视觉弱监督学习研究进展 (wanfangdata.com.cn)
视觉弱监督学习研究进展
一、回顾通用弱监督学习模型
1、多示例学习(multiple instance 1earning,MIL)
2、期望一最大化(expectation_maximization,EM)
二、针对物体检测和定位
1、弱监督物体检测可以转化为基于 MIL的候选框分类问题
WSDDN(weakly supervised deep detection networks)
类注意力图机制
白训练和监督形式转换
菜狗看不进去忽略,可以用边界框标注的标签进行语义分割
三、语义分割任务
3.1、基于边界框标注的弱监督语义分割

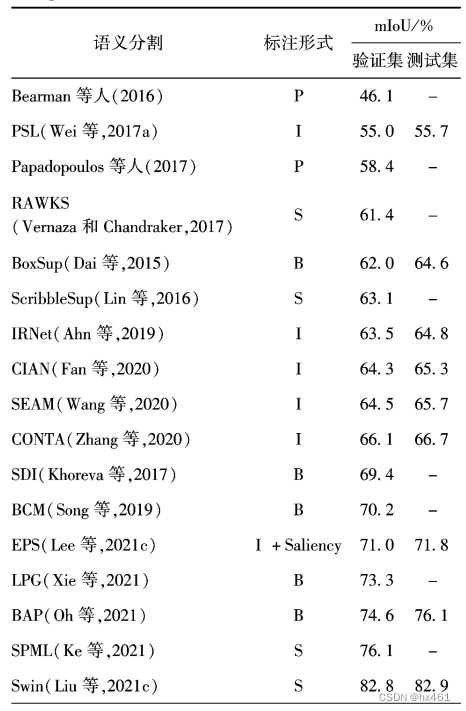
1、近期文章例子
MCG (Arbelaez等,2014)等来提取一系列候选区域,然后 从中选择一个与边界框有最大重叠部分的候选区域 作为初始阶段的伪标签.然后通过迭代训练的方式逐渐优化伪标签。在每轮迭代中,首先使用伪标签训练网络分割模型, 然后进行预测,从每个边界框得分最高的几个候选区域中随机选出 一个作为新的伪标签参与下一轮的迭代过程。
| 2021 0h等人 |
背景感知池化BAP(background aware pool)噪声感知损失NAL((noise-aware loss) |
BAP方法使用注意力图来区分边界框的前景与背景部分,通过聚合前景区域的特征并去除背景区域,获得更为精确的类激活图 CAM,再结合注意力图与cAM使用DensecRF后处理生成伪标签;NAL方法通过自适应地使用网络输出、中问层特征以及分类器的权重计算交叉熵损失, 使用中间层特征的相似度产生第2种伪标签,并在两种伪标签不同的区域使用特征相似度对交叉熵损失加权来抑制伪标签中错误信息的影响 |
| 2021 xie等人 |
基于学习的伪标签生成 器LPG(learned proposal genemtor) |
使用COCO数据集作为辅助数据集,使用其中与PASCAL VOC2012数据集中不相交的60类物体来学习一个类别无关的能够用在任意给出边界框标注的数据集上提取候选区域的模型。引入了两层优化模型来对分割 模型与候选区域提取器进行训练。其中训练分割模型定义为下层问题,训练基于边界框的候选区域提取器定义为上层问题,使用EM算法将LPG与分割模型联合训练.在多个阶段的训练过程中不断优化伪标签,并用于分割模型的训练 |
| 2019 Song等 |
BCM (box driven class-wise masking) 自适应的填充率指导损失 |
通过Dense- CRF得到预选标签,用来计算物体在边界框内的平均填充率,并且输入一个基于全卷积网络的分割网络。然后将分割网络的输出中每个类别的特征图乘上对应类别的掩膜,再根据所属类别的平均填充率 约束最后的网络输出。 |
2、存在问题与发展
问题:第1阶段中生成的伪标签的精度还不够高
发展:抑制伪标签中错误信息的影响以及将分割结果的先验信息与网络结构相融合
3.2 基于图像级标注的弱监督语义分割
如果这个图像中包含某类物体, 则至少含有该类物体的一个像素,即正示例,而如果图像不包含某类物体,则每个像素一定不属于该类物体,即负示例。首先将图像经过一个OverFeat(Sermanet等,2014)卷积神经网络,得到分数图,再对这个分数图通过一个聚合层 聚合。再用物体类别标注来训练模型,使得分类正确 的像素能有更高的权重,同时还会使用3种平滑策 略来对输出的预测结果进行平滑。
以类激活图CAM方法为基础,一些方法(Hou等,2018; Mai等,2020;wei等,2017a)在迭代训练的过程中每次将网络分类得到的响应值大的区域先删除,然 后对剩余区域再次进行多类学习,将新得到的响应值大的区域加入到分割预测结果中,直到分割预测结果不再变化为止.
