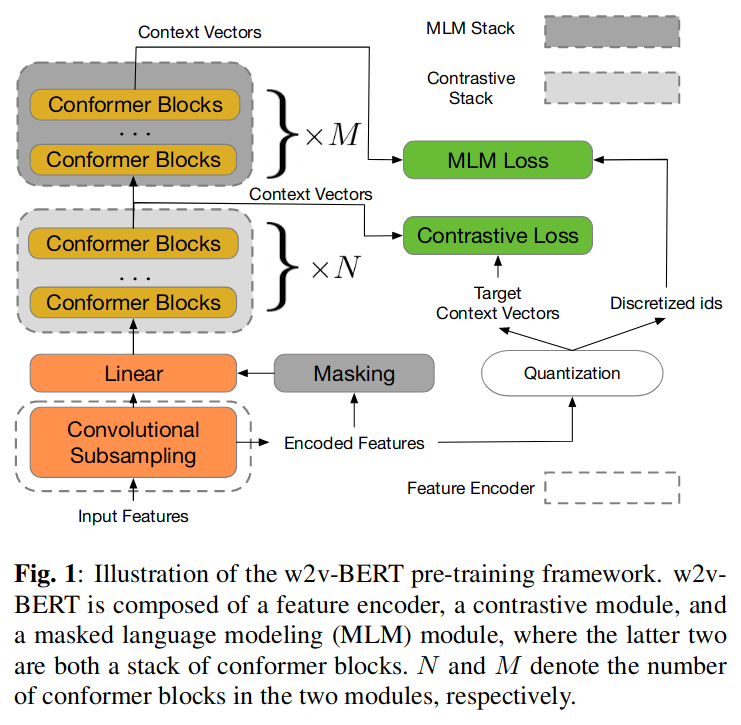
4.1 模型结构
4.1.1 特征编码器
由两个 2D 卷积层组成,使声学输入序列长度减少到1/4。例如:给定一个 log-mel 声谱图作为输入,特征编码器提取潜在的语音表示,这些表示将被后续的对比学习模块作为输入。
4.1.2 对比学习模块
包含一个线性映射层,及多个Conformer层,每个块都是一系列多头自注意力、深度卷积和前馈层。
对比模块的目标是将特征编码器输出离散化为一组有限的代表性语音单元。对比模块涉及量化机制。另外,在没有Mask的情况下被传递到量化器以产生量化向量和分配token。量化向量结合mask位置对应的context vector来解决 wav2vec 2.0 中定义的对比任务优化;分配的 token ID 稍后将被后续的掩码预测模块用作预测目标。
4.1.3 Mask预测模块
使用BERT中的Mask方式,利用对比学习的输出,学习语音中高层级的上下文之间的关系。
4.2 预训练
4.2.1 对比学习损失
(简单地说:Mask掉小段,并给出一些随机产生小段,用对比学习,通过上下文猜那个小段是对的)
对比损失用于与量化器一起训练对比模块,其具体方法使用与wav2vec 2.0一样的量化机制。
随机选择一些时间步长进行掩蔽。用随机向量替换它们。屏蔽特征编码器的输出被馈送到对比模块以生成上下文向量。同时,特征编码器的输出也被传递给量化器而不进行Mask以产生其量化向量。对于对应于Mask时间步长 t 的上下文向量 ct,要求模型从一组 K 干扰项 { ̃ q1, ̃ q2, …, ̃ qK } 中识别其真实的量化向量 qt,将损失表示为 Lw,并用码本多样性损失 Ld 进一步扩大它,以鼓励统一的代码。对比损失定义为:
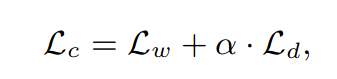
4.2.2 Mask预测损失
对比模块产生的上下文向量直接传递给掩码预测模块,用于生成最终的上下文向量,以完成掩码预测任务。一个 softmax 层附加在模块的最后一个 conformer 块之上。如果最后一层的上下文向量对应于掩码位置,则 softmax 层会将上下文向量作为输入并尝试预测其对应的标记 ID,该标记 ID 是先前由量化器在对比模块中分配的。将此屏蔽预测任务的交叉熵损失表示为 Lm。
w2v-BERT 经过训练可以同时解决两个自监督任务,最终要最小化的训练损失为:
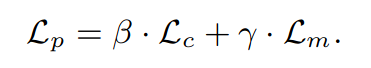
4.3 精调
使用有标签数据 LibriSpeech和voice search。训练语音识别ASR任务,ASR 网络由预训练的 w2v-BERT 模型和 LSTM 解码器组成。在二者之间插入一个带有 Swish 激活 和批量归一化的线性层作为投影块。
5 相关知识
- Conformer 模型:一种混合了卷积神经网络和 Transformer 的模型
- log-mel 声谱:其过程包括将语音信号进行短时傅里叶变换(STFT)得到频谱,再将频谱转换为Mel频率尺度,最后再对Mel频率尺度取对数(log)得到log-mel声谱。