DragDiffusion终于开放了,于是果断部署起来。接下来讲一下完整的过程
1.克隆项目
首先你得到GitHub上面将项目克隆下来GitHub - Yujun-Shi/DragDiffusion: Official code for DragDiffusion
git clone https://github.com/Yujun-Shi/DragDiffusion.git具体项目目录如下:

2.下载模型
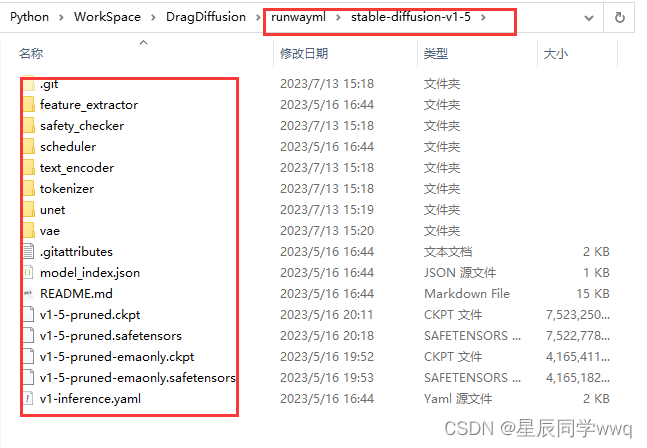
然后你就得下载模型runwayml/stable-diffusion-v1-5 at main

将上面一大堆下载下来放到项目目录下面。
3.创建虚拟环境
官方只在Linux 系统的 Nvidia GPU 上进行过测试,于是我也只在Linux系统上面进行测试。
官网使用如下命令进行虚拟环境安装:
conda env create -f environment.yaml
conda activate dragdiff我并没有直接用environment.yaml,因为这样得慢慢一个一个下,网速很慢,我是提前将一些需要的包提前下好了,这样可以直接用pip install xxx.whl命令安装。

安装好这些下载好的大包,然后直接将environment.yaml中pip安装包拿出来,新建一个requirements.txt使用pip install -r requirements.txt命令安装。

创建好了虚拟环境直接用下面命令激活就好了。
source ./venv/bin/activate4.使用accelerate加速
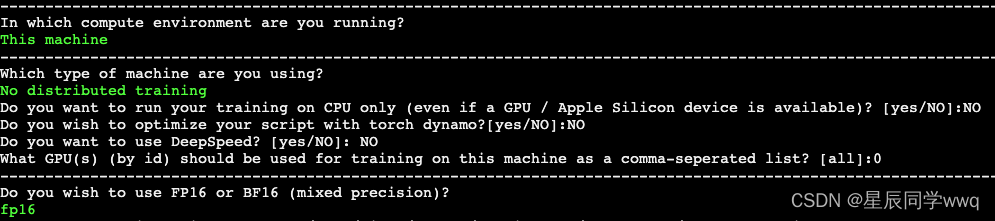
官网上说,在运行 DragDiffusion 之前,可能需要使用以下命令设置“加速”:
accelerate config我也是使用官网上面一样的设置进行加速的:
5.训练Lora
按照官网的说法进行配置:

