1. 引子
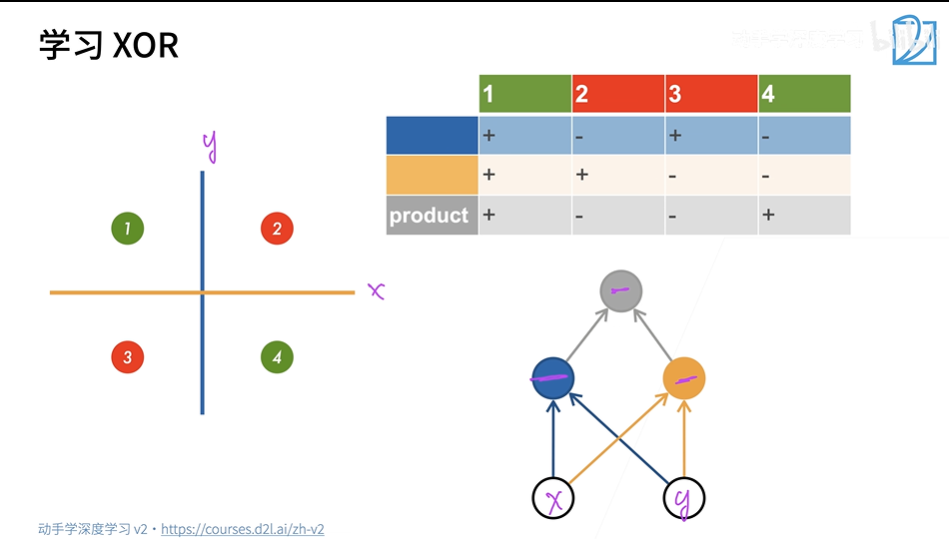
**XOR函数(异或逻辑)**是两个二进制x1和x2的运算,XOR函数只有4个数据,x1和x2相同,则输出0,x1和x2不同则输出1。
由于感知机是线性分类模型,而线性模型不能拟合XOR函数,因为不可能画一条线能把上图的四个点分成两类。
因此,我们引入多层感知机(MLP)的概念,也称为人工神经网络(ANN,Artificial Neural Network)。
如下图所示,我们使用了两个神经元分别划出 x 和 y 两条线。我们对每个神经元拟合出的数据进行叠加,从而完成XOR函数的拟合。
2. 单隐藏层
上述两个神经元所处的层就称为隐藏层。其中,输入层的输入为X,隐藏层的输出是f (W1X+b1),我们用 h 来表示。ω 代表权重,将输入的变量映射到了一个新的维度空间中,b 称为偏置量,它使得映射后的数据具有平移能力。
多层感知机由输入层、隐藏层和输出层构成。
隐藏层可以有一或多个,且各层间是全连接的,即我们将许多全连接层堆叠在一起,每一层都输出到上面的层,直到生成最后的输出。
通常情况下,我们只需要一个隐层,就可以模拟任何我们想要的函数。下面是一个单隐藏层的示例:
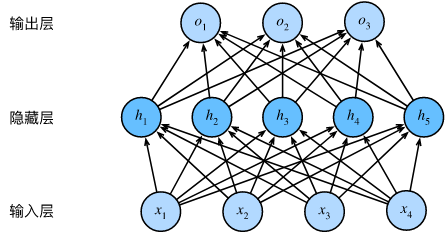
这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。由于输入层不参与计算,所以这个多层感知机的层数为2。
上文提到过用h来代表隐藏层的输出,它也称为隐藏层变量 (hidden-layer variable) 或 隐藏变量 (hidden variable)。将其作为输出层的传入参数,进而我们就可以计算出多层感知机的输出 o。

然而,隐藏单元由输入的仿射函数给出, 而输出的也只是隐藏单元的仿射函数。 仿射函数的仿射函数本身就是仿射函数, 但是我们之前的线性模型已经能够表示任何仿射函数。通俗来讲,就是在这种情况下每一层输出都是上层输入的线性函数,就相当于原始的感知机了。
因此,为了发挥多层架构的潜力, 我们还需要在仿射变换之后对每个隐藏单元应用非线性的 激活函数 (activation function)σ。激活函数的输出被称为 活性值 (activations)。 一般来说,有了激活函数,就不可能再将我们的多层感知机退化成线性模型。
3. 激活函数
**激活函数 (activation function)**通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。通俗来讲,激活函数可以把输入的特征保留并映射出来,同时过滤掉不需要的特征。此外, 大多数激活函数都是非线性的。

下面简要介绍一些常见的激活函数。
3.1 sigmoid函数
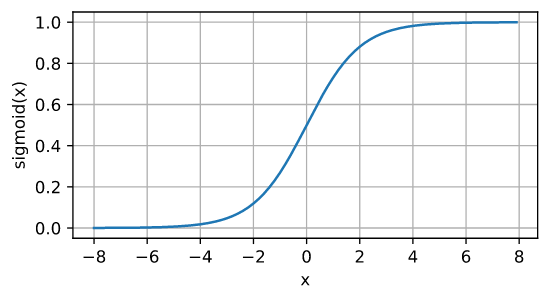
也称为 挤压函数 (squashing function)。对于一个定义域在 R \mathbb{R} R中的输入, sigmoid函数将输入变换为区间(0, 1)上的输出。
sigmoid ( x ) = 1 1 + exp ( − x ) . \operatorname{sigmoid}(x) = \frac{1}{1 + \exp(-x)}. sigmoid(x)=1+exp(−x)1.
