在简单的学习了svm支持向量机后,做到了对手写数字或字母的识别,以及后续有感而发做了对巡线小车路口的判断
由于对手写数字或者字母识别这种图片的识别过程比较简单,下面就直接附上的是检测一段路线的代码,对手写数字这种直接就可以在while True里面改就行,不想循环就可以把while True删了也行
先提前对图片进行二值化化处理:
import cv2 as cv
import numpy as np
import cv2
import os
file_root = 'F:/in_picture/' # 当前文件夹下的所有图片
file_list = os.listdir(file_root)
save_out = "F:/out_picture/train/" # 保存图片的文件夹名称
for img_name in file_list:
img_path = file_root + img_name
img = cv.imread(img_path, -1)
imgHsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
lower = np.array([0, 0, 110]) #更改掩膜达到想要的效果
upper = np.array([255, 255, 255])
mask = cv2.inRange(imgHsv, lower, upper)
out_name = img_name.split('.')[0]
save_path = save_out + out_name + '.jpg'
cv2.imwrite(save_path, mask)这里附上找图片或者视频阈值的代码:
import cv2
import numpy as np
def nothing(a):
pass
cv2.namedWindow("HSV") #窗口名字
cv2.resizeWindow("HSV",640,480)
cv2.createTrackbar("HUE Min", "HSV", 0, 255, nothing)
cv2.createTrackbar("HUE Max", "HSV", 255, 255, nothing)
cv2.createTrackbar("SAT Min", "HSV", 0, 255, nothing)
cv2.createTrackbar("SAT Max", "HSV", 255, 255, nothing)
cv2.createTrackbar("VALUE Min", "HSV", 0, 255, nothing)
cv2.createTrackbar("VALUE Max", "HSV", 110, 255, nothing)
cap = cv2.VideoCapture('C:/Users/K2095/Desktop/777.mp4') # 0是打开摄像头
while True:
_,img = cap.read()
img = cv2.resize(img, (640, 480))
# img = cv2.imread('F:/out_picture/train/000.jpg') #若是要对图片进行处理,注释掉上面两行代码然后用这行,括号里是图片路径
imgHsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) #将彩色图转换为灰度图
h_min = cv2.getTrackbarPos("HUE Min", "HSV") #得到滑动条的数值,第一个参数是滑动条名字,第二个是所在窗口,返回值是滑动条的数值
h_max = cv2.getTrackbarPos("HUE Max", "HSV")
s_min = cv2.getTrackbarPos("SAT Min", "HSV")
s_max = cv2.getTrackbarPos("SAT Max", "HSV")
v_min = cv2.getTrackbarPos("VALUE Min", "HSV")
v_max = cv2.getTrackbarPos("VALUE Max", "HSV")
lower = np.array([h_min, s_min, v_min]) #创建数组
