一、什么是缓存
缓存就是数据交换的缓冲区,是存贮数据的临时地方,一般读写性能较高。
我们可以在很多地方做缓存,比如浏览器缓存、应用层缓存、数据库缓存等等
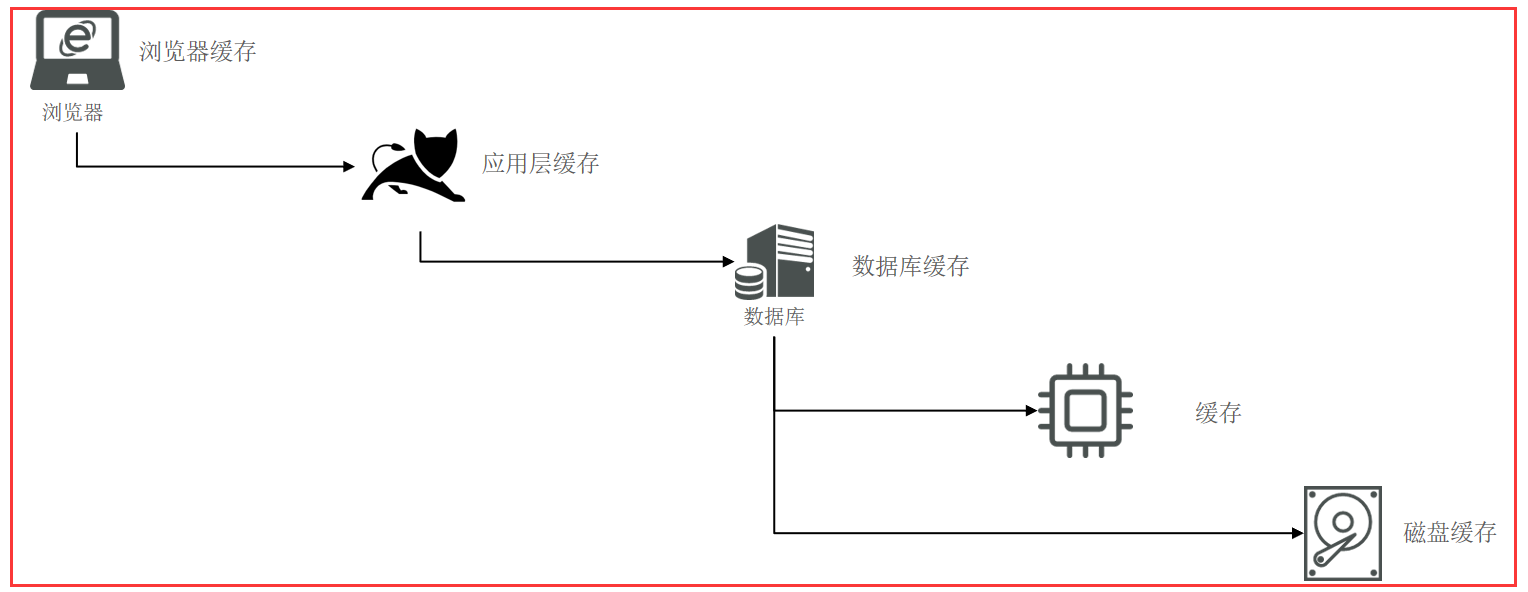
二、缓存的作用
- 我们可以使用缓存,降低后端负载;
- 使用缓存,可以提高读写效率,降低响应时间。
三、添加商户缓存
思路分析:
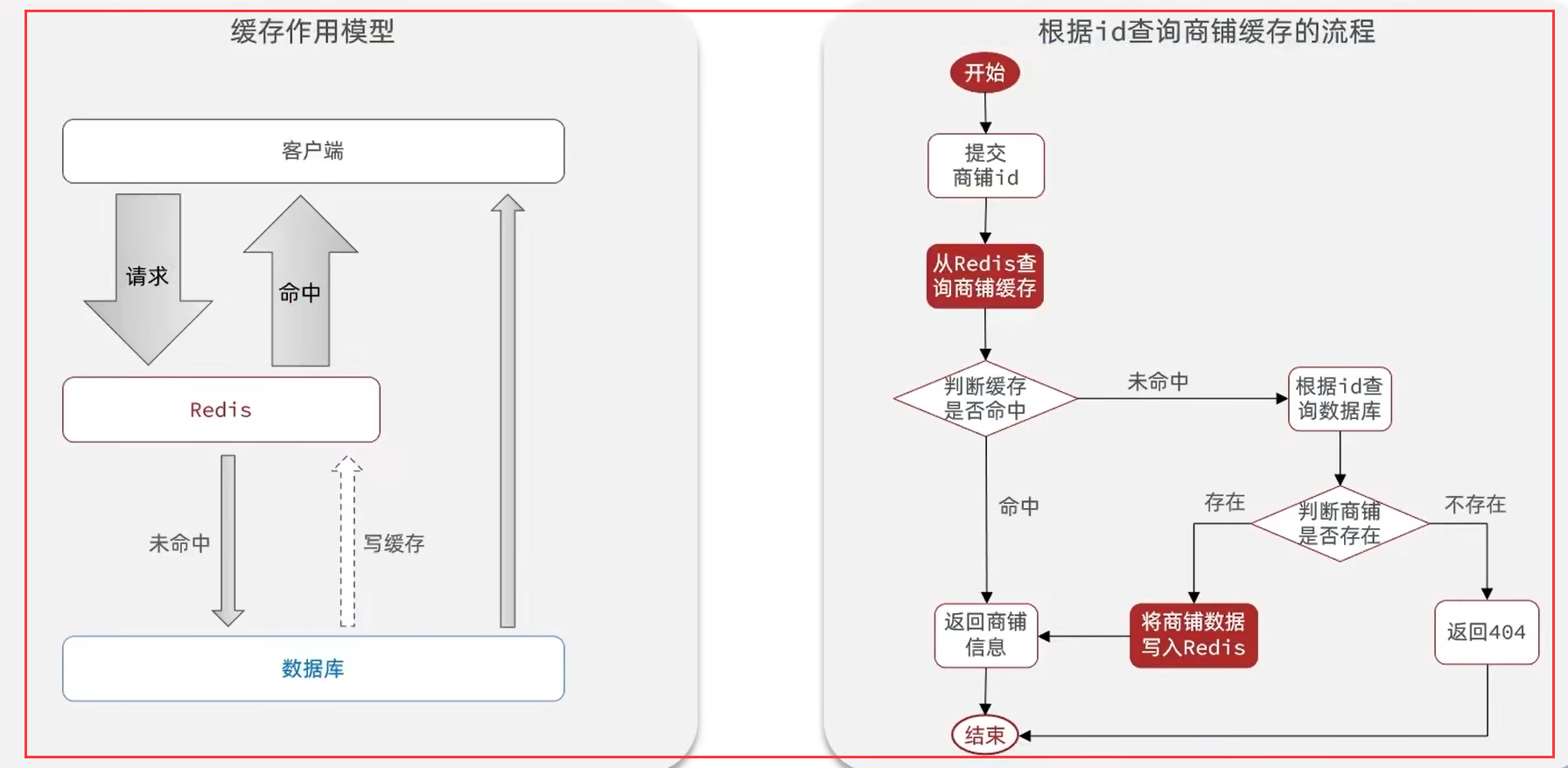
- 首先从Redis中查询数据是否存在:如果存在,则返回数据;如果不存在,则访问数据库;
- 接着从数据库中查询数据是否存在:如果存在,则从数据库中返回数据并写入redis缓存中;如果不存在,则提示用户不存在。
代码实现:
//controller层
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
return shopService.queryShopById(id);
}
//service层
@Autowired
private ShopMapper shopMapper;
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public Result queryShopById(Long id) {
String key = CACHE_SHOP_KEY + id;
String shopCache = redisTemplate.opsForValue().get(key);
//如果在缓存中查询到商户,则返回数据给前端
if (StrUtil.isNotBlank(shopCache)) {
Shop shop = JSONUtil.toBean(shopCache, Shop.class);
System.out.println("shopCache" + shopCache);
