上几篇文章我们主要从源码角度分析了ArrayList,大家对ArrayList的学习,一定是掌握了ArrayList的用户,接下来再次总结一下ArrayList
1.ArrayList的底层数据结构是数组,当数组满后需要对其进行扩容,我们知道数组的长度是不可以变化的,扩容时用到了数组的拷贝,把新扩容的数组赋值给底层的数组。 2.ArrayList对读多写少的业务效率非常高的,因为我们直接可以用到数组的下标获取元素,但是对于中间的插入和删除,ArrayList底层进行了数组的复制,所以中间的插入和删除效率相对较低 3.ArrayList不支持多线程的并发,多线程下可能会出现数据的脏读,数组下标越界等异常
接下来我们从源码角度去分析List集合下的另一个非常重要的子类:LinkedList,看看它到底和ArrayList有什么不同
LinkedList也是List的实现类,我们知道ArrayList底层的数据结构结构是数组,ArrayList对元素的操作,也是对底层数组的操作,那么LinkedList的底层数据结构又是什么呢?还是数组吗?
我们学习数据结构时,我们主要学习了一下几种数据结构:数组、链表、树、图。从名称上我们可以猜想到LinkedList的数据结构就是链表。在分析源码之前,我们可以先总结一下LinkedList的知识点;
第一个知识点:LinkedList的底层数据结构是链表,而且还是一个双向链表
第二个知识点:允许包含所有的元素,包括null.
第三个知识点:LinkedList在多线程下是不安全的
本篇文章我们还是从LinkedList的属性、构造函数、基本的方法来说明
从LinkedList源码中,我们可以了解到,LinkedList数据结构封装到了Node对象中,我们先看一下这个封装的Node数据接口
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
数据结构中存放了3个重要的字段
1)item:存放的LinkedList的元素的值,就是当前Node的值 2)next:当前Node的下一个元素Node,当前节点的后继 3)prev:当前Node的前一个元素Node,当前节点的前驱
从Node数据结构中我们可以再次证明LinkedList是一个双向链表。
一、LinkedList的重要属性
1)第一个重要的属性:size,元素的集合大小
transient int size = 0;
2)第二个重要的属性:first:指向链表的第一个Node元素,即链表的头结点
transient Node<E> first;
3)第三个重要的元素:last:指向链表的最后一个Node元素,即链表的最后一个节点
LinkedList就只有这3个重要的元素,有了这3个元素就能够获取链表的所有元素了,因为每一个节点中都保存着它前一个节点Node prev和后一个节点Node next.
二、LinkedList的构造函数
1)无参构造
public LinkedList() {
}
2)有参数构造
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
三:LinkedList的重要方法
1)第一个重要的方法:add(E e)
public boolean add(E e) {
linkLast(e);
return true;
}
我们可以看到Linked的add方法就是在向链表末尾添加元素,因为LinkedList有一个重要的属性last,所以直接调用linkLast方法插入到链表末尾,我们把目标移动到linkLast方法中
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
(1)Node<E>l=last:这段代码的意思就是,把链表的最后一个节点last先用一个局部变量保存,以便我们接下来用,因为last的引用要移动,所以需要定义一个局部变量保存当前last的指向
(2)Node<E>newNode=new Node<>(l,e,null);这句代码的意思就是把当前add的元素封装成Node对象,从上面我们分析Node对象可知,newNode的prev前驱指向当前last节点,就是l,元素的值e,因为我们是向链表的最后一个节点添加的,所以newNode的next是null
(3)last=newNode:这句代码就是把最后一个节点的引用指向刚添加的元素newNode。
(4)判断链表是否为空链表,如果是则把新添加的元素newNode也赋值给链表的首节点first,这样first=last=newNode.
(5)如果链表不为空,则把添加newNode前的节点的后继next指向newNode,我们知道LinkedList是双向链表,newNode.prev=l这个在new Node时就创建了,而l.next=null,所以要将l.next=newNode
(6)size++就是讲集合的大小加1,modCount++,这个modCount我们在ArrayList也讲过就是集合修改的次数。
从上面的分析我们知道add方法的效率是非常的高的,时间复杂度o(1).
下面我们举例说明add的步骤:
如果我们有集合list,当前是空集合。
第一次:add(1),此时first=last=newNode

第二次:add(3)

第三次:add(6)

通过我们对add(E e)源码的分析以及这个示例的图示,我们很容易掌握LinkedList的add
2)第二个重要的方法:add(int index,E e)插入
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
这个方法就是在LinkedList已有的元素中插入一个元素,可以在链表的开头、中间、结尾插入。
(1)checkPositionIndex方法主要判断给出的index是否有效,只有0<=index<=size,说明用户给出的index才有效,否则就会抛出异常。
(2)如果index==size说明插入的是结尾,和add(E e)方法相同,都会调用linkLast插入到链表的结尾,如果不是插入链表的结尾,就调用linkBefore,linkBefore的第一个参数就是将要插入的元素,第二个参数就要将新元素插入到谁的前面,在我们讲解linkBefore之前,我们首先看一下怎样通过index,获取当前Node的元素
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}从源码中我们可以看到,jdk通过index查询Node时,利用了类似于折半查找的算法,size>>1就是向右移动一位,它的值就是变成了size的一半。如果index<1/2size,则从first查找,如果index>=1/2size则从last开始查找。
我们转移到linkBefore中
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}其中e:就是要插入的新元素,而succ:就是e要插入succ前面
(1)Node<E>pred = succ.prev,就是获取succ的前驱,现在这个前驱指向succ,插入e后,这个前驱要执行e,
(2)Node<E>newNode=new Node<>(pred,e,succ):这段代码就是把e封装成Node,而newNode.prev=pred,newNode.val=e,newNode.next=succ
(3)新插入的元素newNode的前驱和后继都有了指向,但是这是succ的前驱指向newNode,所以succ.prev=newNode
(4)我们知道pred现在需要把后继指向newNode,但是我们不知道pred是否为空,就是我们不知道是插入的首节点,还是插入的中间节点,需要分别判断一下,如果pred==null,说明newNode插入的是首节点,这样直接将first=newNode即可,如果newNode插入的不是首节点,则将pred的后继指向newNode,即pred.next=newNode
举例说明,第一个示例List集合中有元素,1,3,6,现在我们向list中add(6,10),这会出现结果呢?