upper = np.array([h_max, s_max, v_max])
mask = cv2.inRange(imgHsv, lower, upper)
result = cv2.bitwise_and(img, img, mask=mask)#将图像结合(img和mask),就是运行这个程序后出现的第三个摄像头,其实也可以不要要这个合并
mask = cv2.cvtColor(mask, cv2.COLOR_GRAY2BGR) #图像颜色转换(合理是灰度图)
hStack = np.hstack([img, mask,result]) #就是将生成的三个摄像头窗口连在一起
cv2.imshow('Horizontal Stacking', hStack)
if cv2.waitKey(1) & 0xFF == 27:
break
cv2.destroyAllWindows() #这个我真不知道有什么用,可要可不要先是把图片导入,然后把图片和图片对应的标签分别保存在列表里返回(我这里的图片是640*480的)
def tes():
list=[]
list1=[]
file_root = 'F:/out_picture/train/' # 当前文件夹下的所有图片
file_list = os.listdir(file_root)
for img_name in file_list:
img_path = file_root + img_name
img = cv2.imread(img_path,-1)
image_file = np.array(img, dtype=np.uint8)
image_file = image_file.reshape(1, 307200) #压缩图片成1*307200
list.append(np.array(image_file).flatten())
for i in range(11): #前三个是直线,中间四个是十字路口,后面四个是直角
if i<3:
list1.append('II')
if 2<i<7:
list1.append('SS')
if i>6:
list1.append('ZZ')
print(list1)
X_train = list
Y_train = list1
return X_train,Y_train这是我二值化后的图片:

下面对图片进行训练,并把训练好的模型保存在save文件夹里
def train():
t=tes()
X_train= np.array(t[0])
# print(X_train)
y_train=t[1]
print(np.array(X_train).shape)
print(np.array(y_train).shape)
print('开始训练')
time_start = time.time()
model_svc = svm.SVC(C=1.4, kernel='rbf', gamma='scale',probability=True)
model_svc.fit(X_train, y_train)
time_end = time.time()
time_c = time_end - time_start
print('time : {second}s'.format(second=time_c)) #打印训练时间
joblib.dump(model_svc,'save/model_svc.pkl',compress=3) #保存模型下面是得分模型计算(正确数量/样本数量)这里由于我就放了两张进去,所以我得分是1.0,可以多放一些,当然如果你不需要得分这个指标,那可以忽略这段代码,因为判断一个模型的好坏有很多个指标,我自己也只用到了准确率这一个:
def tes_score(model_svc):
list = []
list_all = []
file_root = 'F:/out_picture/test/' # 当前文件夹下的所有图片
file_list = os.listdir(file_root)
for img_name in file_list:
img_path = file_root + img_name
img = cv2.imread(img_path, -1)
