作为开发市面上热度最高的AI聊天机器人的公司——OpenAI可以说在最近倍受关注。
在此前Open-AI公布了其大型语言模型的最新版本——GPT-4,用来替代之前在使用的GPT-3.5。

据官方介绍,GPT-4 是一个超大的多模态模型,也就是说,它的输入可以是文字,还可以是图像。
GPT-4比以前的版本“更大”,这意味着它已经借助比之前版本的模型进行了更多数据的训练,并且在模型文件中有更多的权重,从而使得它的运行成本更高。
就任务而言,GPT-4的表现比之前版本的模型更好,它可以遵循自然语言的复杂指令并生成技术或创意内容,而且它可以还更深入地做到这一点:它支持生成和处理多达32768个标记(约25000个文本单词),从而实现比前辈更长的内容创建或文本分析。
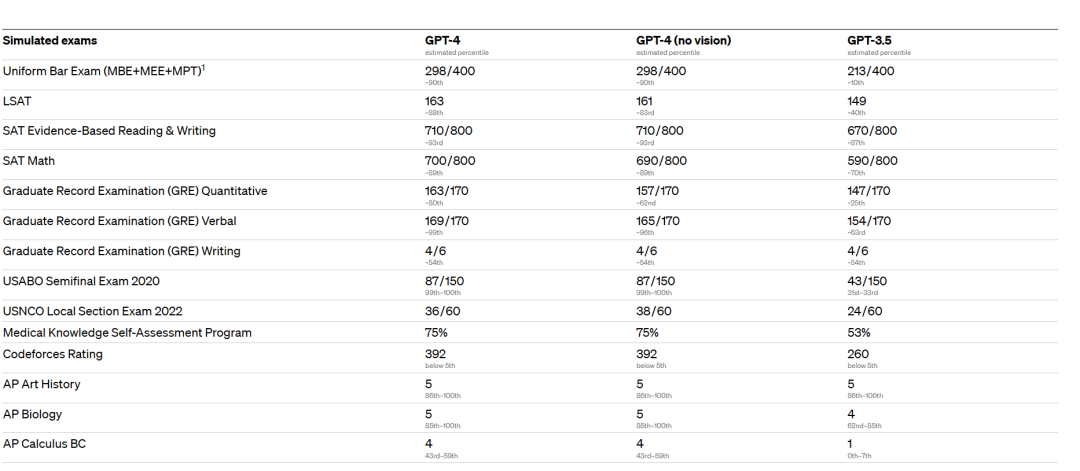
OpenAI表示,GPT-4错误答案更少,而且也会减少偏离话题的可能,也尽可能不会再谈论禁忌话题,甚至在许多标准化测试中比人类表现得都要更好一些。
例如,GPT-4在模拟律师考试的成绩在考生中排名前10%左右,在SAT阅读考试中排名前7%左右,在SAT数学考试中排名前11%左右。相比之下,GPT-3.5在律师考试中的得分一般都是倒数10%左右。
但在最近,不少用户反映称最近使用GPT-4的ChatGPT好像不如之前聪明了。

今日消息,来自斯坦福大学和加州大学伯克利分校的研究团队近日对 GPT-4 进行了深入研究,对比了今年 3 月和 6 月在处理数学问题、生成执行代码和完成视觉推理任务上的差异,发现 “智力”显著下降。

以评估GPT-4 数学能力的“17077 是质数吗?”问题为例,6月的GPT-4产生了错误的答案,认为该数字并非质数。而且GPT-4并没有提供相关解释,准确率从97.6%下降到2.4%。
相比之下,GPT-3.5确实有所改善,最初在3月份产生了错误的答案,在6月份产生了正确的答案。

GPT-4的能力在编码区域也有所下降。研究人员构建了一个新的代码生成数据集,其中包含了LeetCode“容易”类别中的 50 个问题,并评估了AI模型生成的可直接执行程度。
与3月份相比,GPT-4的直接可执行版本从52%下降到10%。这些代在代码前后添加了额外的引号,让其变为注释状态,不可执行。
据之前相关媒体介绍称,有网友表示最近 OpenAI 采用 MOE 重新设计了架构,导致性能受到影响,最终使得ChatGPT的“智力”下降,但是官方一直没有明确答复。