前言
之所以写“树”据结构这一系列的文章,就是因为有一天突然看到了一句话:心里要有B树……是的,做人心里要有B数,做程序员心里一定要有B树。
之前无论是在学校里学B树,还是自己看B树,总是感觉理解的不够好,事实证明也的确理解的不够到位,否则也不至于达到“看概念懵逼,过一段时间基本等于没看过”的效果。
这次经过潜心研究,发现想理解b树,一定要理解其存在的意义:它要解决什么问题,它是怎么解决这些问题的。
起源
首先记住一句话:想要理解B树,必须时刻牢记我们需要处理的数据量是很大的,大到主存里放不下,所以必须存储在磁盘上!
(而其他的自平衡树,像AVL树和红黑树,他们假定的前提是所有的数据都在主存里。)
Unlike self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as discs. It is commonly used in databases and filesystems.
问题
根据维基百科的介绍,可以认为b树是这么被引入的:
设想,我们需要搜索一个很大的表(大到内存放不下,只能放在磁盘上),我们自然是要将其变成有序的,这样就可以使用二分查找每次将需要检索的范围折半,用不了几次,就能找到目标值了。
比如,这个量级是1000000(一百万并不足够大,这里只是举个例子),那么我们需要
次比较。
时间消耗
和从磁盘上读数据的时间比起来,在内存中进行二分查找所需要的比较时间几乎是可以忽略不计的。
从磁盘上读一条记录需要寻道时间(将磁盘的磁头转到记录所在的磁道)和旋转时间(找到磁道之后,磁头旋转到该磁道存储该记录的位置,也需要时间)。寻道时间一般是0-20ms,或者更多。而旋转时间,对于一个7200转/分钟(RPM)的磁盘来说,旋转时间平均是8.33ms。对于Seagate某款硬盘来说,这两个时间和为0.8ms+8.5ms=9.3ms,约10ms。
因此,从一百万条记录(都在磁盘中)中寻找某条记录需要20次比较,也就是20次读盘时间,约0.2s。
当然,实际上并不需要这么多时间,因为磁盘读取都是按块(block)读取的。比如磁盘块大小为16kB,假设一条记录有16B,那么一个磁盘块可以存储100条记录。当从磁盘读取数据的时候,一次花约10ms读取一整块,也就是100条数据。这也就意味着二分查找在最后100条范围内是不需要再读磁盘的, ,也就是说最后六七次的比较是不需要读盘的。这么说的话,总共并不需要读盘20次,大概13、14次就够了。
索引加速
使用索引将对检索具有重大的意义。
继续上面的假设,一个磁盘块里有100条记录,我们取出每一块的第一条作为该块的索引,那么索引大小将会是原来数据量的1%,也就是10000条。 最多是14,又因为最后6、7次不需要再读盘,所以大概8次读盘就能找到该记录的索引,然后再根据索引记录的位置从磁盘上读出该记录即可,总共8+1=9次读盘。
同样,我们可以再搞一次,对这10000条索引创建索引,即“索引的索引”,则这个一级索引只有100条,正好可以存在一个磁盘块内。
现在,我们只需要读盘3次就能找到我们想要的记录了!假设我们要找的记录在952765条:
1. 读取一级索引,在100条(0、10000、20000、……、990000)中找到目标记录在二级索引的位置,也就是950000对应的那块二级索引,即第95块二级索引(第一块叫第0块);
2. 读取第95块二级索引相应块,在100条(950000、950100、……、959900)二级索引中,952700开头的那一块,即第27块所对应的磁盘块,包含我们的目标记录;
3. 读出该块,第65条(952700+65=952762),就是目标记录。
所以,通过两级索引,我们将读磁盘的次数从14次降到了3次,时间也从140ms降到了30ms。
(题外话:实际操作中,这些一级索引和二级索引都可以放入cache,那么前两次读盘时间基本也可以被忽略了,最终我们只需要一次读盘就取出了目标数据。)
B树 vs. 多级索引
那么问题来了,上面的这些多级索引跟B树有什么关系呢?