image_file = np.array(img, dtype=np.uint8)
image_file = image_file.reshape(1, 307200)
list.append(np.array(image_file).flatten())
x_test = list
y_test = ['SS','ZZ']
print('得分:',model_svc.score(x_test, y_test)) # 根据训练的模型,进行分类得分计算
#return model_svc.score(x_test, y_test)
接下来是预测函数:
def pred(model_svc,image_file):
y_pred = model_svc.predict([image_file[0]]) # 进行预测,能得到一个结果
print('预测结果是:', y_pred[0])完整代码:
import numpy as np
from sklearn import svm
import cv2
import time
import os
from matplotlib import pyplot as plt
import joblib
def tes():
list=[]
list1=[]
file_root = 'F:/out_picture/train/' # 当前文件夹下的所有图片
file_list = os.listdir(file_root)
for img_name in file_list:
img_path = file_root + img_name
img = cv2.imread(img_path,-1)
image_file = np.array(img, dtype=np.uint8)
image_file = image_file.reshape(1, 307200)
list.append(np.array(image_file).flatten())
for i in range(11): #标签
if i<3:
list1.append('II')
if 2<i<7:
list1.append('SS')
if i>6:
list1.append('ZZ')
print(list1)
X_train = list
Y_train = list1
return X_train,Y_train
def tes_score(model_svc):
list = []
list_all = []
file_root = 'F:/out_picture/test/' # 当前文件夹下的所有图片
file_list = os.listdir(file_root)
for img_name in file_list:
img_path = file_root + img_name
img = cv2.imread(img_path, -1)
image_file = np.array(img, dtype=np.uint8)
image_file = image_file.reshape(1, 307200)
list.append(np.array(image_file).flatten())
x_test = list
y_test = ['SS','ZZ']
print('得分:',model_svc.score(x_test, y_test)) # 根据训练的模型,进行分类得分计算
#return model_svc.score(x_test, y_test)
def train():
t=tes()
X_train= np.array(t[0])
print(X_train)
y_train=t[1]
print(np.array(X_train).shape)
print(np.array(y_train).shape)
print('开始训练')
time_start = time.time()
model_svc = svm.SVC(C=1.4, kernel='rbf', gamma='scale',probability=True)
model_svc.fit(X_train, y_train)