以下是我的配置,其实只用注意我红色方框框起来的区域:
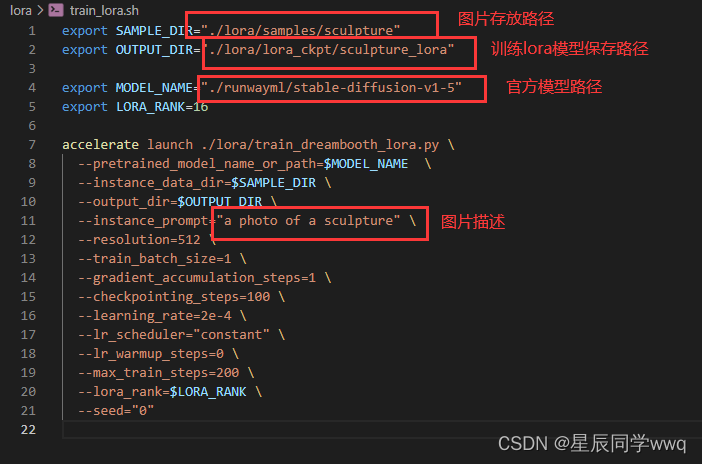
配置好相关路径和信息后,接下来直接运行如下命令训练即可,很快,我4090大概一分钟不到就ok了。这里可能会出现WARINING,不用管,版本的原因,后面有问题再说,hhhh。
bash lora/train_lora.sh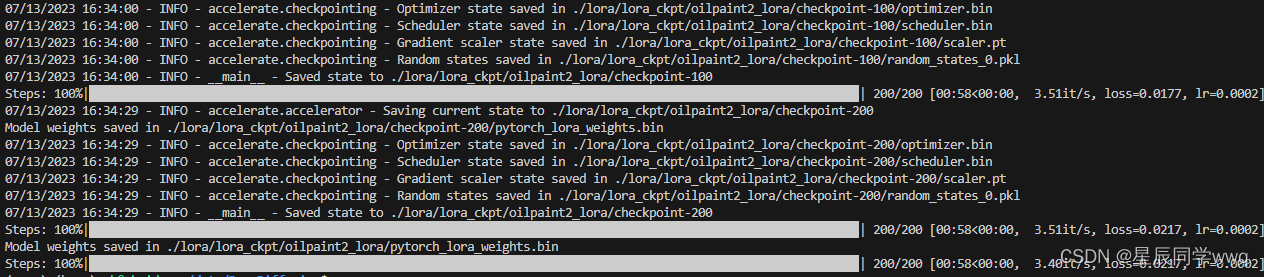
接下来就可以看到lora/lora_ckpt目录中就已经有训练之后的模型文件夹了。
训练完模型,接下来就可以来抓图了,有点小兴奋。
6.开始抓图
直接运行代码开始抓图之旅吧。
python drag_ui_real.py如果想要别人通过内网访问你ip的形式登录抓图,可以直接修改drag_ui_real.py文件最后,加入server_name="0.0.0.0"即可,如果想要修改端口加入server_port=xxxx即可。
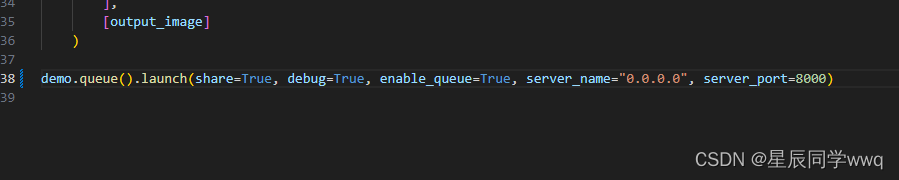
运行之后可以看到命令行输出如下信息。