这些索引将搜索的复杂度从二分查找的 降到了 ,这里,b代表块因子(每块磁盘所能存储的记录数:b=100; 次读盘)。
这下大致理解B树为什么长的那么奇特了:
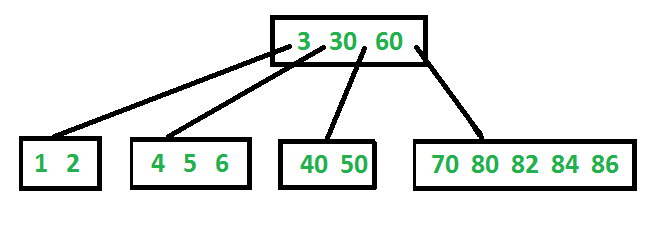
可认为root节点就是一级索引,其存储的是二级索引的分界,以此类推,最底层的叶子节点存储最终的数据(当然,B树的非叶结点存储的也是数据,B+树才是只在叶结点存数据)。当我们需要一个数据的时候,从root出发一层层找下去,其实就相当于先从一级索引找到二级索引,再这么一层层最终找到了数据的位置。
The main idea of using B-Trees is to reduce the number of disk accesses. Most of the tree operations (search, insert, delete, max, min, ..etc ) require O(h) disk accesses where h is height of the tree. B-tree is a fat tree. Height of B-Trees is kept low by putting maximum possible keys in a B-Tree node. Generally, a B-Tree node size is kept equal to the disk block size. Since h is low for B-Tree, total disk accesses for most of the operations are reduced significantly compared to balanced Binary Search Trees like AVL Tree, Red Black Tree, ..etc.
定义
所以说,B树是一种多级索引结构,是以树的形式对数据进行多级索引,从而使得从磁盘查找数据变得十分高效。
度为t的B树有以下特性:
1. 所有叶结点在同一水平;
2. 除了root的每个节点至少有t-1个key,root可以最少只有一个key;
3. 所有节点最多有2t-1个key;
4. 一个结点的孩子是这个节点的key数量+1;
5. 所有的key顺次递增,孩子节点的值在父节点的两个key之间;
6. B树的增删都是从root开始的,而其他的二叉搜索树都是从树的最下面开始的;
至于为什么节点中的key至少是t-1(最大值2t-1的一半),根据维基百科的解释:这意味着可以连接两个半满节点来创建一个合法节点,并且一个完整节点可以分裂成两个合法节点(如果父节点还有空间可以让分裂的节点将一个元素向上推入父节点)。
详细可参考下文中的“节点分裂与合并”。
节点分裂与合并
对于AVL树来讲,增删节点过后,使二叉树再次达到平衡的方式是左旋转与右旋转。对于B树来讲,则是节点分裂与节点合并。
分裂
当节点数据量超出最大值时,B树节点的分裂方式定义如下:
- 节点选出中间值,中间值单独作为一部分,由此节点被分为左中右三部分;
- 中间部分上升一层,并入上层节点,左、右两个部分成为了两个孩子节点;
- 如果上层节点本身以达到最大数量x,此时由于中节点的到来,数量变成了x+1,则上层节点重复分裂过程,直至最上层的根节点。
假设一个节点存储的最少数据个数为min,最多数据个数为max:
由此节点分裂的定义,我们可以得到:
(解释:当节点数量达到上限+1,需要分裂为三部分,其中左右两部分必须满足节点数量下限)
即: 。
合并

当节点数据量小于最大值时,B树节点的合并方式定义如下:
- 如果它的左兄弟节点有至少min+1个节点,右旋转(如上图,红色为小于min的节点,其左子结点至少min+1个,于是向它借8,放入父节点,而他们在父节点中的分界点13被放入了红色节点,从而红色节点得到min个数据);
- 如果它的右兄弟节点至少有min+1个节点,左旋转(和第一种情况对称);
- 如果它的兄弟都恰好是min个节点,则给谁借一个树,都会导致对方不满足min限制,因此只有二者合并为一个节点,同时他们在父节点中的分界点也加入该节点(分界点的作用就是分界,现在两个孩子已经合并了,无界可分)。
简单总结,就是当一个节点删除数据,导致个数不满足min时,要么给左右兄弟借(如果他们有足够的数据),要么和他们合并(都穷,借不起,只好凑一起过日子)。
由此节点合并的定义,我们又可以得到:
(解释:当街点数量小于下限,变为min-1,和兄弟节点合并,再加上分界点,三者组成的新节点要不超过个数上限max)
即: 。
也就是说,一个结点的最小数量小于等于最大数量的一半。但是为了不让空间太过于浪费,B树规定一个结点存储值的最小数量是其最大数量的一半。这样一个结点最多浪费一半的存储空间,不至于更多。这也是上述定义中节点存储值的最少个树是最大个数的一半的依据。
举个例子——
如图是用1、2、……、7,构造一颗节点中数据个数不超过2的B树的过程:
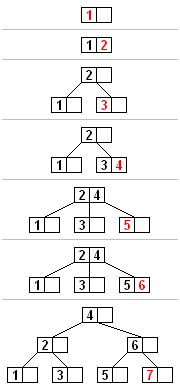
可以看到,当节点中值为1、2,在3到来时,超出了最大个数(两个)的限制,所以分裂为三部分,中间部分为分界点2,2上升一层,留下左右两部分作为其子节点。(B树是自下向上生长的)
B树的“生长方式”和其他的二叉树不太一样。二叉搜索树和AVL树都是从根节点起,不断“向下”增长(增加新节点的时候增加到叶结点上),而B树则是从根节点起,向上生长,根节点不断向上,最开始的节点成为了底层的叶结点。
算法
数据结构
private static class Node<T extends Comparable<T>> {
private T[] keys = null;
private int keysSize = 0;
private Node<T>[] children = null;
private int childrenSize = 0;
private Comparator<Node<T>> comparator = new Comparator<Node<T>>() {
@Override
public int compare(Node<T> arg0, Node<T> arg1) {
return arg0.getKey(0).compareTo(arg1.getKey(0));
}
};
protected Node<T> parent = null;
private Node(Node<T> parent, int maxKeySize, int maxChildrenSize) {
