一、说明
模仿学习(Imitation Learning )是机器学习的一种,代理通过观察和模仿专家的行为来学习。在这种方法中,为代理提供了一组所需行为的演示或示例,并通过尝试复制专家的行为来学习输入观察和输出操作之间的映射。
模仿学习通常用于难以定义代理优化目标函数的场景,例如玩游戏或驾驶汽车等复杂任务。通过从专家演示中学习,代理可以实现高水平的性能,而不需要复杂或手工设计的奖励函数。
模仿学习的主要挑战之一是当代理暴露于新环境或一组不同的输入时处理分布变化。这可能会导致学习的行为变得脆弱或导致意外的失败。领域适应和逆强化学习等技术可以用来解决这个问题。
二、什么是模仿学习?
正如同样本身所暗示的那样,包括人类在内的几乎所有物种都通过模仿和即兴创作来学习。一句话就是进化。同样,我们可以让机器模仿我们并向人类专家学习。自动驾驶就是一个很好的例子:我们可以让代理从数百万个驾驶员演示中学习,并模仿专家驾驶员。
这种从演示中学习也称为模仿学习 (IL),是强化学习和一般人工智能的一个新兴领域。IL在机器人中的应用无处不在,机器人可以通过分析人类主管执行的策略演示来学习策略。
专家缺席与在场: 模仿学习采取 2 个方向,条件是专家在培训期间是否缺席或专家是否在场以纠正代理的行为。让我们谈谈专家缺席时的第一种情况。
三、培训期间专家缺席
专家的缺席基本上意味着代理只能访问专家演示,仅此而已。在这些“专家缺席”任务中,代理尝试使用由专家演示的固定训练集(状态-操作对),以便学习策略并实现与专家尽可能相似的操作。这些“专家缺席”任务也可以称为离线模仿学习任务。
这个问题可以按分类框定为监督学习。专家演示包含许多训练轨迹,每个轨迹都包含一系列观察和专家执行的一系列动作。这些训练轨迹是固定的,不受代理策略的影响,这种“专家缺席”任务也可以称为离线模仿学习任务。
这个学习问题可以表述为监督学习问题,其中可以通过解决一个简单的监督学习问题来获得策略:我们可以简单地训练一个监督学习模型,该模型直接将状态映射到动作上,通过他/她的演示来模仿专家。我们称这种方法为“行为克隆”。