我们直接按住ctrl+鼠标左键进入浏览器即可进入。
接下来开始添加相关选项就可以抓图了,点击第一个框加入图片,就是上一步用来训练模型的图片,然后在下面第一个文本框中加入图片描述,在第二个文本框中加入上一步训练出来的模型的路径。
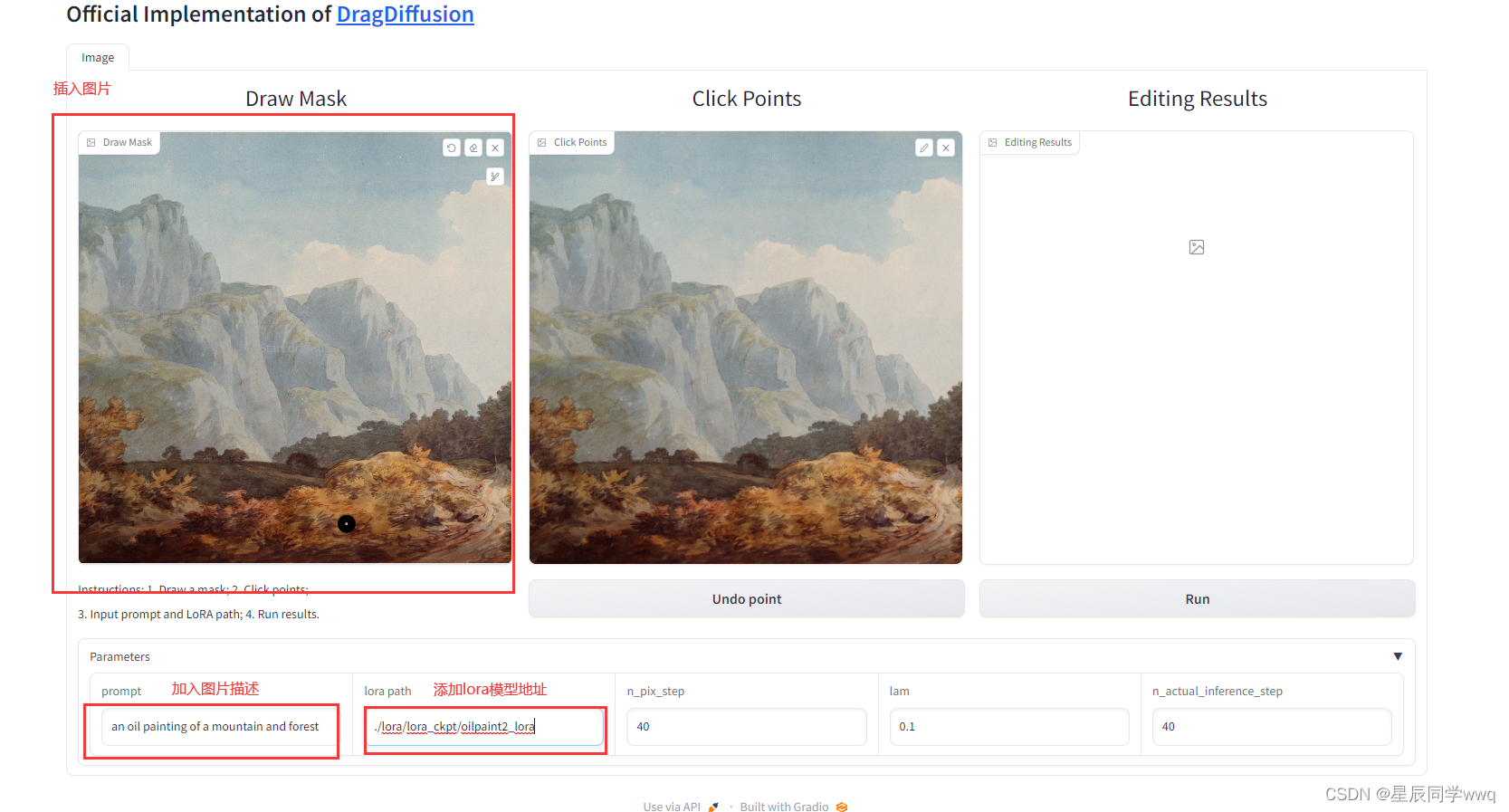
接下来,我想把山增高,首先给第一张图打上马赛克,然后点击第二张图,点击山两下,第一下是开始位置,第二下是延伸的位置。