最近一直在看yolo算法,感觉有时候只有看懂各种算法底层的实现,才能真正了解这个算法,这不,结合yolo源码和网上各种算法讲解,各种深度算法不再是模糊的印象了,而这里总结了最近看的BatchNormal
1.batchnormal解决了什么问题
1)梯度消失问题
对于网络任一层l,输入
,一般都会经历一下过程:
输出:
,
那么问题来了,假设激活函数
为逻辑函数:
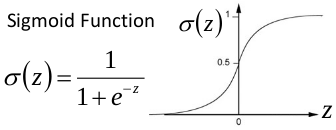
如果某层的z分布在逻辑函数两边的接近水平的地方,也就是梯度接近0的位置,那么网络反向传播这层后,梯度降为接近0,梯度消失,那么参数,也就基本不更新了.

2)参数0均值初始化导致的问题
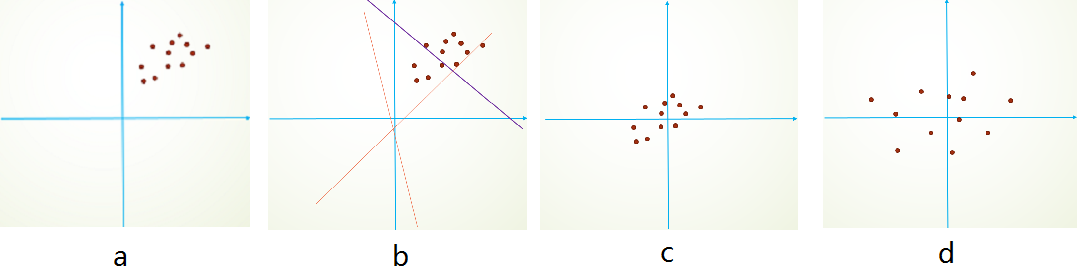
由于初始化的时候,参数一般都是0均值的,因此开始的拟合y=Wx+b,基本过原点附近,如图b红色虚线。因此,网络需要经过多次学习才能逐步达到如紫色实线的拟合,即收敛的比较慢。如果我们对输入数据先作减均值操作,如图c,显然可以加快学习。更进一步的,我们对数据再进行去相关操作,使得数据更加容易区分,这样又会加快训练,如图d。而batchnormal也有这种效果
3)内部迁移(Internal Covariate Shift)
数据经过多层神经网络后,数据分布发生变化,导致各层参数需要不到调整适应分布变化,这会让收敛速度变慢,超参数设定也变得比较复杂,这在论文里作者称作Internal Covariate Shift
那么batchnormal具体如何解决上述的呢,首先了解前行传播
注意以下字母皆为矩阵形式,i为batch里面的索引
2.BN前向传播

设有
_
的batch_size为m,注意这里的i为batch里面的索引,x和a为特征矩阵
由于当前层的输入等于上一层的输出,那么设第l层输出为
,则第l层的输入
i =0,1,2…m
设
前向传播过程:
1.全连接则乘权重,卷积层则对x卷积
2.计算batch_size个z的均值
3)计算batch_size个z的方差:
3)将batch_size个z,归一化成均值为0,方差为1的分布:
经过这个操作后数据就被分布在0为圆心,1为半径的范围内了,这样以上 问题就被成功解决了问题

4)放缩和迁移:
这步的作用在于,以逻辑函数为例,经过1.3后,数据主要分布在线性区域,非线性表达能力会受到影响,所以通过对数据放大或缩小和迁移来进入非线性区域范围
5)激活,输出
yolo的前行传播源码:
void forward_batchnorm_layer(layer l, network net)
{
//如果是batchnormal层,则直接输出等于输入
if(l.type == BATCHNORM) copy_cpu(l.outputs*l.batch, net.input, 1, l.output, 1);
//全链接层,看成通道数为l.outputs,特征图长宽为1
if(l.type == CONNECTED){
l.out_c = l.outputs;
l.out_h = l.out_w = 1;
}
//l.x=l.output,如果按方差求导最终的化简等于0,来计算,l.x后面就用不到了
copy_cpu(l.outputs*l.batch, l.output, 1, l.x, 1);
//训练状态
if(net.train){
//求当前batch的均值,对应公式1.2
mean_cpu(l.output, l.batch, l.out_c, l.out_h*l.out_w, l.mean);
//求当前batch的方差,对应公式1.3
variance_cpu(l.output, l.mean, l.batch, l.out_c, l.out_h*l.out_w, l.variance);
//求均值的滚动平均,预测时,均值的就是这个值,什么是滚动平均,见下面注
scal_cpu(l.out_c, .99, l.rolling_mean, 1);
axpy_cpu(l.out_c, .01, l.mean, 1, l.rolling_mean, 1);
//求方差的滚动平均,预测时,方差用的就是这个值,可以看非训练状态时normalize_cpu()函数的实现和参数
scal_cpu(l.out_c, .99, l.rolling_variance, 1);
axpy_cpu(l.out_c, .01, l.variance, 1, l.rolling_variance, 1);
//对应公式1.4
normalize_cpu(l.output, l.mean, l.variance, l.batch, l.out_c, l.out_h*l.out_w);
//将1.4式子的结果保存到l.x_norm,用于反向传播时相关参数梯度的计算
copy_cpu(l.outputs*l.batch, l.output, 1, l.x_norm, 1);
}
//非训练状态,如预测时
else {
//对应公式1.4
normalize_cpu(l.output, l.rolling_mean, l.rolling_variance, l.batch, l.out_c, l.out_h*l.out_w);
}
//这两步,对应公式1.5,这里l.scale对应gamma,l.biases对应beta
scale_bias(l.output, l.scales, l.batch, l.out_c, l.out_h*l.out_w);
add_bias(l.output, l.biases, l.batch, l.out_c, l.out_h*l.out_w);
}注:
滚动平均:
这里
表示前n个数据的平均值
yolo在这里直接将
,简化计算,
至于为什么可以用这个均值来近似代替整个数据集的分分布,见后面的预测解释,推导
3.BN反向传播过程
首先推导几个值,为后面链式求导用:
设最终的损失函数为
对方差求导:
对均值求导:
这里需用到一个复合函数求导的方法:

所以按这个方法求导:
则,以全连接层为例,求权重和偏差梯度:
同理:
对应yolo代码:
void backward_batchnorm_layer(layer l, network net)
{
//非训练状态
if(!net.train){
l.mean = l.rolling_mean;
l.variance = l.rolling_variance;
}
//求偏差beta的梯度,对应公式2.5
backward_bias(l.bias_updates, l.delta, l.batch, l.out_c, l.out_w*l.out_h);
//求gamma梯度,对应公式2.6
backward_scale_cpu(l.x_norm, l.delta, l.batch, l.out_c, l.out_w*l.out_h, l.scale_updates);
//先计算公式2.3里面的公共项gamma
scale_bias(l.delta, l.scales, l.batch, l.out_c, l.out_h*l.out_w);
//求y对均值的导数,对应公式2.2
mean_delta_cpu(l.delta, l.variance, l.batch, l.out_c, l.out_w*l.out_h, l.mean_delta);
//求y对方差的导数,对应公式2.1,这里按上面化简后的公式,若激活函数为relu应该直接等于0
variance_delta_cpu(l.x, l.delta, l.mean, l.variance, l.batch, l.out_c, l.out_w*l.out_h, l.variance_delta);
//求权重的误差度,对应公式2.3
normalize_delta_cpu(l.x, l.mean, l.variance, l.mean_delta, l.variance_delta, l.batch, l.out_c, l.out_w*l.out_h, l.delta);
//对于BATCHNORM层,直接输出等于输入
if(l.type == BATCHNORM) copy_cpu(l.outputs*l.batch, l.delta, 1, net.delta, 1);
}4.预测:
预测时,计算总体的均值和方差是不实际的,也是无法实现的,因为无法采样到所有样本。用总采样来估计总体的均值和方差呢?也是需要大量计算的,在训练过程中的batch下的均值uB和方差σB,可以加以利用来估计总体
具体推导如下:
:可以理解为 所在分布的期望值
样本均值:
因为抽样和样本同分布,所以:
样本期望:
但
样本方差: $
均值和方差:
即:
所以最终结果:
tag{m为batch_size}$
虽然理论上是这样的,但yolo里面好像用滚动平均值来算,而不是上面的计算方法这部分计算对应前行传播函数forward_batchnorm_layer()里的:
scal_cpu(l.out_c, .99, l.rolling_mean, 1);
axpy_cpu(l.out_c, .01, l.mean, 1, l.rolling_mean, 1);
scal_cpu(l.out_c, .99, l.rolling_variance, 1);
axpy_cpu(l.out_c, .01, l.variance, 1, l.rolling_variance, 1);
Bacthnormal优化办法
1)增大学习率.
BN能减少每层的梯度变化幅度,使梯度稳定在理想的变化范围内,所以大学习率一般不会导致梯度消失
另外大学习率,训练一次,一般会导致参数,如权重变大,假设变大了n倍,即
,其中W’为目前权重,W’为上次训练的权重
设上一次训练,均值为:
方差:
则本次均值:
所以:
即:
可以看出,当因上一次训练的大学习率导致权重W变大n倍后,只会让本次训练的梯度更小,这样一点程度上,便避免了过大学习率导致的梯度爆炸.
2)去掉Dropout_
3)减少L2正则项_,这里不是很理解,难道两者冲突了?
4)提高学习率衰减速度.由于BN收敛速度快,在相同迭代次数,使用BN算法的网络,比未使用相同BN算法的网络,会更快到达相应的衰减点
5)更彻底随机化训练数据._
6)减少图片扭曲_
看了好久,终于略懂一二 :D
主要参考:
论文
Batch Normalize的几点说明
https://zhuanlan.zhihu.com/p/27938792