this.parent = parent;
this.keys = (T[]) new Comparable[maxKeySize + 1];
this.keysSize = 0;
this.children = new Node[maxChildrenSize + 1];
this.childrenSize = 0;
}
private T getKey(int index) {
return keys[index];
}
private int indexOf(T value) {
for (int i = 0; i < keysSize; i++) {
if (keys[i].equals(value)) return i;
}
return -1;
}
private void addKey(T value) {
keys[keysSize++] = value;
Arrays.sort(keys, 0, keysSize);
}
private T removeKey(T value) {
T removed = null;
boolean found = false;
if (keysSize == 0) return null;
for (int i = 0; i < keysSize; i++) {
if (keys[i].equals(value)) {
found = true;
removed = keys[i];
} else if (found) {
// shift the rest of the keys down
keys[i - 1] = keys[i];
}
}
if (found) {
keysSize--;
keys[keysSize] = null;
}
return removed;
}
private T removeKey(int index) {
if (index >= keysSize)
return null;
T value = keys[index];
for (int i = index + 1; i < keysSize; i++) {
// shift the rest of the keys down
keys[i - 1] = keys[i];
}
keysSize--;
keys[keysSize] = null;
return value;
}
private int numberOfKeys() {
return keysSize;
}
private Node<T> getChild(int index) {
if (index >= childrenSize)
return null;
return children[index];
}
private int indexOf(Node<T> child) {
for (int i = 0; i < childrenSize; i++) {
if (children[i].equals(child))
return i;
}
return -1;
}
private boolean addChild(Node<T> child) {
child.parent = this;
children[childrenSize++] = child;
Arrays.sort(children, 0, childrenSize, comparator);
return true;
}
private boolean removeChild(Node<T> child) {
boolean found = false;
if (childrenSize == 0)
return found;
for (int i = 0; i < childrenSize; i++) {
if (children[i].equals(child)) {
// delete the children
children[i] = null;
found = true;
} else if (found) {
// shift the rest of the keys down
children[i - 1] = children[i];
}
}
if (found) {
childrenSize--;
children[childrenSize] = null;
}
return found;
}
private Node<T> removeChild(int index) {
if (index >= childrenSize)
return null;
Node<T> value = children[index];
children[index] = null;
for (int i = index + 1; i < childrenSize; i++) {
// shift the rest of the keys down
children[i - 1] = children[i];
}
childrenSize--;
children[childrenSize] = null;
return value;
}
private int numberOfChildren() {
return childrenSize;
}
/**
* {@inheritDoc}
*/
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("keys=[");
for (int i = 0; i < numberOfKeys(); i++) {
T value = getKey(i);
builder.append(value);
if (i < numberOfKeys() - 1)
builder.append(", ");
}
builder.append("]\n");
if (parent != null) {
builder.append("parent=[");
for (int i = 0; i < parent.numberOfKeys(); i++) {
T value = parent.getKey(i);
builder.append(value);
if (i < parent.numberOfKeys() - 1)
builder.append(", ");
}
builder.append("]\n");
}
if (children != null) {
builder.append("keySize=").append(numberOfKeys()).append(" children=").append(numberOfChildren()).append("\n");
