【HuggingFace】RoBERTa分词器RobertaTokenizer编码完整单词
问题描述
在用RobertaTokenizer对单词进行分词的时候,发现单词acquire会被分词两个词根,但是RobertaForMaskedLM可以预测出来单词acquire。
下面的代码可以看到把单词acquire分词成了'ac'和'quire'
from transformers import AutoTokenizer, RobertaForMaskedLM
import torch
tokenizer = AutoTokenizer.from_pretrained("./@_PLMs/roberta/roberta-base")
model = RobertaForMaskedLM.from_pretrained("./@_PLMs/roberta/roberta-base")
inputs = tokenizer("acquire", return_tensors="pt")
# {'input_ids': tensor([[ 0, 1043, 17446, 2]]), 'attention_mask': tensor([[1, 1, 1, 1]])}
tokenizer.decode([1043])
# 'ac'
tokenizer.decode([17446])
# 'quire'
但是把它们放在一起解码的时候,就会合成一个单词:
tokenizer.decode([1043, 17446])
# 'acquire'
RobertaForMaskedLM在预测的时候也可以预测合成词:
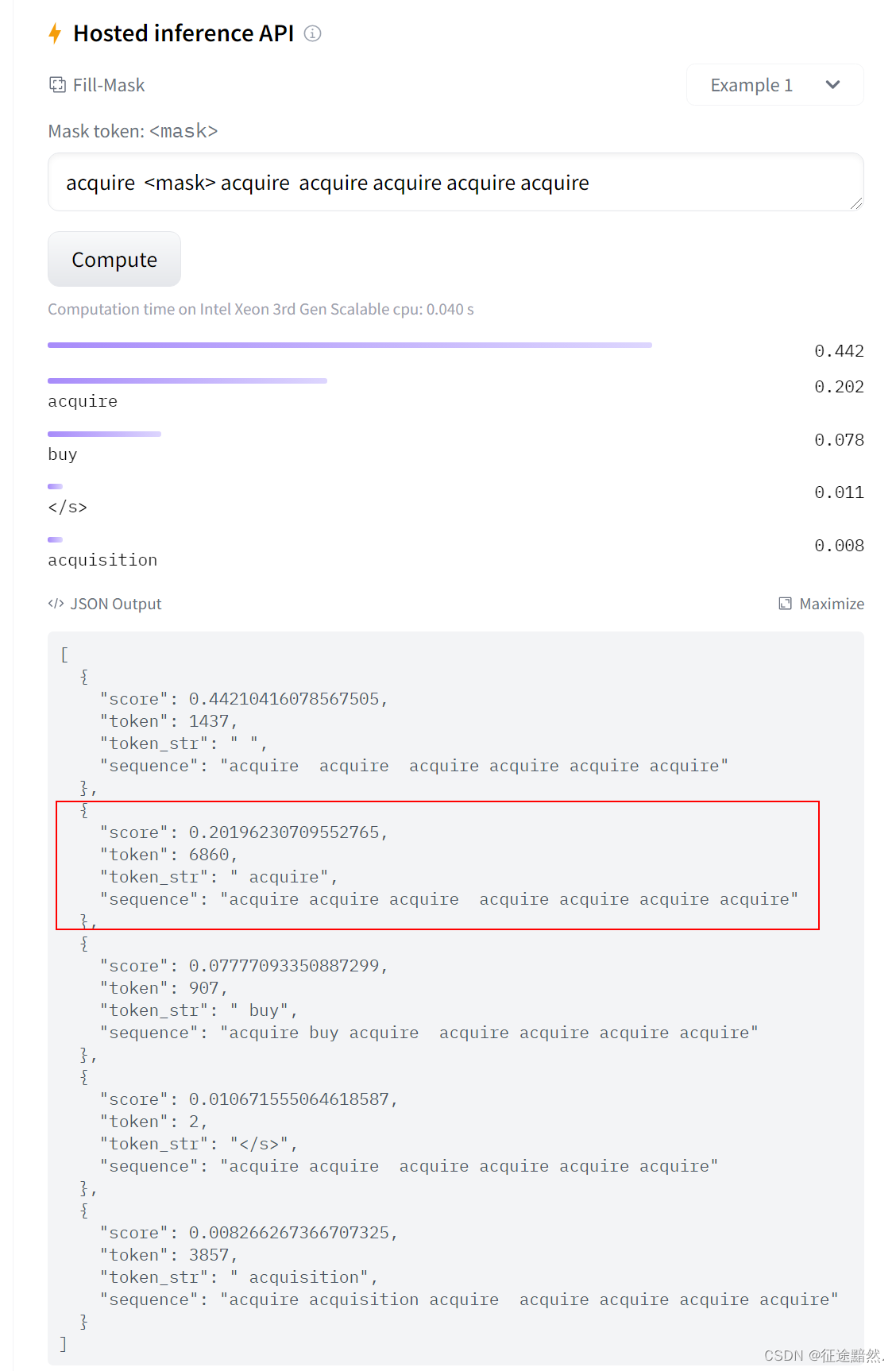
观察上图,发现RobertaForMaskedLM给出的候选词前面全都有一个空格。所以如果我们想要编码一个完整的单词,需要在前面加个空格。
解决方案:在想要编码成完整的单词前面加个空格
在想要编码成完整的单词前面加个空格:
tokenizer(" acquire", return_tensors="pt")
# {'input_ids': tensor([[ 0, 6860, 2]]), 'attention_mask': tensor([[1, 1, 1]])}