论文地址:http://arxiv.org/abs/2004.05937
github地址:无
这是篇关于知识蒸馏的综述文章。知识蒸馏被认为是用于模型压缩的非常有效的一种方式。本文作者从模型压缩和知识迁移两个应用场景概述了近年来对知识蒸馏的研究。
Outlines
知识蒸馏的定义
由Hinton等人提出,表示较小规模的学生网络的训练过程由较大规模的教师网络的监督进行。其目标函数可表示为:
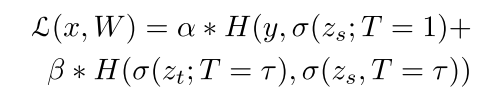
其中H为损失函数类型,y是真实标签, σ \sigma σ是含有温控系数 T T T的softmax函数, z s , z t z_s, z_t zs,zt分别是学生网络和教师网络的logits向量。
KD理论分析
基于贝叶斯准则,两个特征表示之间的互信息可表示为如下形式:
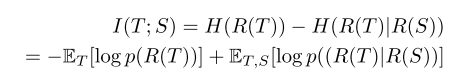
其中 R ( T ) , R ( S ) R(T), R(S) R(T),R(S)为学生网络和教师网络的特征表示向量, H ( ⋅ ) H(·) H(⋅)为熵函数。理论上通过最大化 E T , S [ log p ( ( R ( T ) ∣ R ( S ) ) ] E_{T,S}[\text{log }p((R(T)|R(S))] ET,S[log p((R(T)∣R(S))]对应的学生网络参数能够提高互信息的下确界,然而实际 p ( ( R ( T ) ∣ R ( S ) ) ] p((R(T)|R(S))] p((R(T)∣R(S))]的真实分布是不知道的,因此使用已有的变量分布来估计该项。由此上式可写为:
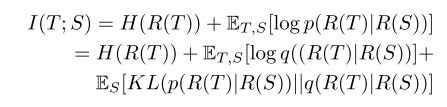
假设对q等进行充分建模,则根据吉布斯不等式,上式可改为: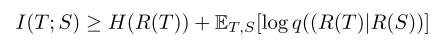
改式量化了由学生网络从教师网络中学到的知识量。由于 H ( ⋅ ) H(·) H(⋅)与学生网络的待优化参数无关,为常量,因此只需通过建模 q q q即可得到下确界。建模一般可由高斯分布,蒙特卡洛估计或噪声对比估计得到。
由上式可看出,教师网络和学生网络的特征表示之间的联系对所学的知识量起到重要影响。
分类
- 从一个教师网络中进行蒸馏
-
来自于logits的知识
标签软化和正则化
标签软化用于提取类别之间更丰富的内在关联信息,同时也防止了学生过度学习知识。另外,加入对教师训练的正则化约束也能防止学生网络的过拟合。噪声标签学习
通过对样本增加噪声来增强的原本小而干净的数据集,从而学习到更好的视觉特征与相应的分类器严格蒸馏
通过对待蒸馏的知识进行进一步的要求,如知识的扩充等加强多方面知识的学习,从而避免学生的过拟合,并获得更好的表现。蒸馏集合
单个教师模型的知识存在不确定性,而通过使用多个教师模型的知识可以消除这种不确定性,因此使用多个教师模型的知识平均来蒸馏学生模型可以获得更好的表现。 -
从中间层蒸馏
教师知识的变换
通过将教师网络的中间层的信息尺寸匹配到学生模型的相关尺寸来进行蒸馏。此时,知识存在失真情况。学生信息的变换
通过将学生的中间层信息尺寸匹配到教师模型的相关尺寸来进行蒸馏。另一种变换方式是提取出学生网络的局部中间层信息与教师网络的相应特征表示进行匹配。蒸馏层的位置选择
待蒸馏层的位置选择目前存在三种,任意选择,每个卷积组的最后一层输出层,最后一个卷积组的最后一层输出层。不同位置的选择对最终的蒸馏效果会有较大区别。蒸馏的度量指标
常见度量指标为L1度量,L2度量,也存在一些对抗蒸馏的度量方式。
- 以对抗的方式进行蒸馏
- 基于常规GAN的蒸馏
使用判决器来学习知识的分布,学生网络的logits向量与教师网络的logits向量作为判决器输入进行判别。常用于输出层
- 基于CGAN的蒸馏
将
- 基于TripleGAN的蒸馏
待更新
- 图表示方式的蒸馏
- 定义
待更新
- 基于图表示的蒸馏
待更新
- 从多个教师网络中进行蒸馏
待更新
- 在线蒸馏
待更新
- data-free的蒸馏
待更新
- 少量样本的蒸馏
待更新
- 自蒸馏
待更新
- 跨模型的蒸馏
待更新
- 半/自监督学习中的蒸馏
待更新
- 采用新学习方式的蒸馏
待更新
应用场景
待更新
讨论
待更新
展望
待更新