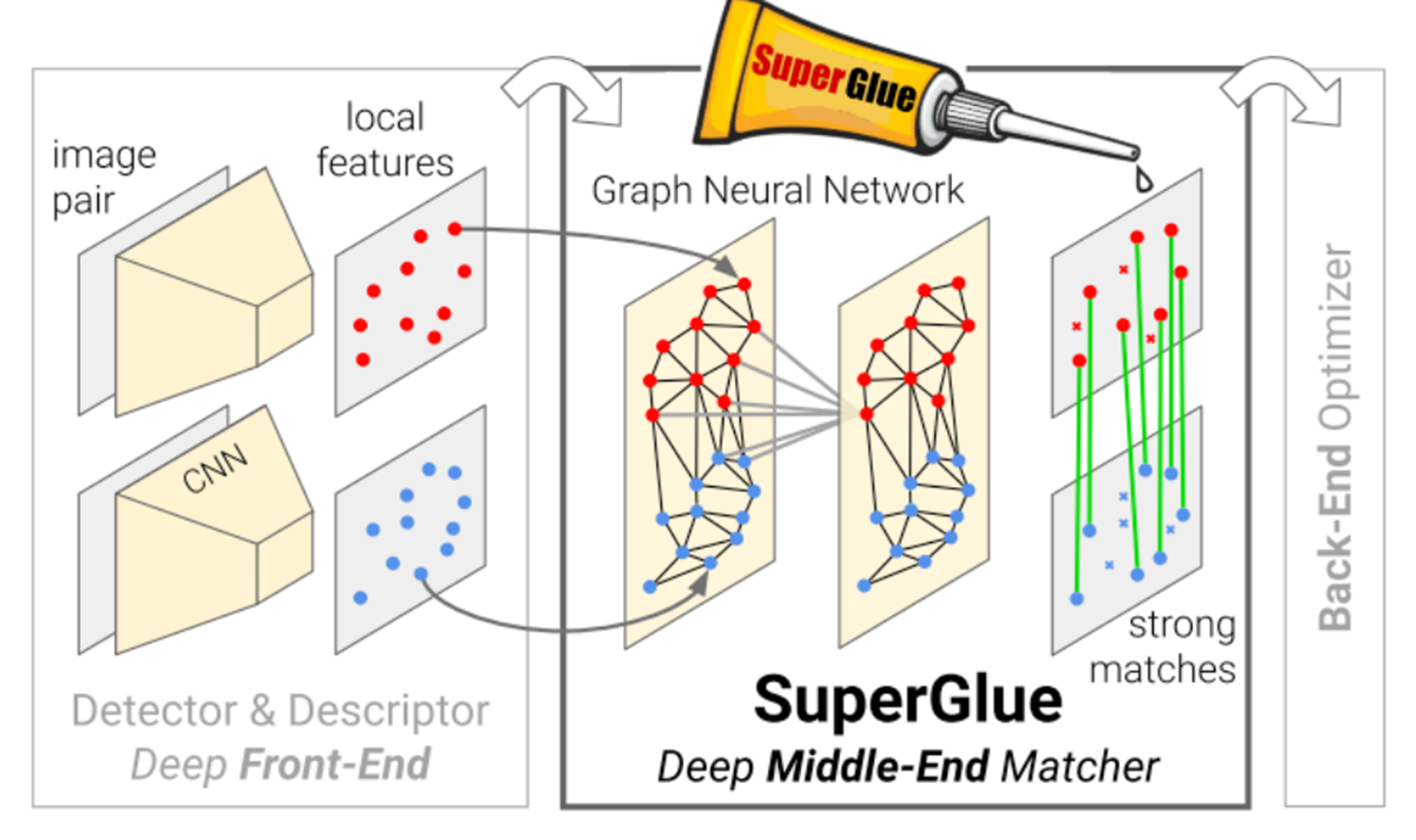
在进行最优传输相关理论的学习过程中,找到SuperGlue这篇论文,该篇论文通过最优传输来完成特征点的匹配过程。
SuperGlue结构
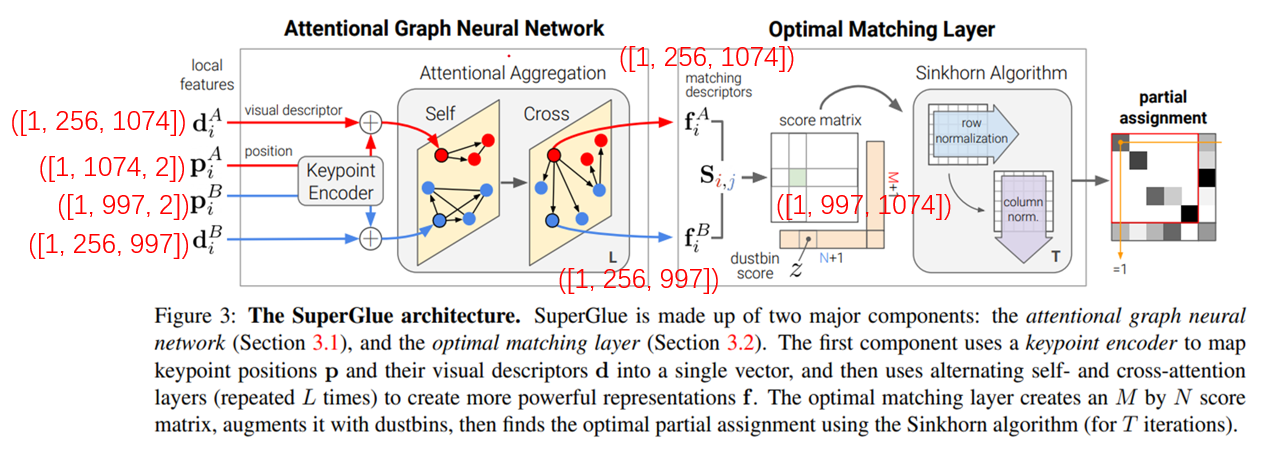
先来看一下其结构:
首先将两张图片送入特征提取网络,通过卷积网络提取出特征,主要有四个值,分别是两张图片的特征信息,diA与diB(1,256,997),256是维度特征,以及位置信息piA与piB(1,997,2) 997指的是图像中的特征点数目,2指的是xy坐标。
随后将特征点位置送入KeyPoint Encoder中进行维度转换,变为(1,256,997)与(1,256,1074),随后送入AGNN(Attentional Graph Neatural Network),该模块是借鉴于Transformer,进行自注意力与交叉注意力计算,最终获取两个图像的特征,分别为(1,256,1074)与(1,256,997),随后使用两个特征信息计算score,具体计算方式为:
mdesc0, mdesc1 = self.final_proj(desc0), self.final_proj(desc1)
# Compute matching descriptor distance.
scores = torch.einsum('bdn,bdm->bnm', mdesc0, mdesc1)
即求得值为Sij,随后借鉴于SuperPoint,引入dustbin,是为了处理没有匹配上的特征点,由此构成了代价矩阵,将构造的代价矩阵送入Sinkhorn算法中进行运算,最终得到传输计划与损失值。
下图为数据变换与模型结构图。