Datawhale202211李宏毅《机器学习》(深度学习方向)P5-P8——误差与梯度下降
文章目录
前言
本节介绍误差和梯度的相关知识,这是模型训练的基础,同时也会看到一些训练过程中问题的应对策略,比较偏理论。
一、误差
误差哪里来
Error——整个模型的准确度;
Bias——模型在样本上的输出与真实值之间的误差;
Variance——模型每一次输出结果与模型输出前往之间的误差(稳定性)
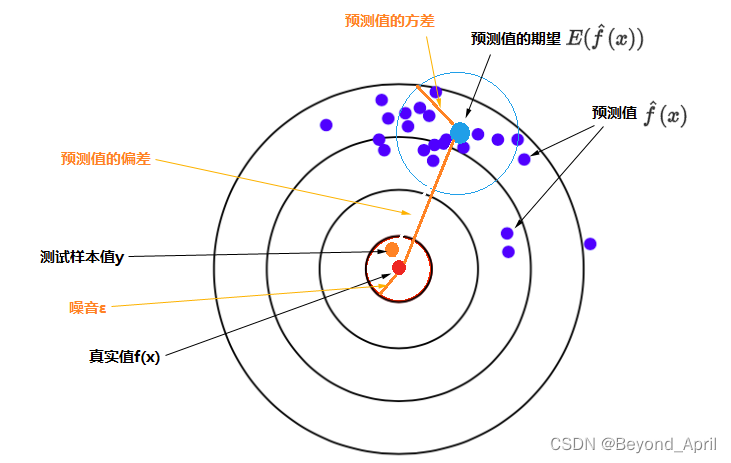
实际实验过程中,Bias和Variance往往不能兼得。我们试图用有限训练样本去估计无限的真实数据,当我们相信数据的真实性时容易忽略对模型的鲜艳知识,通过保证模型在训练样本上的准确度来减少模型的Bias,容易过拟合,增加模型的不确定性;如果我们更倾向于模型的先验知识,就会通过增加限制来提升稳定性,这样会使Bias增大。因此trade-off偏差和方差是重要课题。
估测
- 评估x的偏差
假设x的平均值是μ,方差为σ^2,评估平均值
- 拿到样本点N个
- 计算平均值m(m≠μ)
- 计算多组m并求期望E(m)
- 求方差
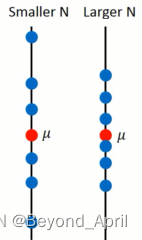
