一、损失函数的种类
损失函数是机器学习中求解模型参数最优化问题的目标函数,损失函数主要有以下几种类型。
1、0-1损失函数
2、平方损失函数
3、绝对损失函数
4、对数损失函数
5、交叉信息熵
6、合页损失函数
7、逻辑斯蒂损失函数
8、指数损失函数
合页损失函数、逻辑斯蒂损失函数、指数损失函数是0-1损失函数的上界,他们的关系如下图所示。
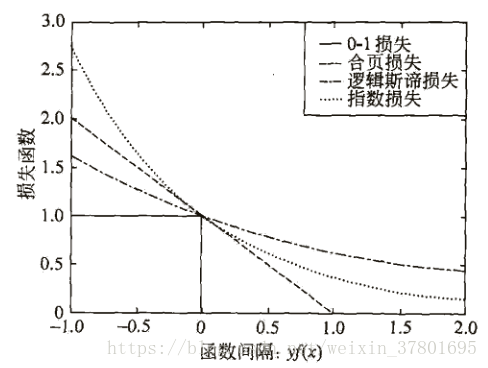
回归模型的损失函数是平方损失函数和绝对损失函数,分类问题的损失函数是0-1损失函数或者交叉信息熵损失函数,概率模型的损失函数是对数损失函数。最小二乘模型损失函数是平方损失函数;支持向量机损失函数是合页损失函数;Boosting的损失函数是指数损失函数;逻辑回归的损失函数是逻辑斯蒂损失函数;决策树的损失函数是对数损失函数;神经网络的损失函数是交叉信息熵损失函数。
二、经验风险和结构风险
1、经验风险
经验风险最小化如下式所示
经验风险值越小,模型的效果“可能”越好,这里说的是可能,不是一定,因为当样本容量很小的时候,经验风险最小化的学习效果不一定好,可能出现过拟合。过拟合是模型复杂度高,参数过多,对已知数据预测的好,对未知数据预测的差,模型对未知数据的预测能力叫做模型的泛化能力,过拟合导致模型的泛化能力差。
2、结构风险
结构风险最小化是解决模型过拟合的方法,结构风险在经验风险上加上罚项,用以权衡经验风险和模型复杂度,如下式所示
三、正则化
1、L1正则化
L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。L1范数可以实现特征的选择,将无用的信息或者噪声信号的参数置为0,避免干扰;L范数使模型具有可接受性,参数的大小表明了特征和目标的相关性大小。
2、L2正则化
L2范数: ||W||2 “岭回归”(Ridge Regression),也叫“权值衰减weight decay”,是指向量各元素的平方和然后求平方根。L2范数会选择更多的特征,成分峰值大的参数。L2范数不但可以防止过拟合,还可以让我们的优化求解变得稳定和快速,解决了ill-condition现象。假设我们有个方程组AX=b,我们需要求解X。如果A或者b稍微的改变,会使得X的解发生很大的改变,那么这个方程组系统就是ill-condition。
3、范数最大值约束
限定参数的二范数取值小于c,
,c的取值是3或者4
4、dropout
dropout以一个概率值来控制网络神经元的活性。
在实际应用中经常使用L2范数、L2范数结合dropout的正则化方法。
写博客的目的是学习的总结和知识的共享,如有侵权,请与我联系,我将尽快处理
详细内容进一步参考:
李航的《统计机器学习》
http://cs231n.github.io/neural-networks-2/#reg
http://blog.csdn.net/zouxy09/article/details/24971995/