文章包括了对logit蒸馏损失计算方法的改进,并基于改进后的公式提出了定制的软标签,用于实现自蒸馏。代码已开源。搬来大佬的啊 勿怪啊 就为自己学习~~
这里介绍ICCV 2023关于知识蒸馏的工作: From Knowledge Distillation to Self-Knowledge Distillation: A Unified Approach with Normalized Loss and Customized Soft Labels, 文章包括了对logit蒸馏损失计算方法的改进,并基于改进后的公式提出了定制的软标签,用于实现自蒸馏。
文章链接:https://arxiv.org/abs/2303.13005
代码链接:https://github.com/yzd-v/cls_KD
原生蒸馏使用教师的logits作为软标签,与学生的输出计算蒸馏损失。自蒸馏则试图在缺乏教师模型的条件下,通过设计的额外分支或者特殊的分布来获得软标签,再与学生的输出计算蒸馏损失。二者的差异在于获得软标签的方式不同。 whaosoft aiot http://143ai.com
这篇文章旨在,1)改进计算蒸馏损失的方法,使得学生能更好地使用软标签。2)提出一种通用的高效简单的方法获得更好的软标签,用于提升自蒸馏的性能和通用性。针对这两个目标,我们分别提出了Normalized KD(NKD)和Universal Self-Knowledge Distillation (USKD)。
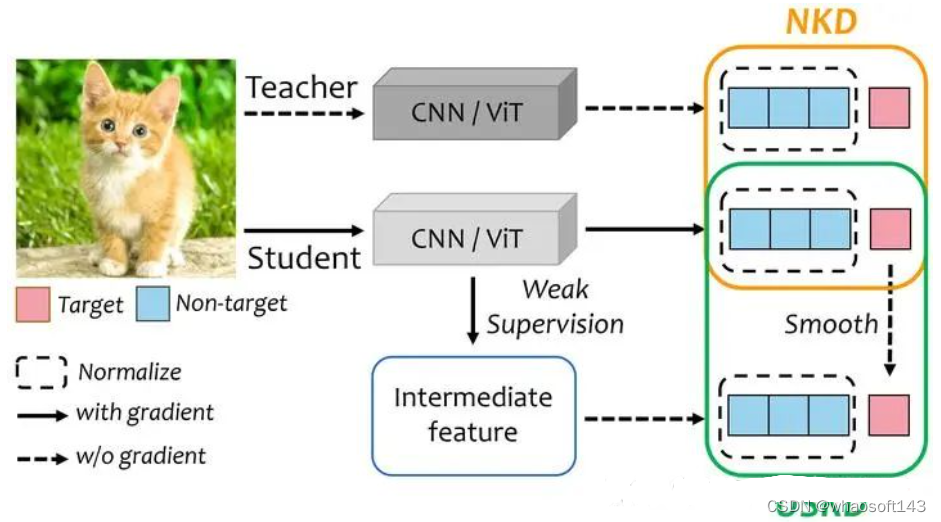 方法与细节
方法与细节
1)NKD
 2)USKD
2)USKD
 实验
实验
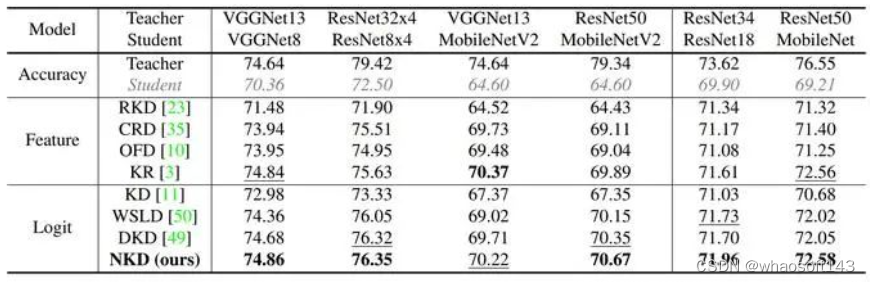
我们首先在CIFAR-100和ImageNet上对NKD进行了验证,学生更好地利用了老师的软标签soft labels,获得了更好的表现。
 对于自蒸馏,我们也在CIFAR-100和ImageNet上对USKD进行了验证,并测试了自蒸馏所需要的额外训练时间,模型在很少的时间消耗下便获得了可观的提升。
对于自蒸馏,我们也在CIFAR-100和ImageNet上对USKD进行了验证,并测试了自蒸馏所需要的额外训练时间,模型在很少的时间消耗下便获得了可观的提升。
 我们的NKD和USKD同时适用于CNN模型与ViT模型,因此我们还在更多模型上进行了验证。
我们的NKD和USKD同时适用于CNN模型与ViT模型,因此我们还在更多模型上进行了验证。
 代码:https://github.com/yzd-v/cls_KD
代码:https://github.com/yzd-v/cls_KD