}
return builder.toString();
}
}相较于其他AVL树的节点和二叉搜索树的节点,B树的节点要复杂得多。毕竟,从图上就可以看出来,B树是平衡的多分树,也是一颗“胖树”。多分,意味着一个结点有很多子叉,节点内本身也包含多个数据。所以,B树的节点中要有以下内容:
- T[] keys:数据数组,存储本节点中的多个值;
- Node<T>[] children:指针数组,存储子节点的多个指针;
- int keySize:指示当前存储数据的数组的实际长度,即本节点存了多少个数据;
- int childrenSize:指示指针数组的实际长度,即本节点包含多少个子节点;
- Node<T> parent:当前节点的父节点;
除此之外,节点内的数据和指向子节点的指针本身要有序,因此节点中要封装好一些方便对本节点增删数据的方法,比如增删查子节点的addChild、removeChild、getChild,增删查节点数据的addKey、deleteKey、getKey等等。
查找
查找算法和二叉搜索树区别不大,只不过原来是一个结点就一个数据,现在一个结点有多个数据,需要对当前节点的所有数据进行遍历。
/**
* Get the node with value.
*
* @param value
* to find in the tree.
* @return Node<T> with value.
*/
private Node<T> getNode(T value) {
Node<T> node = root;
while (node != null) {
T lesser = node.getKey(0);
if (value.compareTo(lesser) < 0) {
if (node.numberOfChildren() > 0) {
node = node.getChild(0);
} else {
// less than the least of a leaf, no this value
node = null;
}
continue;
}
int numberOfKeys = node.numberOfKeys();
int last = numberOfKeys - 1;
T greater = node.getKey(last);
if (value.compareTo(greater) > 0) {
if (node.numberOfChildren() > numberOfKeys) {
node = node.getChild(numberOfKeys);
} else {
// greater than the greatest of a leaf, no this value
node = null;
}
continue;
}
for (int i = 0; i < numberOfKeys; i++) {
T currentValue = node.getKey(i);
if (currentValue.compareTo(value) == 0) {
return node;
}
int next = i + 1;
if (next <= last) {
T nextValue = node.getKey(next);
if (currentValue.compareTo(value) < 0 && nextValue.compareTo(value) > 0) {
if (next < node.numberOfChildren()) {
node = node.getChild(next);
break;
}
return null;
}
}
}
}
return null;
}增
首先,找到要添加数据的位置:
- 如果节点已有数据个数不满足max,直接放入其中即可;
- 否则,放入其中,进行分裂操作(见“分裂”章节);
/**
* {@inheritDoc}
*/
@Override
public boolean add(T value) {
if (root == null) {
root = new Node<T>(null, maxKeySize, maxChildrenSize);
root.addKey(value);
} else {
Node<T> node = root;
while (node != null) {
if (node.numberOfChildren() == 0) {
node.addKey(value);
if (node.numberOfKeys() <= maxKeySize) {
// A-OK
break;
}
// Need to split up
split(node);
break;
}
// Navigate
// Lesser or equal
T lesser = node.getKey(0);
if (value.compareTo(lesser) <= 0) {
node = node.getChild(0);
continue;
}
// Greater
int numberOfKeys = node.numberOfKeys();
int last = numberOfKeys - 1;
T greater = node.getKey(last);
if (value.compareTo(greater) > 0) {
node = node.getChild(numberOfKeys);
continue;
}
// Search internal nodes
for (int i = 1; i < node.numberOfKeys(); i++) {
T prev = node.getKey(i - 1);
T next = node.getKey(i);
if (value.compareTo(prev) > 0 && value.compareTo(next) <= 0) {
node = node.getChild(i);
break;
}
}
}
}
size++;
return true;
}分裂:具体的分裂如前所述,节点分裂为三部分,如果分裂导致父节点也超过了max,则继续分裂下去,直至root:
/**
* The node's key size is greater than maxKeySize, split down the middle.
*
* @param nodeToSplit
* to split.
