前言
今天学长向大家分享一个 毕业设计项目:
基于java web的搜索引擎的设计与实现
项目获取:
https://gitee.com/sinonfin/L-javaWebSha
一、项目设计
1. 模块设计
经过对搜索引擎的研究同时与Lucene自身的特性相结合,将本次设计所需要实现的功能阐述如下:
- 支持桌面文件搜索,格式包括txt、doc、xls和ppt;
- 支持分词查询
- 支持全文搜索
- 能够高亮显示搜索关键字
- 显示查询所用的时间
显示搜索历史、过滤关键字
分词查询与全文搜索这两项功能,我们都可以利用Lucene本身自带的库加上相关算法就可以完成设计了,为了使得关键字的高亮度这一问题得到解决,显然,我们需要利用Highlighter的辅助,通过数据库持久化保存数据。
在我们进行需求分析的时候,制定的用例以及领域模型都可以直接的带入到设计阶段,我们粗略设计的搜索引擎系统的构架如下:
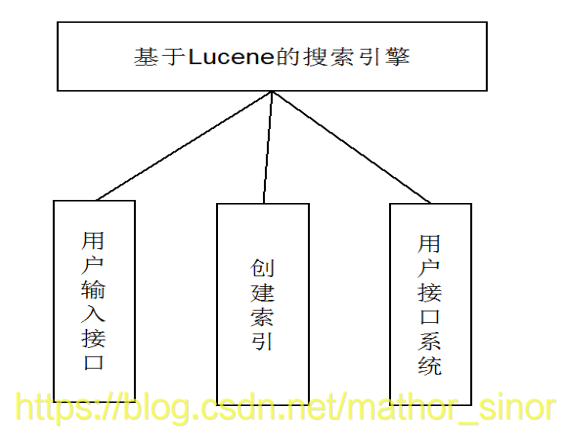
2. 实现效果
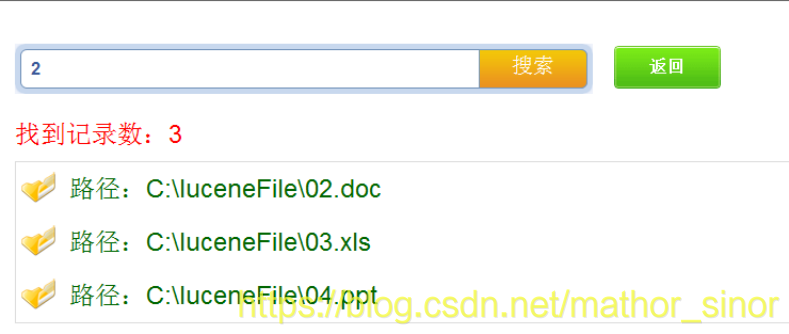
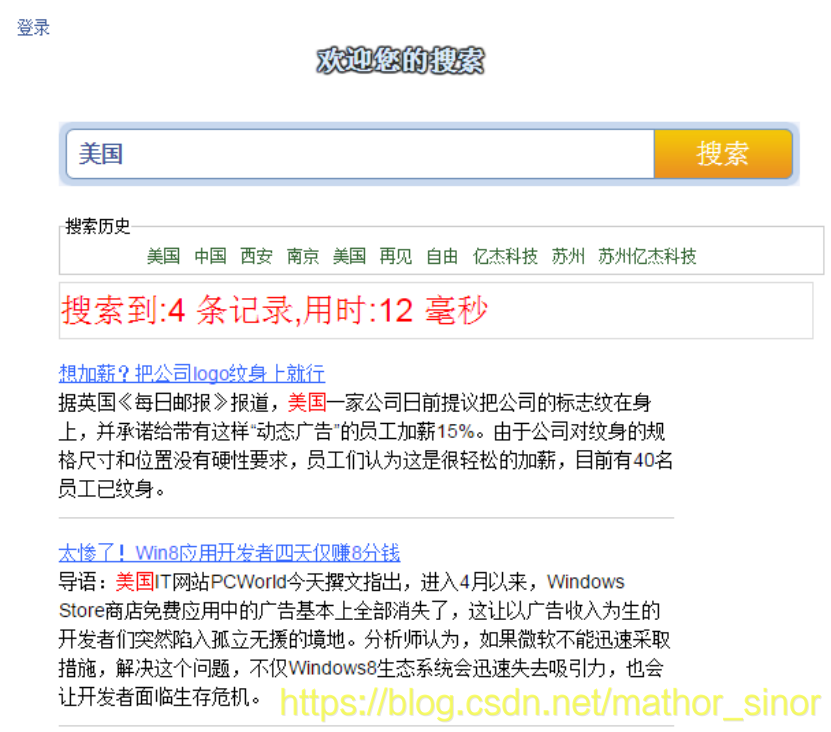

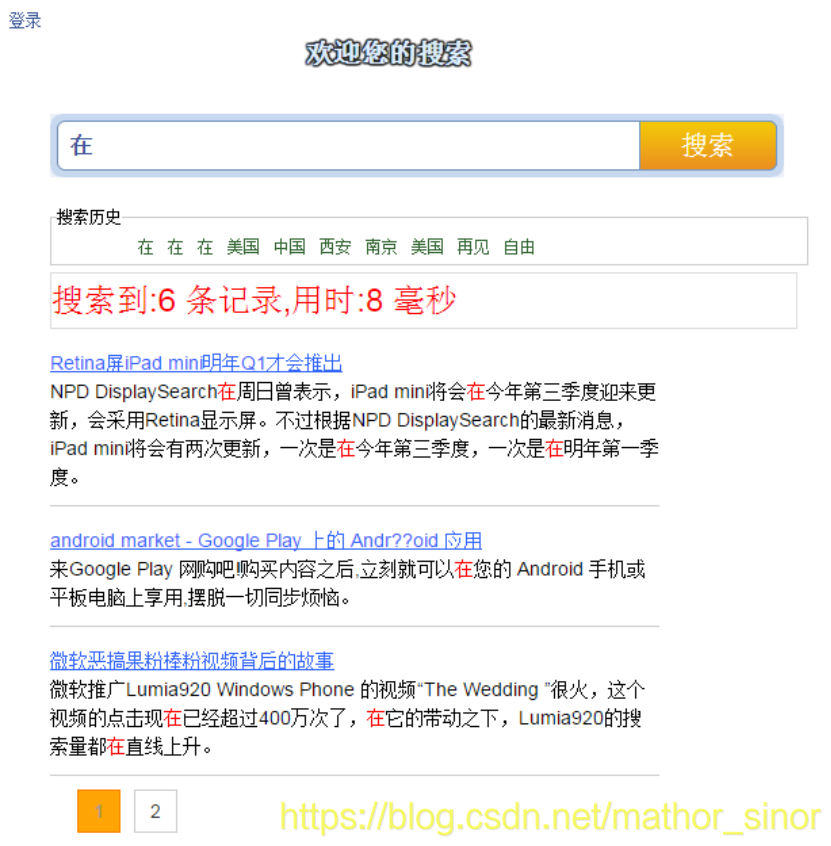
功能较多,学长这里就不一 一展示了
二、部分源码
源码较多,文章篇幅有限,这里就不放上来了,仅展示小部分关键代码
部分代码示例:
/**
* 为数据库检索数据创建索引
* @param rs
* @throws Exception
*/
private void createIndex(ResultSet rs) throws Exception {
Directory directory = null;
IndexWriter indexWriter = null;
try {
indexFile = new File(searchDir);
if(!indexFile.exists()) {
indexFile.mkdir();
}
directory = FSDirectory.open(indexFile);
analyzer = new IKAnalyzer();
indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.UNLIMITED);
indexWriter.setMaxBufferedDocs(maxBufferedDocs);
Document doc = null;
while(rs.next()) {
doc = new Document();
Field id = new Field("id", String.valueOf(rs.getInt("id")), Field.Store.YES, Field.Index.NOT_ANALYZED, TermVector.NO);
// Field title = new Field("title", rs.getString("title") == null ? "" : rs.getString("title"), Field.Store.YES,Field.Index.ANALYZED, TermVector.NO);
Field content = new Field("content", rs.getString("content") == null ? "" : rs.getString("content"), Field.Store.YES,Field.Index.ANALYZED, TermVector.NO);
doc.add(id);
doc.add(content);
indexWriter.addDocument(doc);
}
indexWriter.optimize();
indexWriter.close();
} catch(Exception e) {
e.printStackTrace();
}
}