论文:TextBrewer: An Open-Source Knowledge Distillation Toolkit for Natural Language Processing
哈工大,讯飞
1. 简介
TextBrewer是一个基于PyTorch的、为实现NLP中的知识蒸馏任务而设计的工具包, 融合并改进了NLP和CV中的多种知识蒸馏技术,提供便捷快速的知识蒸馏框架, 用于以较低的性能损失压缩神经网络模型的大小,提升模型的推理速度,减少内存占用。
TextBrewer结构:
流程:
- Stage 1 : 蒸馏之前的准备工作:
- 训练教师模型
- 定义与初始化学生模型(随机初始化,或载入预训练权重)
- 构造蒸馏用数据集的dataloader,训练学生模型用的optimizer和learning rate scheduler
- Stage 2 : 使用TextBrewer蒸馏:
- 构造训练配置(
TrainingConfig)和蒸馏配置(DistillationConfig),初始化distiller- 定义adaptor 和 callback ,分别用于适配模型输入输出和训练过程中的回调
- 调用distiller的train方法开始蒸馏
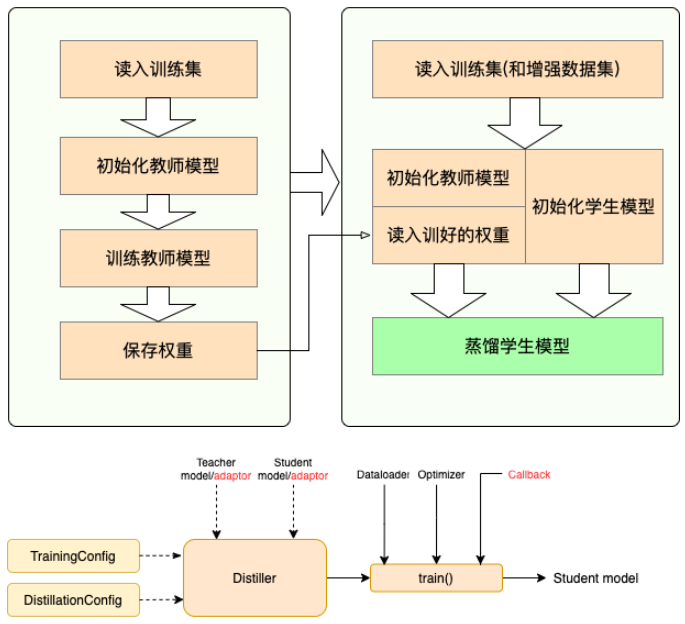
其它的内容,github上介绍得比较清楚【2】。
2.实践
核心概念
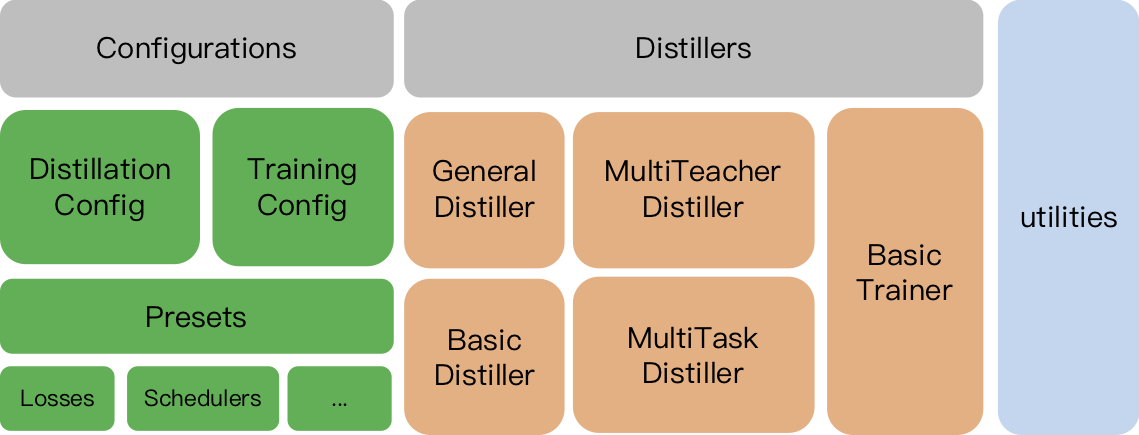
Configurations
TrainingConfig和DistillationConfig:训练和蒸馏相关的配置。Distillers
Distiller负责执行实际的蒸馏过程。目前实现了以下的distillers:
BasicDistiller: 提供单模型单任务蒸馏方式。可用作测试或简单实验。GeneralDistiller(常用): 提供单模型单任务蒸馏方式,并且支持中间层特征匹配,一般情况下推荐使用。MultiTeacherDistiller: 多教师蒸馏。将多个(同任务)教师模型蒸馏到一个学生模型上。暂不支持中间层特征匹配。MultiTaskDistiller:多任务蒸馏。将多个(不同任务)单任务教师模型蒸馏到一个多任务学生模型。BasicTrainer:用于单个模型的有监督训练,而非蒸馏。可用于训练教师模型。用户定义函数
蒸馏实验中,有两个组件需要由用户提供,分别是callback 和 adaptor :
Callback
回调函数。在每个checkpoint,保存模型后会被
distiller调用,并传入当前模型。可以借由回调函数在每个checkpoint评测模型效果。Adaptor
将模型的输入和输出转换为指定的格式,向
distiller解释模型的输入和输出,以便distiller根据不同的策略进行不同的计算。在每个训练步,batch和模型的输出model_outputs会作为参数传递给adaptor,adaptor负责重新组织这些数据,返回一个字典。
2.1 安装
略
参考
【1】TextBrewer: An Open-Source Knowledge Distillation Toolkit for Natural Language Processing,https://aclanthology.org/2020.acl-demos.2.pdf
【2】README_ZH.md,https://github.com/airaria/TextBrewer/blob/master/README_ZH.md
【3】完整文档:https://textbrewer.readthedocs.io/en/latest/