*/
private void split(Node<T> nodeToSplit) {
Node<T> node = nodeToSplit;
int numberOfKeys = node.numberOfKeys();
// need to be split into 2 nodes: left node and right node
int medianIndex = numberOfKeys / 2;
T medianValue = node.getKey(medianIndex);
// left values are put into left node
Node<T> left = new Node<T>(null, maxKeySize, maxChildrenSize);
for (int i = 0; i < medianIndex; i++) {
left.addKey(node.getKey(i));
}
// left children are put into left node
if (node.numberOfChildren() > 0) {
for (int j = 0; j <= medianIndex; j++) {
Node<T> c = node.getChild(j);
left.addChild(c);
}
}
// right values are put into right node
Node<T> right = new Node<T>(null, maxKeySize, maxChildrenSize);
for (int i = medianIndex + 1; i < numberOfKeys; i++) {
right.addKey(node.getKey(i));
}
// right children are put into right node
if (node.numberOfChildren() > 0) {
for (int j = medianIndex + 1; j < node.numberOfChildren(); j++) {
Node<T> c = node.getChild(j);
right.addChild(c);
}
}
if (node.parent == null) {
// new root, height of tree is increased
Node<T> newRoot = new Node<T>(null, maxKeySize, maxChildrenSize);
newRoot.addKey(medianValue);
node.parent = newRoot;
root = newRoot;
node = root;
node.addChild(left);
node.addChild(right);
} else {
// Move the median value up to the parent
// add median value; delete old child; add two new children
Node<T> parent = node.parent;
parent.addKey(medianValue);
parent.removeChild(node);
parent.addChild(left);
parent.addChild(right);
if (parent.numberOfKeys() > maxKeySize) {
split(parent);
}
}
}删
首先,找到要删除的数据:
- 如果是在叶结点,直接删掉,然后做合并操作(参考上述“合并”章节);
- 否则,删掉,并从右子树找个最小值,或者左子树找个最大值,作为代替值,取代它的位置(和二叉搜索树中的删除操作一样!)。从未转化为了第一种情况,然后检查替代值原来所在的节点(叶子节点),如果小于min,进行合并操作(参考上述“合并”章节)。
/**
* Remove the value from the Node and check invariants
*
* @param value
* T to remove from the tree
* @param node
* Node to remove value from
* @return True if value was removed from the tree.
*/
private T remove(T value, Node<T> node) {
if (node == null) return null;
T removed = null;
int index = node.indexOf(value);
removed = node.removeKey(value);
if (node.numberOfChildren() == 0) {
// leaf node
if (node.parent != null && node.numberOfKeys() < minKeySize) {
this.combined(node);
} else if (node.parent == null && node.numberOfKeys() == 0) {
// Removing root node with no keys or children
root = null;
}
} else {
// internal node
Node<T> lesser = node.getChild(index);
Node<T> greatest = this.getGreatestNode(lesser);
T replaceValue = this.removeGreatestValue(greatest);
node.addKey(replaceValue);
// now, a value in leaf node is deleted, the same as the former condition
if (greatest.parent != null && greatest.numberOfKeys() < minKeySize) {
this.combined(greatest);
}
if (greatest.numberOfChildren() > maxChildrenSize) {
this.split(greatest);
}
}
size--;
return removed;
}
/**
* Get the greatest valued child from node.
*
* @param nodeToGet
* child with the greatest value.
* @return Node<T> child with greatest value.
*/
private Node<T> getGreatestNode(Node<T> nodeToGet) {
Node<T> node = nodeToGet;
while (node.numberOfChildren() > 0) {
node = node.getChild(node.numberOfChildren() - 1);
}
return node;
}
/**
* Remove greatest valued key from node.
*
* @param node
* to remove greatest value from.
* @return value removed;
*/
private T removeGreatestValue(Node<T> node) {
T value = null;
if (node.numberOfKeys() > 0) {
value = node.removeKey(node.numberOfKeys() - 1);
}
return value;
}合并:具体的合并过程如前所述,就是能跟兄弟借就借,不能借就合成一个节点:
/**
* Combined children keys with parent when size is less than minKeySize.
*
* @param node
* with children to combined.
* @return True if combined successfully.