其函数图像为:
导数图像:
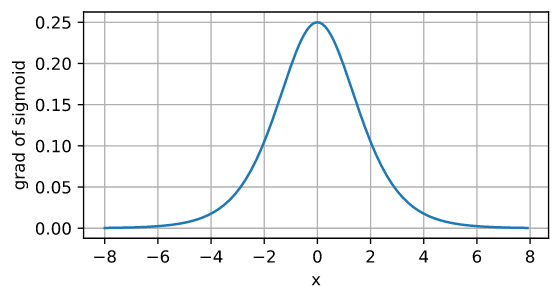
注意,当输入为0时,sigmoid函数的导数达到最大值0.25; 而输入在任一方向上越远离0点时,导数越接近0。由于只有在0附近的时候才有比较好的激活性,在正负饱和区的梯度都接近于0,这会造成梯度弥散,而relu函数在大于0的部分梯度为常数,所以不会产生梯度弥散现象。
综上,sigmoid在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的ReLU所取代。
3.2 Tanh函数
与sigmoid函数类似, tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上。 tanh函数的公式如下:
tanh ( x ) = 1 − exp ( − 2 x ) 1 + exp ( − 2 x ) . \operatorname{tanh}(x) = \frac{1 - \exp(-2x)}{1 + \exp(-2x)}. tanh(x)=1+exp(−2x)1−exp(−2x).
函数图像:
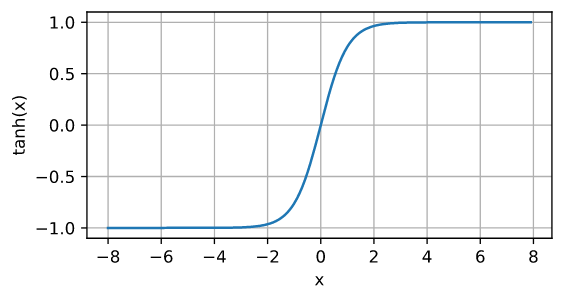
导数图像:
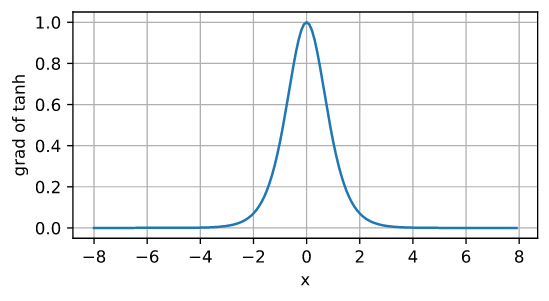
tanh函数的性质与sigmoid函数类似,不多赘述。
3.3 ReLU函数
即 修正线性单元 (Rectified linear unit, ReLU ),ReLU函数将输入为负值的参数的活性值设为0,以此来保留正元素并丢弃所有负元素。实现公式如下:
ReLU ( x ) = max ( x , 0 ) . \operatorname{ReLU}(x) = \max(x, 0). ReLU(x)=max(x,0).