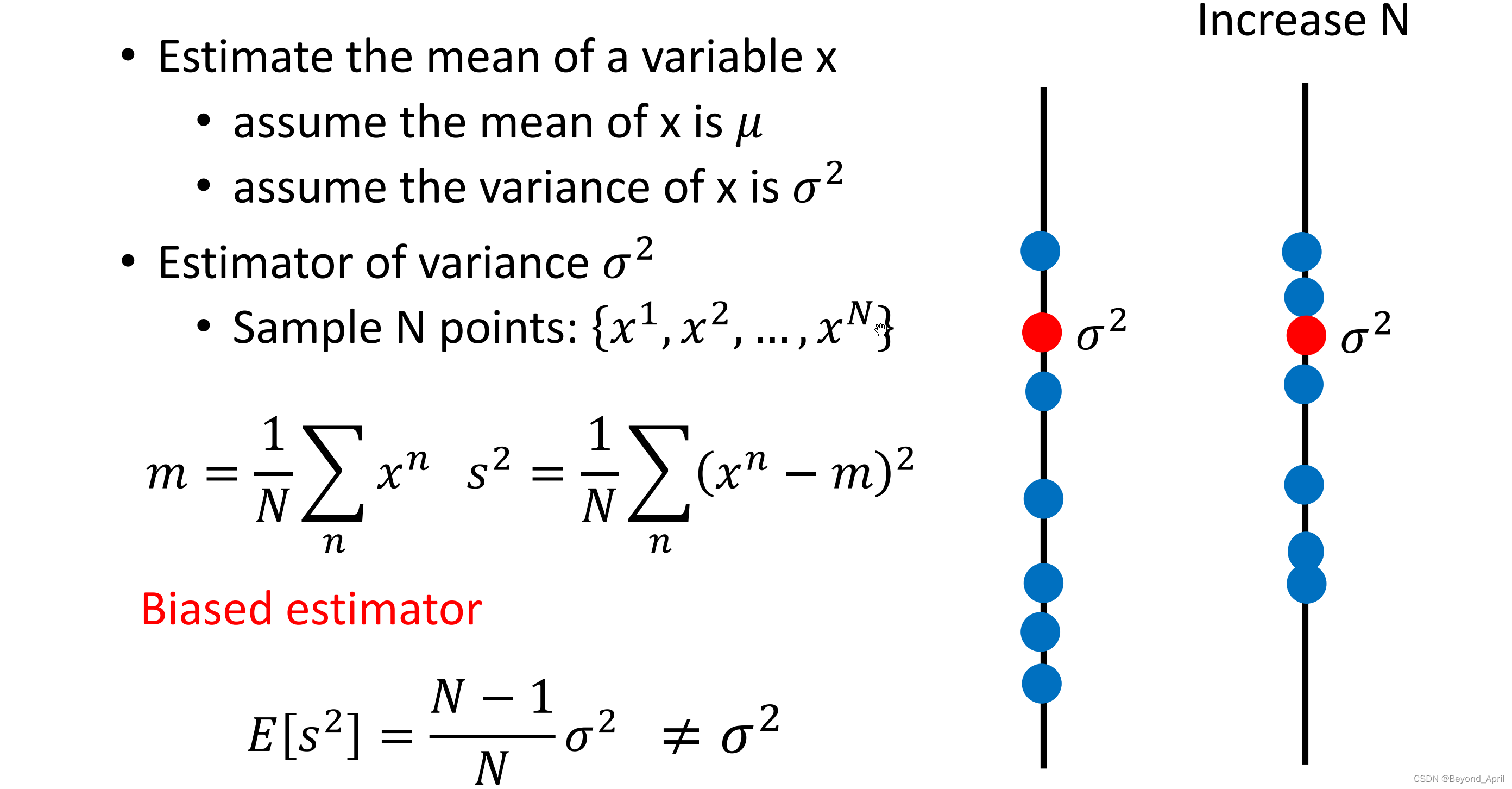
- 评估x的方差
判断
没有好的训练集-偏差过大-欠拟合
训练集良好,在测试集问题大-方差大-过拟合
- 偏差大—欠拟合
-重新设计模型
- 加入更多参数或考虑更加复杂的模型
- 方差大—过拟合
- 用更多的数据训练
- 数据集增广:裁剪、shift……
选择
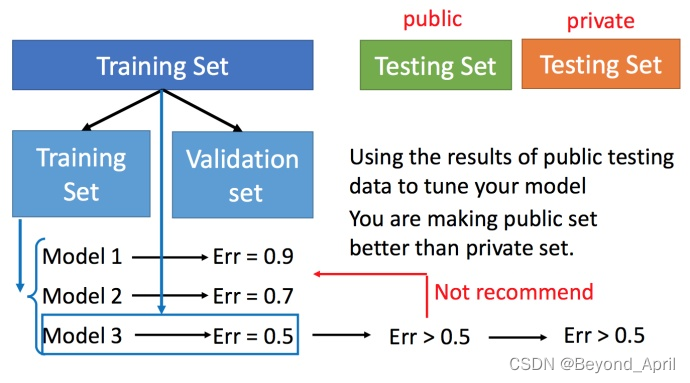
- 交叉验证
交叉验证 就是将训练集再分为两部分,一部分作为训练集,一部分作为验证集。
- 用新划分的训练集和验证集确定模型
- 再用全部的训练集和验证机实验模型并做出调整
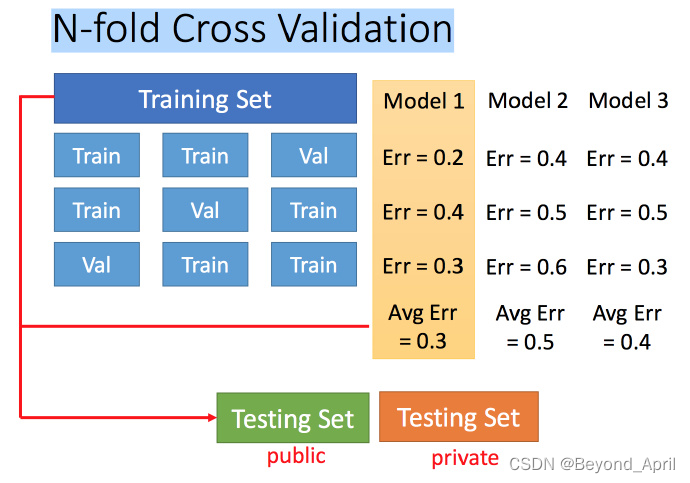
- N-折交叉验证
- 把训练集分成多份,分别训练得出多个模型
- 选择Average最好的一个全局训练
二、梯度下降
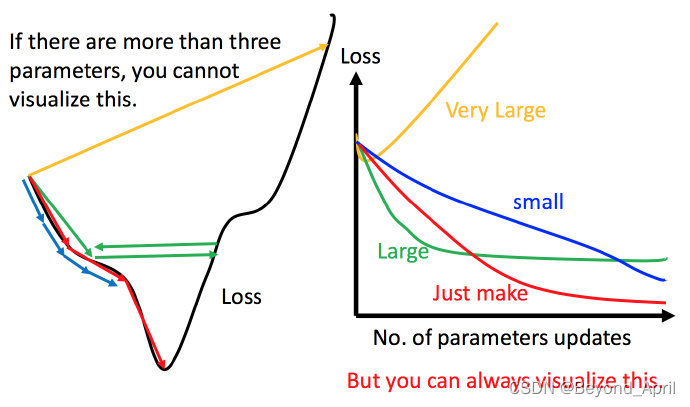
调整学习速率
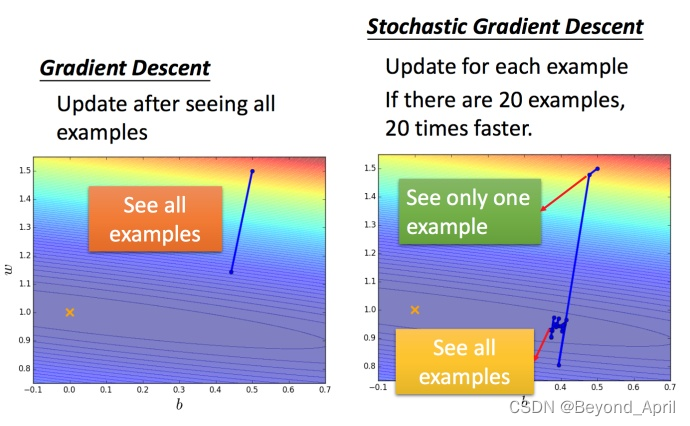
随机梯度下降法
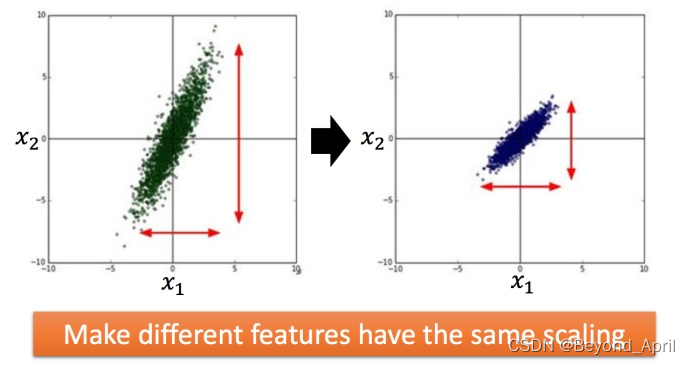
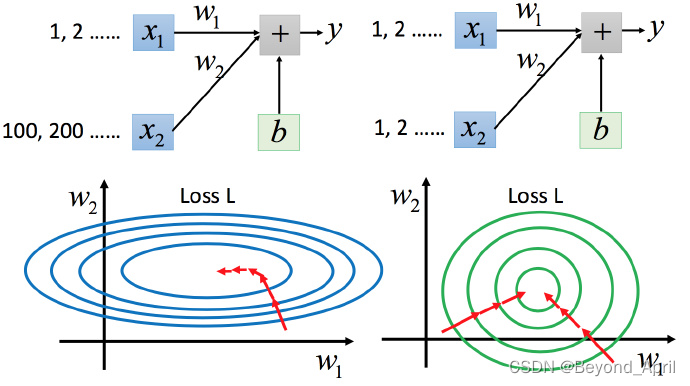
特征缩放
三、参考文档
来自Datawhale的投喂
李宏毅《机器学习》开源内容1:
https://linklearner.com/datawhale-homepage/#/learn/detail/93
李宏毅《机器学习》开源内容2:
https://github.com/datawhalechina/leeml-notes
李宏毅《机器学习》开源内容3:
https://gitee.com/datawhalechina/leeml-notes
来自官方的投喂
李宏毅《机器学习》官方地址
http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
李沐《动手学深度学习》官方地址
https://zh-v2.d2l.ai/
来自广大网友的投喂
梯度基础知识参考
https://blog.csdn.net/weixin_50967907/article/details/127259554
总结
1.本课程非常适合新手,把每个步骤的内在逻辑都解释得非常到位。
2.可惜的是很多概念不通过实战很难快速get,可以自己搭配一些实战练习,后面有机会续上。
3.感谢datawhale小伙伴们的倾力支持,特别是组内的支持和帮助,再接再厉。