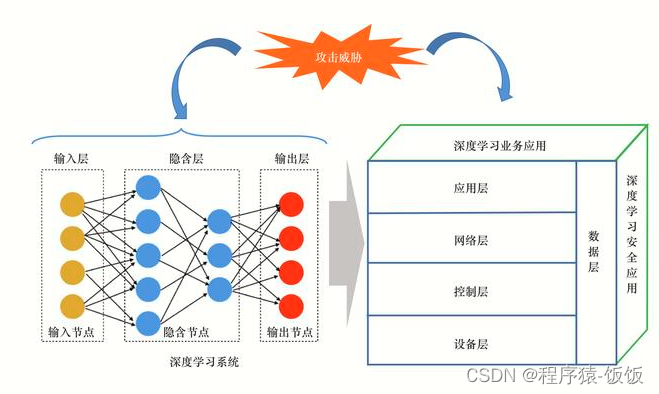
在深度学习中,模型优化和调参是关键步骤,它们对于提高模型的性能和泛化能力至关重要。优化模型的过程涉及到数据预处理、模型选择、超参数调整、训练过程管理等多个方面。正确的优化方法可以加快训练速度,提高模型的准确度和鲁棒性。
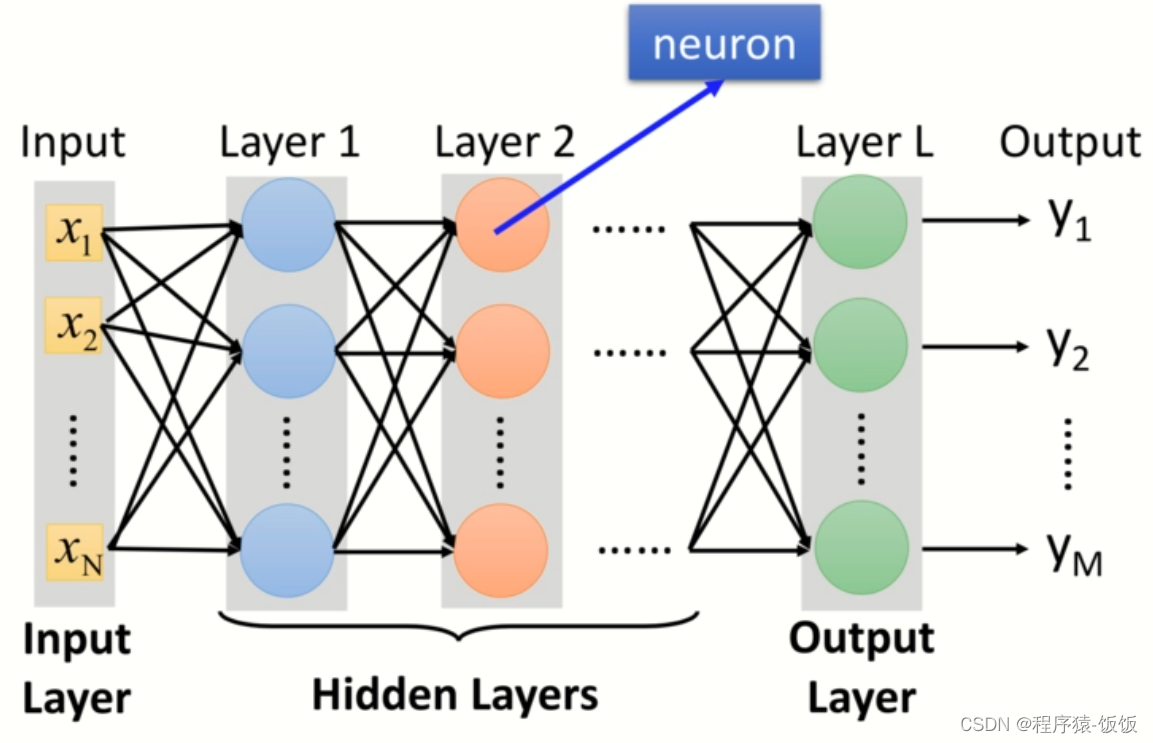
本文将介绍深度学习模型优化和调参的一般步骤和常用方法。无论你是初学者还是有一定经验的深度学习从业者,都可以通过本文了解如何优化和调整模型,以获得更好的结果。
可以通过以下几个步骤来进行:
-
数据预处理:首先,对数据进行预处理,包括数据清洗、归一化、标准化等操作,以减少数据中的噪声和冗余信息,提高模型的训练效果。
-
构建模型:选择适合任务的深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)或Transformer等。根据问题的复杂程度和数据集的特征选择合适的模型结构和层数。
-
选择损失函数:根据任务的特点选择合适的损失函数,如均方误差(MSE)、交叉熵损失(Cross-Entropy)等。损失函数反映了模型预测结果与真实标签之间的差异。
-
选择优化算法:选择适合任务的优化算法,如随机梯度下降(SGD)、Adam、RMSprop等。优化算法用于调整模型中的参数,以最小化损失函数。
-
设置超参数:超参数是模型的配置参数,例如学习率、批量大小、正则化参数等。通过交叉验证或网格搜索等方法,尝试不同的超参数组合,选择效果最好的组合。
-
训练模型:使用训练数据集对模型进行训练,通过反向传播算法更新模型的参数。根据训练集和验证集的表现来监控模型的训练进度,避免过拟合或欠拟合的情况。
-
模型评估:使用测试数据集对训练好的模型进行评估,计算模型的准确率、精确率、召回率等指标。根据评估结果调整模型和超参数的选择。
-
调参:根据模型的评估结果,对超参数进行调整。可以使用网格搜索、随机搜索、贝叶斯优化等方法来搜索最优的超参数组合。
-
模型正则化:在模型训练过程中,可以采用正则化方法,如L1正则化、L2正则化或Dropout等,以减少模型的复杂性,提高泛化能力。
-
模型集成:通过集成多个模型的预测结果,可以提高模型的性能和稳定性。常见的集成方法包括投票法、平均法、堆叠法等。
以上是深度学习中常用的模型优化和调参方法。在实际应用中,还可以根据具体问题的特点进行针对性的调整和改进。同时,注意进行合理的实验设计和结果分析,以确保模型的性能和效果的稳定提升。
感谢大家对文章的喜欢,欢迎关注威 |
❤公众号【AI技术星球】回复(123) |
白嫖深度学习配套籽料+60G入门进阶AI资源包+技术问题答疑+完整版视频 |
内含:深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)+NLP等
|
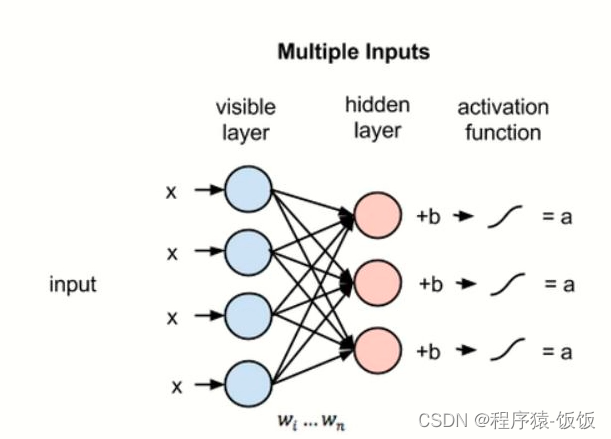
为了深入了解模型优化和调参的方法和技巧,建议参考深度学习领域的经典教材、论文以及开源框架的官方文档,以获取更详细的指导和实践经验。