从结果中看出,index超出了,所以调用add(index,e)时,要时刻记着0<=index<=size
第一种:我们插入到头结点:add(0,10)
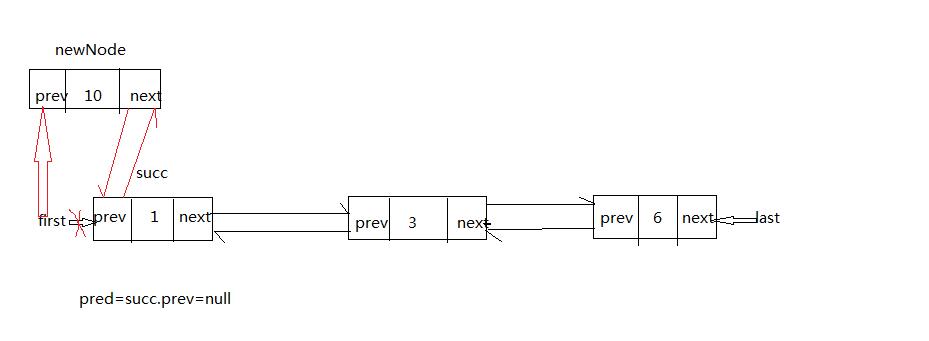
可以看到红色箭头就是插入后的改变,如果插入的是头结点,需要如下步骤
1)创建newNode结点时把newNode.next=succ.
2)把succ.prev=newNode
3)因为是插入的头结点pred==null,所以,first=newNode
第二种:我们插入到中间:add(2,10)

1)通过node(2)查找出succ
2)创建newNode,则newNode.prev=pred(红线1),newNode.next=succ(红线2)
3)将succe.prev=newNode(红线3)
4)因为pred!=null pred.next=newNode(红线4)
第三种:我们插入到末尾:add(3,10)

这就是Linked的插入,大家着重理解一下,对于链表非常熟悉的话,理解起来不是很难。
3)第三个重要方法:remove(int index)
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
第一句代码检查一下inde是否符合0<=index<size,不能等于size
删除的真正逻辑在unlink()方法中,我们到unlink方法中
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
这段代码非常的好理解
1)首先获取将要删除元素x的值,前驱prev,后继next,
2)如果删除的是头结点,则直接把x的后继next赋值给first,如果不是,则需要把x的后继next指向x前驱prev的后继,即prev.next=next.然后将x.prev=null
3)如果删除的是末尾结点,则直接将last指向x的前驱prev,如果不是,则需要把x的前驱prev指向next的前驱
4)把x.item=null,返回item
举例说明:
第一种:删除头结点:remove(0)
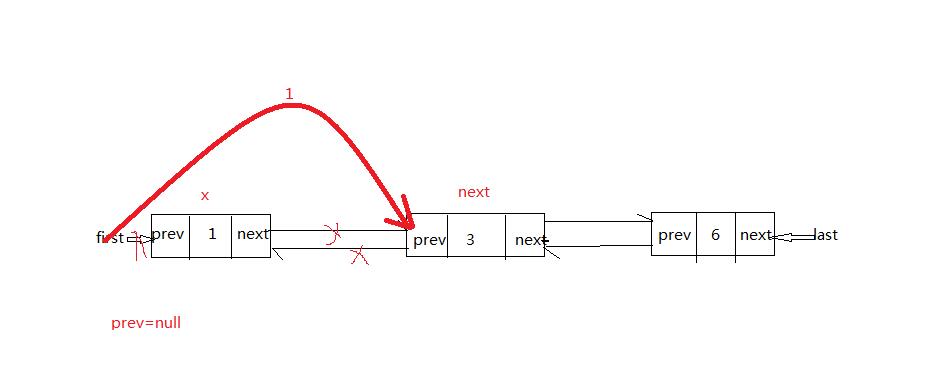
1)要删除的节点就是1对应的节点x,此时next=3对应的节点,prev=null
2)prev=null 所以执行first=next,即红线1
3)next!=null 所以执行next.prev=prev=null;
第二种:删除中间节点,remove(1)

1)x是3对应的节点,prev是1对应的节点,next是6对应的节点
2)prev!=null 则执行prev.next=next,x.prev=null
3)next!=null,则执行next.prev=prev,x.next=null
第三种:删除尾节点remove(2)

1)x是6对应的节点,prev是3对应的节点,next=null
2)prev!=null 则执行prev.next=null,x.prev=null
3)next==null 则执行last=prev
4)第四个重要方法:get(index)
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
这个方法没有什么好分析的了,node(index)方法我们已经分析过了
这篇文章主要介绍了LinkedList的底层数据结构,重要的属性、构造方法、增删改查等重要的方法,如果对你有所帮助,请持续关注