现在我们需要一个替代损失函数来量化所证明的行为和学习策略之间的差异。我们使用最大预期对数似然函数来制定损失。
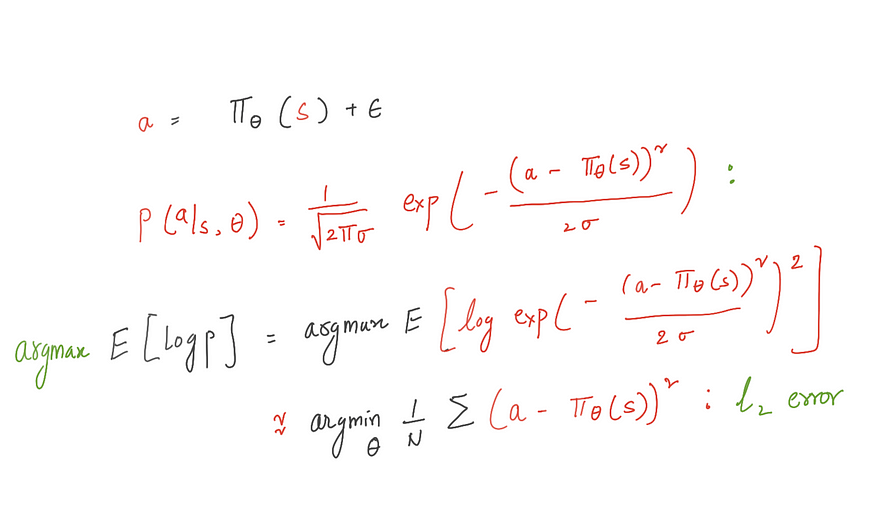
如果我们要解决分类问题,我们选择交叉熵,如果解决回归问题,我们选择 L2 损失。很容易看出,最小化 l2 损失函数等效于最大化高斯分布下的预期对数似然。
四、挑战
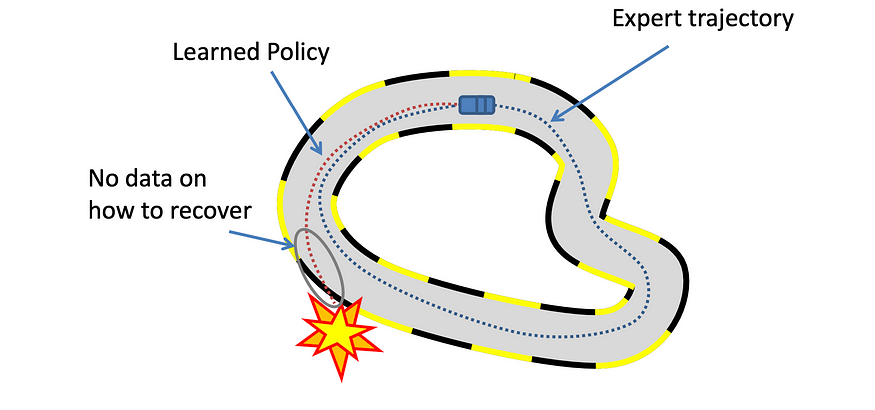
到目前为止,一切看起来都很好,但行为克隆的一个重要缺点是泛化。专家只收集代理可以体验的无限可能状态的子集。一个简单的例子是,专业的汽车驾驶员不会通过偏离航线来收集不安全和危险的状态,但代理可能会遇到这样的危险状态,它可能没有学习纠正措施,因为没有数据。这是因为“协变量偏移”是一个已知的挑战,其中训练期间遇到的状态与测试期间遇到的状态不同,从而降低了鲁棒性和泛化性。
解决这种“协方差偏移”问题的一种方法是收集更多风险状态的演示,这可能非常昂贵。培训期间的专家出席可以帮助我们解决这个问题,并弥合所展示的策略和代理策略之间的差距。
五、专家展示:在线学习
在本节中,我们将介绍最著名的在线模仿学习算法,称为数据聚合方法:DAGGER。 这种方法在缩小训练期间遇到的状态与测试期间遇到的状态之间的差距方面非常有效,即“协变量移位”。
如果专家在学习过程中评估学习者政策怎么办?专家提供了正确的行动,以采取来自学习者自身行为的例子。这正是DAgger试图实现的目标。DAgger的主要优点是专家教学习者如何从过去的错误中恢复过来。
这些步骤很简单,类似于行为克隆,只是我们根据代理到目前为止学到的知识收集了更多的轨迹。
1. 通过对专家演示 D 的行为克隆来初始化政策,从而产生政策
π1 2.代理使用 π1 并与环境交互以生成包含轨迹
1 的新数据集 D3。D = D U D1:我们将新生成的数据集 D1 添加到专家演示 D.
1 中。新的演示 D 用于训练策略 π2.....

为了利用专家的存在,专家和学习者的组合用于查询环境和收集数据集。因此,DAGGER从学习策略诱导的状态分布下的专家演示中学习策略。如果我们设置 β=0,在这种情况下,这意味着期间的所有轨迹都是从学习代理生成的。
六、算法:

DAgger缓解了“协方差偏移”的问题(由学习器策略诱导的状态分布与初始演示数据中的状态分布不同)。这种方法显著减小了获得令人满意的性能所需的训练数据集的大小。
七、结论
DAgger在机器人控制方面取得了非凡的成功,并已应用于控制无人机。由于学习者会遇到专家没有演示如何行动的各种状态,因此在这些应用程序中,诸如 DAGGER 之类的在线学习方法是必不可少的。
在本系列的下一篇博客中,我们将了解DAgger算法的缺点,重要的是我们将强调DAgger算法的安全方面。