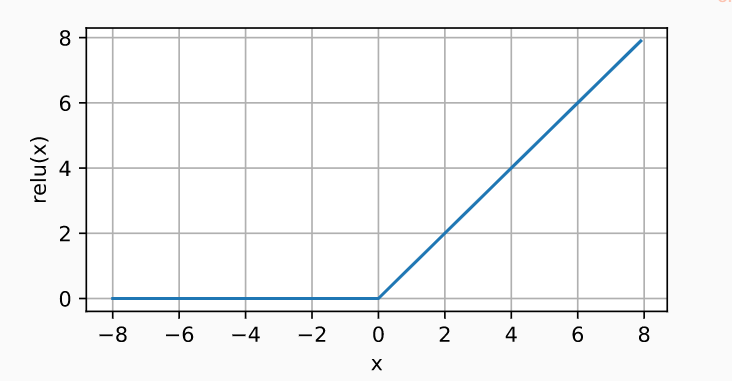
导数图:
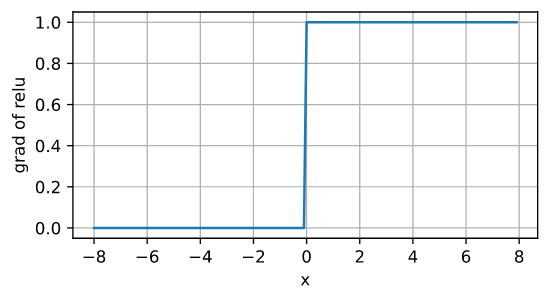
使用ReLU的原因是,它求导表现得特别好,要么让参数消失,要么让参数通过,这使得优化表现得更好。同时,ReLU函数没有用到指数运算,计算量小,效率高。并且由于一部分神经元的输出为0,造成了网络的稀疏性,且减少了参数的相互依存关系,缓解了过拟合问题的发生。
4. 多隐藏层
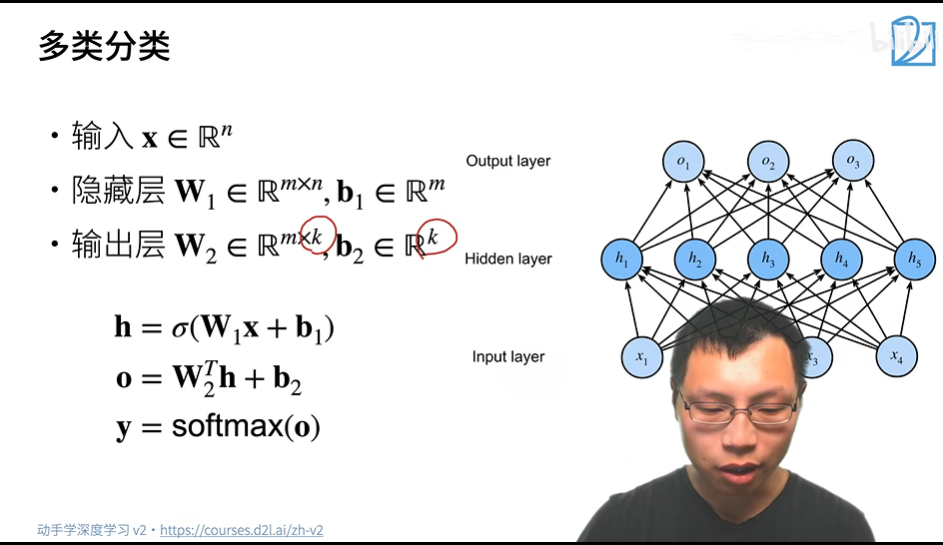
在上文,我们使用单隐藏层进行了单类分类。现在,我们使用多隐藏层进行多类分类。
我们可以使用 Softmax 来处理多类分类。
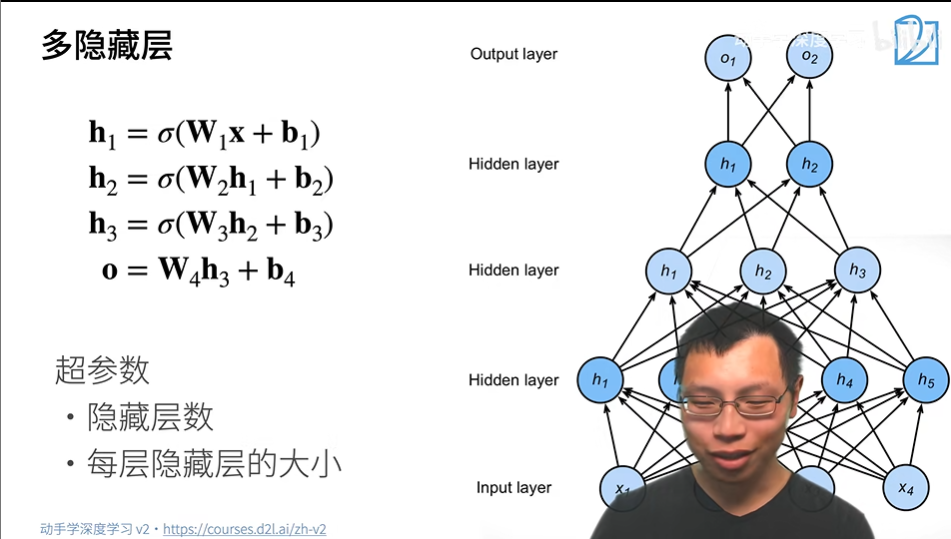
在多隐藏层中,每一个隐藏层的输出h都作为下一个隐藏层的输入。
5. 总结
- 多层感知机在输出层和输入层之间增加一个或多个全连接隐藏层,并通过激活函数转换隐藏层的输出。
- 常用的激活函数包括ReLU函数、sigmoid函数和tanh函数。
- 超参数为隐藏层数,和各个隐藏层大小。
- 使用 Softmax 来处理多类分类。
参考文献
https://zhuanlan.zhihu.com/p/428448728
https://zh-v2.d2l.ai/chapter_multilayer-perceptrons/mlp.html
https://zhuanlan.zhihu.com/p/347917739
https://blog.csdn.net/qq_43557907/article/details/126943951
《动手学深度学习》
https://blog.csdn.net/fg13821267836/article/details/93405572