然后点击第三张图未出现位置下面的Run按钮。等待片刻,可以看到山被拔高了。详细操作可以看这个视频:
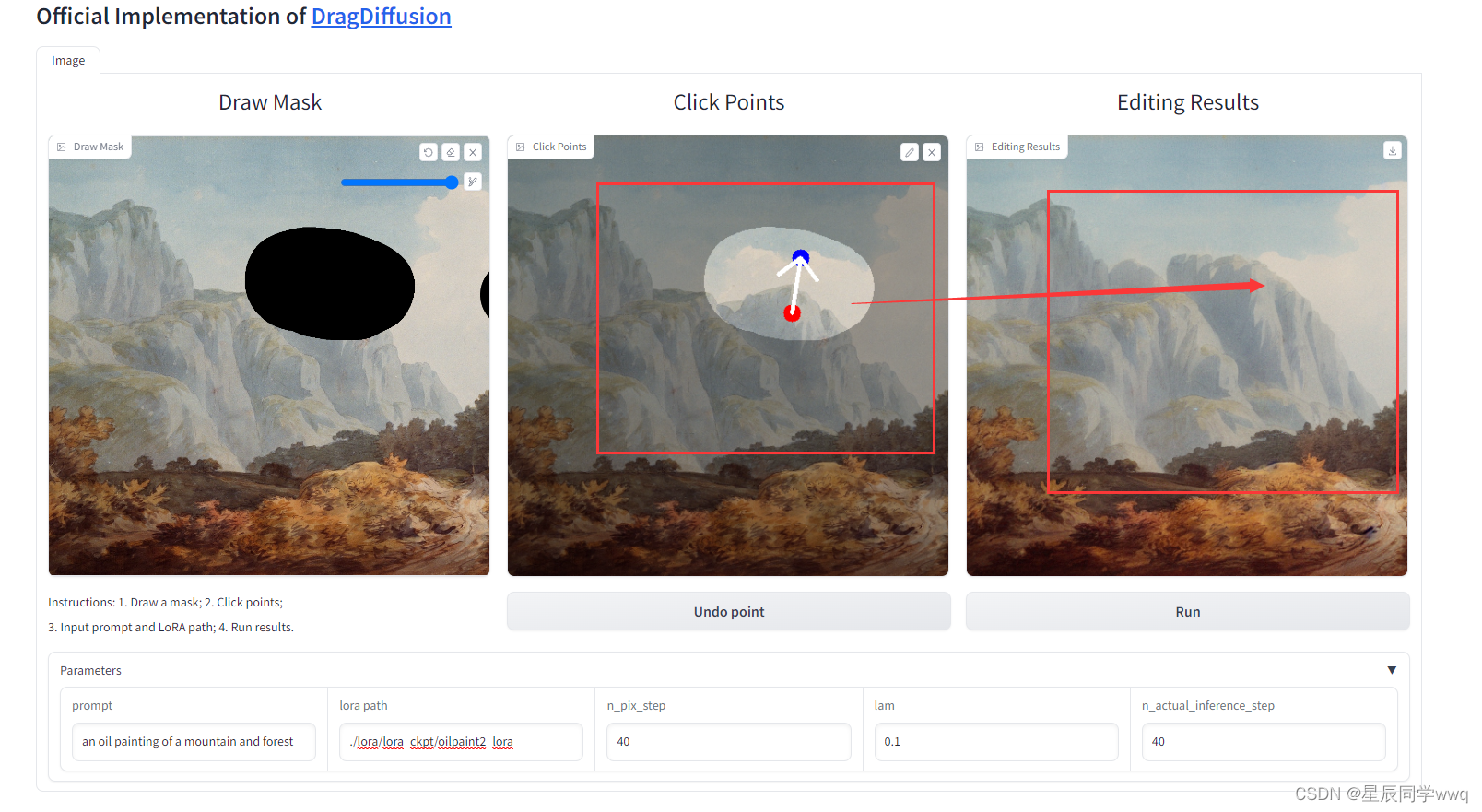
于是不满足与官方提供的图片,我自己打算用自己的图片做了一些测试,果然一样可以。
月亮太小了,我把它拉大,小姐姐腿太细了,我把它拉粗一点,不过分吧,咳咳咳……还挺好看的。

大家可以自己搭建试一试,今天的内容就到这里了,拜了个拜。有问题关注本人下面公众号,添加作者拉你进交流群