return Result.ok(shop);
}
//不存在则根据id在数据库中查找
Shop shop = shopMapper.selectById(id);
if (shop == null) {
return Result.fail("店铺不存在");
}
//店铺存在,写入缓存
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
return Result.ok(shop);
}
整体思路如下:
四、分析缓存更新策略
- 刚才的代码在更新数据方面存在着一些问题,所以来一起讨论讨论redis的缓存更新策略。
Redis有三种缓存更新策略:
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不需要自己维护,利用redis的内存淘汰机制,当内存不足时自动淘汰部分数据。下次查询时更新缓存 | 给缓存数据添加ttl(过期)时间,到期后自动删除缓存。下次查询时更新缓存 | 编写业务逻辑,在修改数据库的同时,更新缓存 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
业务场景的使用:
| 业务场景 | 低一致性需求 | 高一致性需求 |
|---|---|---|
| 使用内存淘汰机制 | 使用主动更新,并以超时剔除作为兜底方案 |
对于商户查询的缓存,这里使用的是主动更新策略,而对于主动更新策略的选择,又有三种方案,这里采用的是方案一:
| 方案一 | 由缓存的调用者,在更新数据库的同时更新缓存 |
|---|---|
| 方案二 | 缓存与数据库整合为一个服务,由服务来维护一致性。调用者调用该服务,无需关心缓存一致性问题 |
| 方案三 | 调用者只操作缓存,由其它线程异步的将缓存数据持久化到数据库,保证最终一致 |
方案拿捏了,在操作缓存和数据库时,我们还需要考虑三个问题:
