1. 题目
CODER: Knowledge infused cross-lingual medical term embedding for term normalization
Zheng Yuan团队
CODER: contrastive learning on knowledge graphs for cross-lingual medical term reprensentation.
跨语言医学术语表示的知识图对比学习
2. 贡献
- 提出了KG的对比训练模型;
- 对现有医疗嵌入进行评估。zero-shot术语标准化、医学概念相似性度量和概念关系分类任务中实现了最先进的结果( state-of-the-art);
- CODER是第一个跨语言的医学术语表示,支持英语、捷克语、法语、德语、意大利语,日语、葡萄牙语、俄语、西班牙语、荷兰语和汉语。
3. 方法
定义基于嵌入的术语规范化任务以及如何嵌入术语;然后引入KG对比学习进行项归一化。
- 提出了对kg的两术语和关系三元组的对偶对比学习。
- 术语关系项相似度是术语关系(ℎ,r)和术语(t)之间的相似度。
3.1 基于嵌入术语正则化
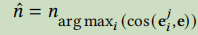
即是把术语向量化,然后计算cos距离,选择最大的那个标准术语作为最后的结果;
3.2 术语表达
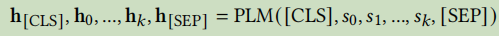
初始化PLM: PubMedBERT [17] ,mBERT [12];
术语表示,方法1:采用[CLS]的向量来表示;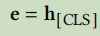
方法2:采用平均pooling来表示:
3.3 同义词的对比学习框架
正样本主要是来自图谱:term-term对;term-relation-term对;
label定义:

术语相似性定义:
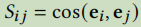
相关技术
a. 医学嵌入
- 词嵌入[9,30,38];
- 概念嵌入[3,6,10,11,52,56];
- 上下文嵌入[2,4,17,20,21,26,42,56]。
Word和概念嵌入在评估相似性方面具有良好的基础性能,但面临OOV问题,不能处理临床文本中普遍存在的拼写错误。
基于PLM的上下文嵌入可以通过使用子单词token来缓解OOV问题,但如果不进行微调,它们在评估相似性方面的性能就会弱于单词和概念嵌入。
SapBERT(基于UMLS训练) [32],
mBERT(跨语言)[12]:将不同语言的文本编码到一个统一的空间中.
词嵌入:word2vec model[36],使用医学语料[9, 30, 38];
概念嵌入:从emr或生物医学论文中识别出的医学概念序列被认为是句子,用word2vec[6,10,11,52]训练并进行嵌入;
Cui2vec [3]:将 CUI-CUI之间的逐点互信息PMI(Pointwise Mutual Information)矩阵分解,得到嵌入; PMI可以衡量两变量之间的相关性。
Zhang et al. [56] :提出概念上下文嵌入和UMLS关系语料库的训练。
医学上下文嵌入(医学语料):BERT [2, 4, 17, 20, 26, 42];
Jin et al. [21]:BioELMo;SapBERT[32]:关于UMLS同义词的自对齐预训练
b. 医学术语标准化
- 分类方法;
生成术语的隐藏表示,并使用softmax层将术语分类为概念。
编码模型(CNN, RNN, or PLM); attention机制使用来获取重要的字或字符;
这个方法只能用类别,不能用到语义信息。 - 排名方法;
排序方法通过训练术语和候选目标术语之间正负样本对,来预测他们相似度而进行排序。例如 DNorm [25]是能过TF-IDF vectors来计算相似性;Li et al. [28] 使用CNN编码,NSEEN [14]使用 siamese LSTM;BNE [45]编码术语,概念,上下文;Pattisapuet al. [41] 通过graph embeddings; BIOSYN [49]使用TF-IDF 与 BioBERT [26];【这些都是英文的】
Niu et al. [39]构建中文医学概念标准库;另外还有基于翻译的方法在进行 [1, 43, 47]。
c. 对比学习
**[16]:**对于NLP,DeCLUTR[16]从同一文档中收集positive的句子对。
CERT [15]: 创建句子对;
SapBERT [32]:使用UMLS的同义词对作为正样本;
损失函数也对比学习一块很关键的内容:
Triplet loss [19] 最小化正负样本对的关系距离;
InfoNCE[40]认为一小量批次的其它样本作为负样本对;
Multi-Similarity loss (MS-loss) [53]:多维相似损失;
参考
【1】githut:https://github.com/GanjinZero/CODER
【2】Zheng Yuan, Zhengyun Zhao, Haixia Sun, Jiao Li, Fei Wang, and Sheng Yu. 2021. CODER: Knowledge infused cross-lingual medical term embedding for term normalization. In Proceedings of ACM Conference (Conference’17).
ACM, New York, NY, USA, 11 pages.https://arxiv.org/pdf/2011.02947.pdf
【3】Fangyu Liu, Ehsan Shareghi, Zaiqiao Meng, Marco Basaldella, and Nigel Collier. 2020. Self-alignment Pre-training for Biomedical Entity Representations. arXiv
preprint arXiv:2010.11784 (2020).