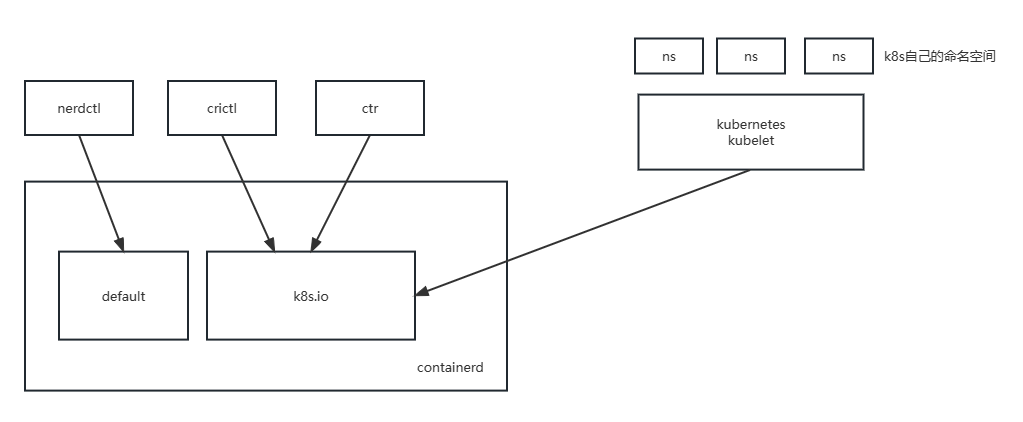
nerdctl默认使用default命名空间,可修改为k8s.io。k8s使用的命名空间为k8s.io,虽然k8s自己本身有很多命名空间(namespace),但实质上就是在使用containerd的k8s.io。
在k8s中创建的容器称为pod--豆荚,当然,pod和普通的容器有所不同。

所谓的pod就是加了层壳的容器,我们可在pod中设置多种策略来方便管理容器,同时一个pod中可包括多个容器,但一般情况下只设置一个容器。pod为k8s下最小调度单位。

当我们想创建一个pod时,首先通过kubectl或其他可视乎工具来连接matser node(control plane控制平面节点)的kube-apiserver,apiserver将该请求发送给kube-scheduler(调度器),scheduler会根据自身算法按各worker节点的资源将工作分配给符合条件的worker。
然后scheduler会反馈给apiserver,apiserver会将请求反馈至worker上的kubectl,kubectl则调动runtime生成pod。自k8s1.24开始,不再使用docker作为runtime,而是使用containerd。
在每个worker节点需安装kubelet来控制runtime生成容器、pod,kubelet相当于runtime的客户端。
管理pod需要使用控制器,在k8s中有许多控制器,管理所有控制器的组件为kube-controller-manager。
在k8s下所做的所有操作都需一个数据库来记录(etcd),etcd并不属于master但在master上运行。实际中,需对etcd做高可用。
外界客户端无法直接访问pod,虽可设置,但pod挂掉后重启一个新的,IP地址会改变,因此一般外界不会直接访问pod。我们需建立一个类似负载均衡的东西(service svc)。svc会关联到后端的pod上,从此外界访问svc即可,然后svc将信息发送给pod。svc通过iptables或ipvs技术来实现转发,而决定使用哪种技术是由配置组件(kube-proxy)实现,默认情况下是iptables。因此,每个worker node上都需配置一个kube-proxy。
如果想打通跨节点的pod间的相互通信,可使用BGP、Vxlan、openvswitch等技术建立高速通信隧道。但我们实际上没必要因此去学以上技术,我们可以使用别人打包好的产品:calico、flannel等,以上产品都遵循CNI标准(容器网络接口标准)。
安装:
采用一个master加一个worker的结构进行演示。
| master | worker |
| 26.91 | 26.92 |
所有节点:
配置hosts文件、关闭swap、关闭防火墙、配置yum源。
参数设置:
/etc/modules-load.d/containerd.conf
overlay
br_netfilter
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1modprobe overlay
modprobe br_netfilter
yum install containerd.io cri-tools -y
配置containerd:
systemctl enable containerd --now
安装nerdctl
mkdir -p /opt/cni/bin/ /etc/nerdctl/ /etc/containerd/certs.d/docker.io
kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.25.2 --pod-network-cidr=10.244.0.0/16
然后按要求,二选一进行创建目录并赋权。
获取worker节点加入集群的命令:
没有该yaml的可以在如下地址下载:wget https://docs.projectcalico.org/manifests/calico.yaml
需修改pod所在网段以及网卡以避免多张网卡带来的不便。
如果希望可以使用tab补全命令,可修改/etc/profile,添加
source <(kubectl completion bash)wq,source /etc/profile
注意:所有对集群的命令都在master上执行。
#查看节点数
kubectl get nodes
#查看集群信息
kubectl cluster-info
#查看集群版本
kubectl version --short
#查看集群配置
kubectl get cm kubeadm-config -n kube-system -o yaml
#想查看所有资源类型名的简写,比如pod--po,namespace--ns
kubectl api-resources其中访问apiserver时,我们需要知道其地址,可通过kubectl cluster-info来查看。
到此,一个k8s集群安装完毕。
在master上将worker节点从集群踢出去:
首先将该节点设置为可调度的(维护模式),此时集群会将该节点上运行的pod驱逐到其他节点上运行。kubectl drain vms92.rhce.cc --ignore-daemonsets --delete-emptydir-data
然后删除该节点:kubectl delete nodes vms92.rhce.cc
此时kubectl get nodes 会发现列表中该节点消失。
如果需要将该节点再次加入集群,首先需清空节点上的配置:
kubeadm reset
然后去master上执行获取加入集群命令的命令:kubeadm token create --print-join-command,将反馈的命令再次执行。如果还记得之前加入集群的命令也可跳过这步在清空配置后直接执行。但如果是master重新格式化(重置加入集群),那么需要重新安装calico。
如果再次加入集群出错的话,需要将/etc/kubernetes/pki和/var/lib/kubelet/两个目录下的内容清空,然后再次加入集群即可。当然也有可能是containerd服务未设置自启或worker下/var/run/containerd/没有containerd.sock该文件,需再次执行crictl config runtime-endpoint unix:///var/run/containerd/containerd.sock,如果执行完没有产生文件,则需要重启containerd服务并再次执行。