1、删除缓存还是更新缓存?
如果采用更新缓存,那么每次更新数据库时都会更新缓存,无效写操作较多,所以我们不采用;选择删除缓存,在更新数据库时让缓存失效,等到查询时再更新缓存。
2、如何保证缓存与数据库的操作同时成功或失败?
单体系统:将缓存与数据库操作放在一个事物
分布式系统:利用TCC等分布式事物方案
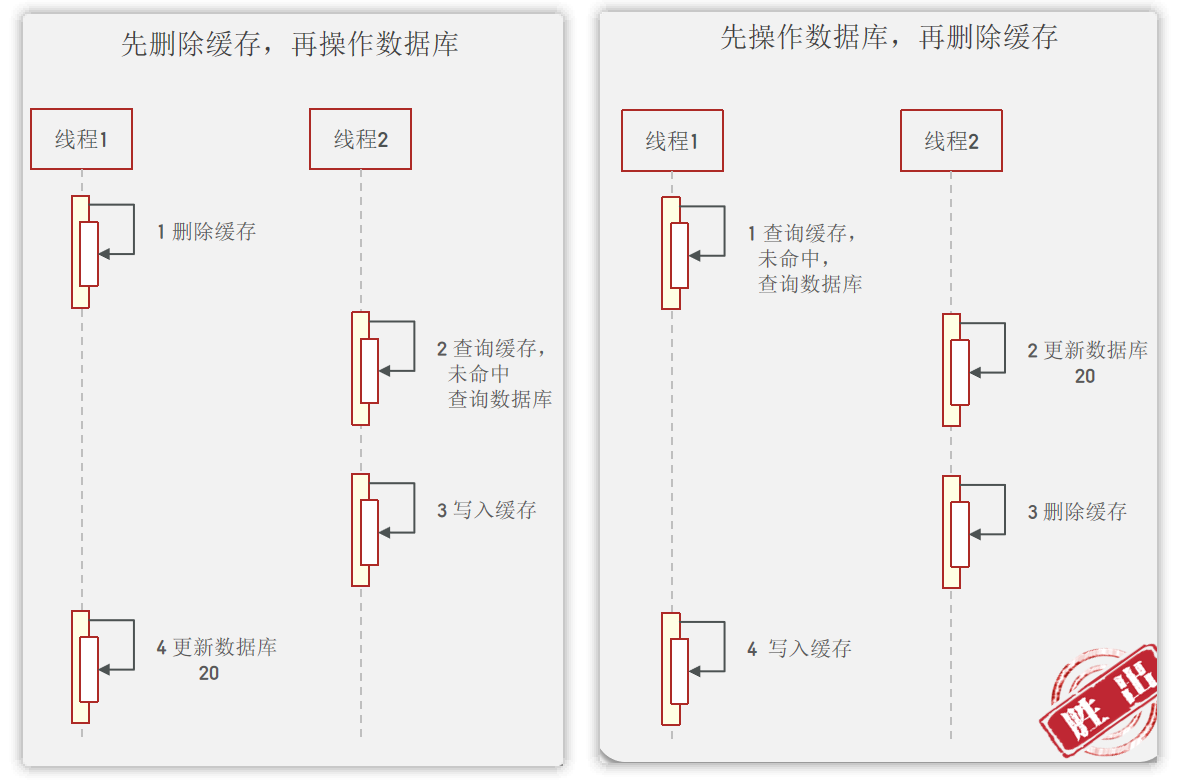
3、先操作缓存还是先操作数据库?
- 如果先删除缓存再操作数据库,如图所示,在线程1删除缓存开始更新数据库时,线程2进来了,此时数据库还未更新,那么线程2写入的缓存就不是数据库更新后的数据
- 如果先操作数据库再删除缓存,如图所示,在线程1查询数据库并写入缓存时,线程2进来了,此时线程2更新数据库并删除缓存,那么线程1写入的缓存也就不是数据库更新后的数据
- 但是由于后者在写入缓存的时间低于数据库更新的时间,所以第二种选择更好,发生数据不同步的概率更低!
小总结:
- 对于读操作:缓存命中则直接返回;缓存未命中则查询数据库,并写入缓存,设定超时时间。
- 对于写操作:先写数据库,然后再删除缓存;要确保数据库与缓存操作的原子性。
代码实现:
- 根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间。
- 根据id修改店铺时,先修改数据库,再删除缓存。
service层代码:
//查询商户
@Override
public Result queryShopById(Long id) {
String key = CACHE_SHOP_KEY + id;
String shopCache = redisTemplate.opsForValue().get(key);
//如果在缓存中查询到商户,则返回数据给前端
if (StrUtil.isNotBlank(shopCache)) {
Shop shop = JSONUtil.toBean(shopCache, Shop.class);
return Result.ok(shop);
}
//不存在则根据id在数据库中查找
Shop shop = shopMapper.selectById(id);
if (shop == null) {
return Result.fail("店铺不存在");
}
//店铺存在,写入缓存,过期时间设置为30分钟
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);
}
//更新商户
@Override
@Transactional
public Result updateShop(Shop shop) {
Long shopId = shop.getId();
if (shopId == null) {
return Result.fail("店铺id不能为空");
}
//先更新数据库
shopMapper.updateById(shop);
//再删除缓存
redisTemplate.delete(CACHE_SHOP_KEY + shopId);
return Result.ok();
}
controller层代码:
/**
* 根据id查询商铺信息
* @param id 商铺id
* @return 商铺详情数据
*/
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
return shopService.queryShopById(id);
}
/**
* 更新商铺信息
* @param shop 商铺数据
* @return 无
*/
@PutMapping
public Result updateShop(@RequestBody Shop shop) {
return shopService.updateShop(shop);
}