*/
private boolean combined(Node<T> node) {
Node<T> parent = node.parent;
int index = parent.indexOf(node);
int indexOfLeftNeighbor = index - 1;
int indexOfRightNeighbor = index + 1;
Node<T> rightNeighbor = null;
int rightNeighborSize = -minChildrenSize;
if (indexOfRightNeighbor < parent.numberOfChildren()) {
rightNeighbor = parent.getChild(indexOfRightNeighbor);
rightNeighborSize = rightNeighbor.numberOfKeys();
}
// I. Try to borrow neighbor
if (rightNeighbor != null && rightNeighborSize > minKeySize) {
// Try to borrow from right neighbor
T removeValue = rightNeighbor.getKey(0);
int prev = getIndexOfPreviousValue(parent, removeValue);
T parentValue = parent.removeKey(prev);
T neighborValue = rightNeighbor.removeKey(0);
node.addKey(parentValue);
parent.addKey(neighborValue);
if (rightNeighbor.numberOfChildren() > 0) {
node.addChild(rightNeighbor.removeChild(0));
}
} else {
Node<T> leftNeighbor = null;
int leftNeighborSize = -minChildrenSize;
if (indexOfLeftNeighbor >= 0) {
leftNeighbor = parent.getChild(indexOfLeftNeighbor);
leftNeighborSize = leftNeighbor.numberOfKeys();
}
if (leftNeighbor != null && leftNeighborSize > minKeySize) {
// II. Try to borrow from left neighbor
T removeValue = leftNeighbor.getKey(leftNeighbor.numberOfKeys() - 1);
int prev = getIndexOfNextValue(parent, removeValue);
T parentValue = parent.removeKey(prev);
T neighborValue = leftNeighbor.removeKey(leftNeighbor.numberOfKeys() - 1);
node.addKey(parentValue);
parent.addKey(neighborValue);
if (leftNeighbor.numberOfChildren() > 0) {
node.addChild(leftNeighbor.removeChild(leftNeighbor.numberOfChildren() - 1));
}
} else if (rightNeighbor != null && parent.numberOfKeys() > 0) {
// III-1. Can't borrow from neighbors, try to combined with right neighbor
T removeValue = rightNeighbor.getKey(0);
int prev = getIndexOfPreviousValue(parent, removeValue);
T parentValue = parent.removeKey(prev);
parent.removeChild(rightNeighbor);
node.addKey(parentValue);
for (int i = 0; i < rightNeighbor.keysSize; i++) {
T v = rightNeighbor.getKey(i);
node.addKey(v);
}
for (int i = 0; i < rightNeighbor.childrenSize; i++) {
Node<T> c = rightNeighbor.getChild(i);
node.addChild(c);
}
if (parent.parent != null && parent.numberOfKeys() < minKeySize) {
// removing key made parent too small, combined up tree
this.combined(parent);
} else if (parent.numberOfKeys() == 0) {
// parent no longer has keys, make this node the new root
// which decreases the height of the tree
node.parent = null;
root = node;
}
} else if (leftNeighbor != null && parent.numberOfKeys() > 0) {
// III-2. Can't borrow from neighbors, try to combined with left neighbor
T removeValue = leftNeighbor.getKey(leftNeighbor.numberOfKeys() - 1);
int prev = getIndexOfNextValue(parent, removeValue);
T parentValue = parent.removeKey(prev);
parent.removeChild(leftNeighbor);
node.addKey(parentValue);
for (int i = 0; i < leftNeighbor.keysSize; i++) {
T v = leftNeighbor.getKey(i);
node.addKey(v);
}
for (int i = 0; i < leftNeighbor.childrenSize; i++) {
Node<T> c = leftNeighbor.getChild(i);
node.addChild(c);
}
if (parent.parent != null && parent.numberOfKeys() < minKeySize) {
// removing key made parent too small, combined up tree
this.combined(parent);
} else if (parent.numberOfKeys() == 0) {
// parent no longer has keys, make this node the new root
// which decreases the height of the tree
node.parent = null;
root = node;
}
}
}
return true;
}总结
从二叉搜索树,到AVL树,再到B树,都是有联系的,比如删除操作,AVL和B树的删除操作就是先使用二叉搜索树的删除操作,然后各自做自己的rebalance(左右旋转 vs. 分裂合并)。
个人感觉,B树最重要的还是知道其起源,这样足以对B树有深刻而形象的认识,然后知道B树的分裂、合并操作,从而对B树有个的定义有更深刻的理解。
参考
对以下内容作者深表感谢:
1. https://en.wikipedia.org/wiki/B-tree
2. https://www.geeksforgeeks.org/b-tree-set-1-introduction-2/
3. https://github.com/phishman3579/java-algorithms-implementation/blob/master/src/com/jwetherell/algorithms/data_structures/BTree.java