time_end = time.time()
time_c = time_end - time_start
print('time : {second}s'.format(second=time_c))
joblib.dump(model_svc,'save/model_svc.pkl',compress=3)
# def pred(model_svc,image_file):
# y_pred = model_svc.predict([image_file[0]]) # 进行预测,能得到一个结果
# print('预测结果是:', y_pred[0])
cap = cv2.VideoCapture('C:/Users/K2095/Desktop/666.mp4')
train()
model = joblib.load('save/model_svc.pkl')
tes_score(model)
while True:
success, image_file = cap.read()
cv2.namedWindow("frame", 0) # 0可调大小,注意:窗口名必须imshow里面的一窗口名一致
cv2.resizeWindow("frame", 640, 480) # 设置长和宽
# image_file = cv2.imread('F:/out_picture/train/000.jpg')
imgHsv = cv2.cvtColor(image_file, cv2.COLOR_BGR2HSV)
lower = np.array([0, 0, 122]) #改变掩膜模拟测试集
upper = np.array([255, 255, 255])
mask = cv2.inRange(imgHsv, lower, upper)
image_file = np.array(mask,dtype=np.uint8)
image_file = image_file.reshape(1,307200) #307200
# pred(model, image_file)
predict=model.predict_proba(image_file)
mypred = model.predict(image_file)
print(predict)
for i in range(1,3): #屏蔽了直线
if predict[0][i]>0.6:
print('结果是',mypred)
#显示视频时用到下面的代码
cv2.imshow("frame", mask)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
#显示图片时用到下面的代码,把77到79行,95到97注释掉,取消第80的注释
# plt.imshow(mask, cmap=plt.cm.gray_r)
# plt.title(str(mypred[0]))
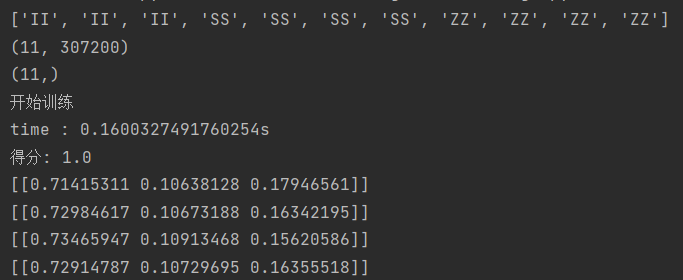
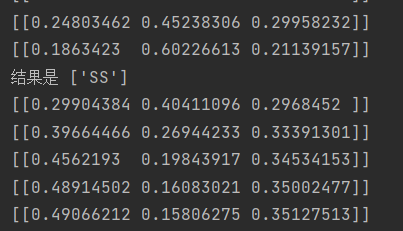
# plt.show()这是打印的结果(二维数组里的三个值分别是直线十字直角的概率):
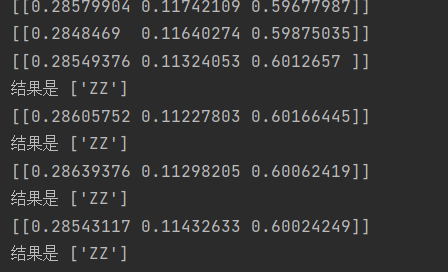
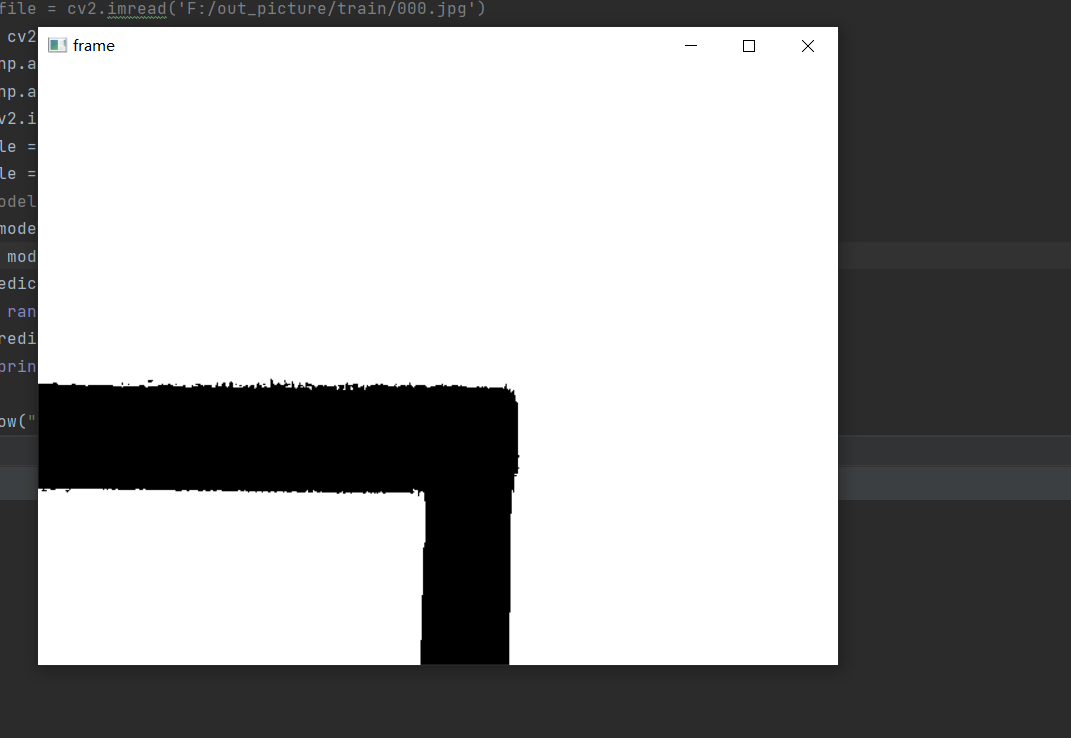
这个是运行的视频效果的截图:
以上是用svm对简单的路口的识别,需要注意的是我每次运行就是对图片重新进行一次训练,所以保存在save文件夹里的模型是每运行一次就会更新一次,想要找到比较好的模型就需要进行多次训练,然后根据你的指标找到最好的一个模型,最简单的就是写个for循环,加上你的判断指标如准确率、精确率等等,还有一点很重要的就是数据集的制作,数据集做的越好,模型就会越好
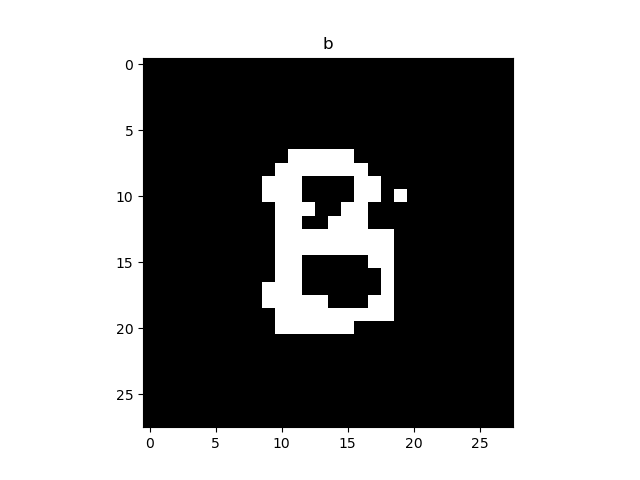
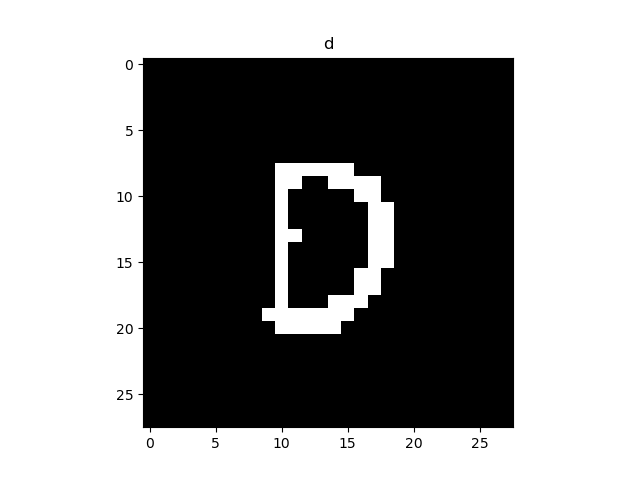
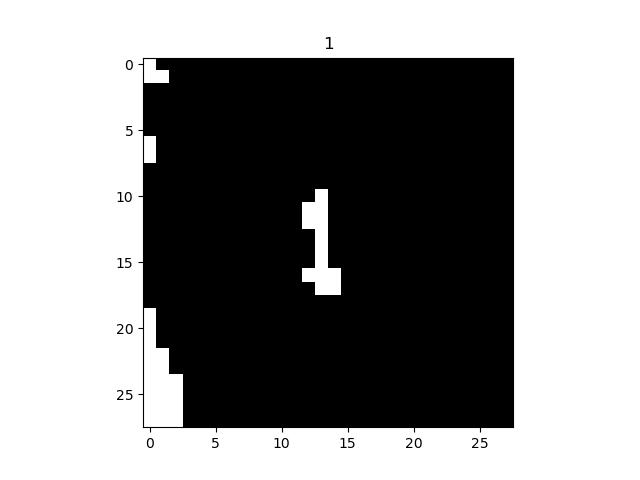
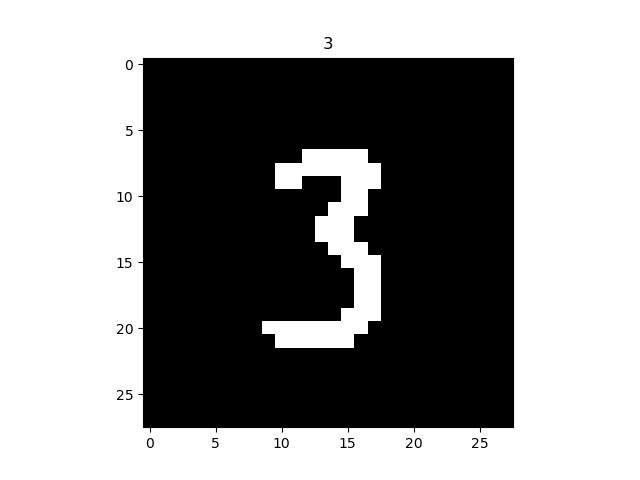
最后在附上手写数字和手写字母的效果: