上文说到弱监督语义分割使用图像级标签来定位图像中的对象。
其中,一些先前的研究已经提出了应用类激活映射的技术。无论是CAM、Grad-CAM还是Score-CAM,它们都遵循类似的pipeline来生成CAM。
CAM
什么是CAM?
简而言之,就是一个帮助我们可视化CNN的工具。使用CAM,我们可以清楚的观察到,网络关注图片的哪块区域。
提出
这项技术由周博磊在2016年的 CVPR 提出,作者发现了即使在没有定位标签的情况下训练好的 CNN 中间层也具备目标定位的特性,但是这种特性被卷积之后的向量拉伸和连续的全连接层破坏,但若是将最后的多个全连接层换成了全局平均池化层 GAP 和单个后接 Softmax 的全连接层,即可保留这种特性。同时,经过简单的计算,可以获取促使 CNN 用来确认图像属于某一类别的具有类别区分性的区域,即 CAM。
原理
使用论文中的话来说,类激活图仅仅是在不同空间位置处存在这些视觉图案的加权线性和。 通过简单地将类激活映射上采样到输入图像的大小,我们可以识别与特定类别最相关的图像区域。如果把这段话翻译成数学语言,就是如下的公式。

最终 CAM 的值越大,表示对分类贡献度越高:如下图最后一幅图的热力图红色区域表示 CAM 值最大,也正是澳洲犬脸部区域。
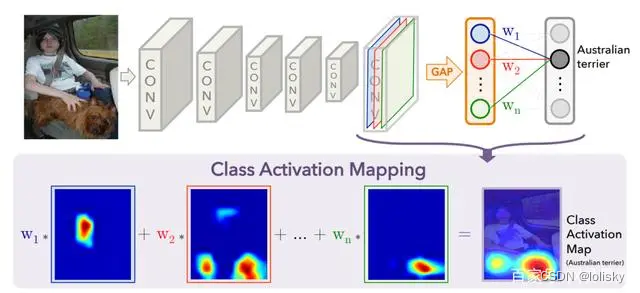
上图网络是一个基于分类训练的CNN网络,最左边是输入,中间是很多卷积层,在最后一层卷积层之后接的是全局平均池化层(GAP),最后接一层softmax,得到输出。
GAP就是把特征图转换成特征向量,每一层特征图用一个值表示,所以如果这个特征图的深度是3(红绿蓝),那么这个特征向量的长度就是3。我们的输出是Australian terrier。我们用Australian terrier这个类对应的权重乘上特征图对应的层,用热力图归一化,即下面一排热力图:W1蓝色层+W2红色层+…+Wn*绿色层=类激活映射(CAM)。
所以说CAM是一个加权线性和。通常来说,最后一层卷积层的大小是不会等于输入大小的,所以我们需要把这个类激活映射上采样(通过暴力上采样实现)到原图大小,再叠加在原图上,就可以观察到网络得到这个输出是关注图片的哪个区域了。这也就是说可以是任意输入图片的大小和卷积层的深度。
评价
在文章中,作者表示 CAM 所在区域可直接作为弱监督目标定位的预测,并进行了相关实验,不仅相比当时最好的弱监督定位算法效果提升明显,而且仅需单次前向推理过程即可得到定位框。
在弱监督语义分割中,CAM 一直是产生种子区域的核心算法。但是 CAM 缺点也很明显:仅关注最具辨别度的区域,无法覆盖到整个目标,后续的算法中大多是在解决这个问题或者对 CAM 进行后处理。