“ 随着ChatGPT的火热,各种生成式模型也如雨后春笋般涌现,包括自然语言和图像生成之间的模型,已经趋近成熟。但是将文本转换为视频的模型还没有得到很好的发展,即使有也只处于非常初级的阶段。”
01
—
Runway Gen2
相信有些小伙伴用过Runway Gen1,用来通过文字生成属于自己风格的图片,类似SD的LORA功能,Gen2这次算是来了一个大的跨越,实现了文字到视频的转换,前几天这个功能才正式开放,有120秒的试用机会,有兴趣的小伙伴可以去Gen-2 | Runway (runwayml.com)申请。
02
—
damo-vilab/text-to-video-ms-1.7b
这个模型是huggingface上开源的一个模型,能够自定义生成25秒以内的视频(如果你的显存小于16GB),这个模型有个缺点就是训练这模型的哥们用的shutter上的素材,水印没去掉,生成的视频有时会带有水印。不过没关系,对于各位大神来说,几行python代码就能搞定,话不多说直接体验
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
import gradio as gr
# load pipeline
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16",cache_dir="damo-vilab",resume_download=True)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
# optimize for GPU memory
pipe.enable_model_cpu_offload()
pipe.enable_vae_slicing()
def genvedios(text):
video_frames = pipe(text, num_inference_steps=200, num_frames=20).frames
video_path = export_to_video(video_frames, output_video_path="outputs/{}.mp4".format(text))
return video_path
demo = gr.Interface(genvedios,"text",gr.Video())
demo.launch()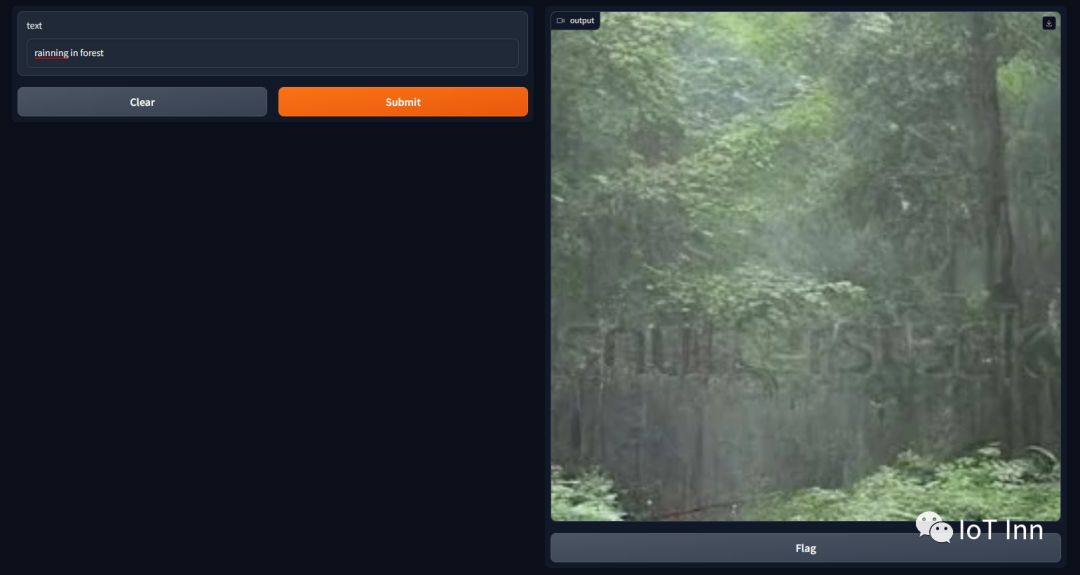
整体来说,步数越大,视频清晰度越高,内容也更符合,帧数越多,视频越长。
喜欢的朋友点个关注