Lee等人(2021c)提出的EPs(explicit pseudo— pixel supervision)方法同样结合了CAM与显著性 图,考虑到cAM可以区分物体,但是边界不够清晰, 而显著性图的边界足够清晰但是无法区分具体的物 体类别,EPs引入了显著性损失来使用显著性图为 CAM中的前景部分获取准确的边界信息。
Ahn和Kwak(2018)提出的PSA(pixel—level semantic affinitv)方法,设计了亲和度网络Affinitv. Net来预测相邻像素的语义相似度,在cAM的可信 区域中抽取相邻像素作为训练数据,生成了更为准确的分割伪标
Ahn等人 (2019)又设计了一个具有两个分支的IRNet,其中 一个分支用来预测物体的像素位移场,并以此为基 础为每个实例生成cAM:而另一个分支用来预测物 体的边界,得到像素对问的相似度关系。通过对两 个分支所得结果进行融合和处理得到最终的分割结 果。同时该方法还引入了随机游走,根据亲和度矩 阵对所得预测结果进行传播来优化网络预测的分割 结果。
zhang等人(2020)提出 的CONTA(context adiustment)通过因果干预的方法来消除不属于 物体的上下文特征对cAM的影响,从而提高了伪标 签的精度。
3.3 线标注
Lin等人(2016)提出了Sc曲bleSup方法,首先 基于线标注生成超像素,然后再基于GrabCut算法 通过能量函数来对超像素进行传播,并且采用了 EM算法的思想,交替更新分割模型以及训练分割 模型的标签,直至模型收敛。
Vernaza和Chandmker (2017)提出的RAwKS(random.walk weakly.supe卜 vised segmentation)方法通过训练一个一致性网络将 稀疏的线标注传播到物体区域,提出了使用一个特 定的概率模型用于稀疏标签传播,且这一模型在进 行语义边缘检测训练时是可微的,即随机游走,极大 地提高了使用线标注获取伪标签的精度。
Ke等人 (202 1)提出的SPML(semi—supervised pixel—wise metric leaming)使用segson(Hwang等,2019)作为 骨干网络,同时使用HED轮廓检测器作为额外的监 督信息,引人了一个像素级的特征一致性损失。使得 具有相近语义的像素映射到特征空间后具有较近的 距离,而属于不同语义的像素映射到特征空间后相 互远离。现有方法通常约束颜色相近像素具有相似 的特征,可能会误导网络的学习。
针对这一问题, zhang等人(2021a)提出了动态特征正则化(dyn籼ic feature regularization,DFR)损失,仅在一个小的窗口 内约束颜色相近的像素对特征相似,同时还设计了 特征一致性模块,通过选取模型预测置信度高的像 素级特征作为监督。要求窗口与其属于同类别的像 素具有与其相似的特征,DFR损失与特征一致性 模块均可以直接应用到其他弱监督语义分割方 法中。
四、精度