获取51job职位信息(python3.x环境)
import re
import xlwt
import chardet
from urllib import request
import random
def getHtml(url):
USER_AGENTS = []
proxies = []
req = request.Request(url)
req.add_header('User-Agent', random.choice(USER_AGENTS))
proxy_support = request.ProxyHandler({"http": random.choice(proxies)})
opener = request.build_opener(proxy_support)
request.install_opener(opener)
res = request.urlopen(req)
html = res.read()
return html
def get_Datalist(page_number, jobname):
URL = "https://search.51job.com/list/020000,000000,0000,00,9,99," \
+urllib.parse.quote(jobname)+",2," + str(page_number) + ".html?lang=c&stype=&postchannel\
=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=\
99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=\
9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
html = getHtml(URL)
code = chardet.detect(html)["encoding"]
html = html.decode(code,'replace').encode("utf-8")
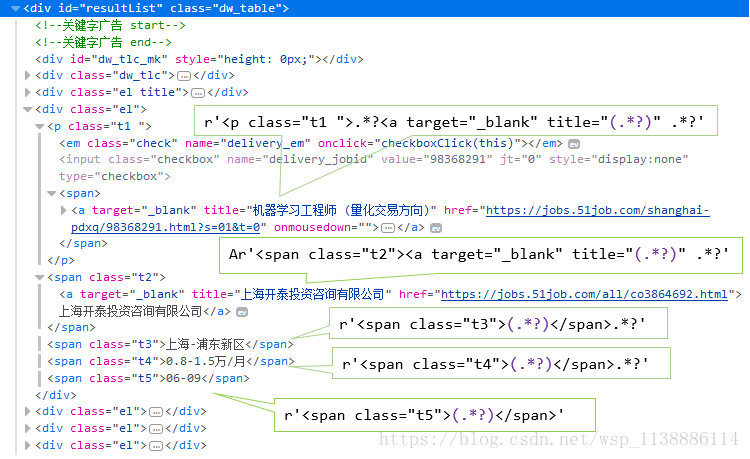
reg = re.compile(r'<p class="t1 ">.*?<a target="_blank" title="(.*?)" .*?'
r'<span class="t2"><a target="_blank" title="(.*?)" .*?'
r'<span class="t3">(.*?)</span>.*?'
r'<span class="t4">(.*?)</span>.*?'
r'<span class="t5">(.*?)</span>', re.S)
result = re.findall(reg, html.decode("utf8",'replace'))
return result
datalist = []
def solve_data(page_number, jobname):
global datalist
for k in range(int(page_number)):
data = get_Datalist(k + 1, jobname)
for i in data:
datalist.append(i)
def save_Excel(jobname, filename):
book = xlwt.Workbook(encoding="utf-8")
sheet = book.add_sheet("51job" + str(jobname) + "职位信息")
col = ('职位名', '公司名', '工作地点', '薪资', '发布时间')
for i in range(len(col)):
sheet.write(0, i, col[i])
for i in range(len(datalist)):
for j in range(len(datalist[i])):
sheet.write(i + 1, j, datalist[i][j])
book.save(u'51job' + filename + u'职位信息.xls')
def main(jobname, page_number, filename):
solve_data(page_number, jobname)
save_Excel(jobname, filename)
main(u"机器学习工程师", "2", u"机器学习职业1")
豆瓣电影Top250(Python3.x环境)
import requests
from bs4 import BeautifulSoup
import chardet
import re
import xlwt
import time
def getHtml(index):
print('正在抓取第',index+1,'页信息')
url = 'https://movie.douban.com/top250?start='+str(index*25)+'&filter='
r = requests.get(url)
code = chardet.detect(r.content)['encoding']
return r.content.decode(code)
reg = re.compile('.*(\d{4}).*')
def getData(n):
datalist = []
for step in range(n):
global reg
time.sleep(0.2)
html = getHtml(step)
soup = BeautifulSoup(html,'html.parser')
parent = soup.find('div',attrs={'id':'content'})
lis = parent.find_all('li')
for li in lis:
data = []
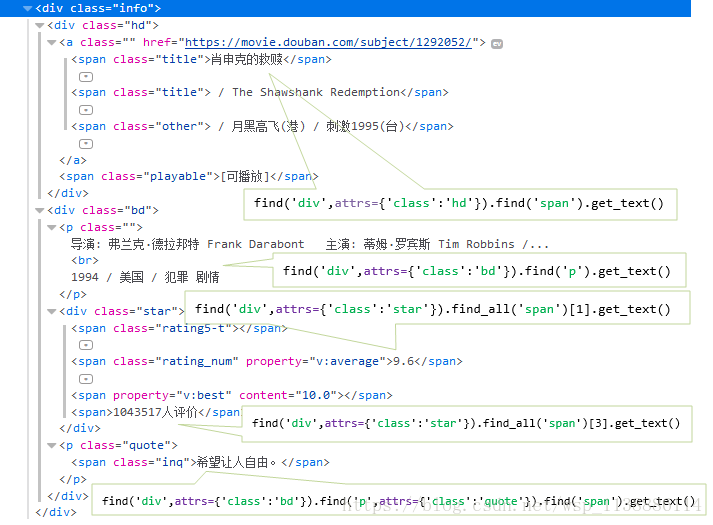
film_name = li.find('div',attrs={'class':'hd'}).find('span').get_text()
data.append(film_name)
film_time_str = li.find('div',attrs={'class':'bd'}).find('p').get_text()
film_time = re.findall(reg,film_time_str)[0]
data.append(film_time)
film_score = li.find('div',attrs={'class':'star'}).\
find_all('span')[1].get_text()
data.append(film_score)
person_number = li.find('div',attrs={'class':'star'}).\
find_all('span')[3].get_text()
number = re.findall(re.compile('\d*'),person_number)[0]
data.append(number)
if li.find('div',attrs={'class':'bd'}).\
find('p',attrs={'class':'quote'}):
evaluate = li.find('div',attrs={'class':'bd'}).\
find('p',attrs{'class':'quote'}).find('span').get_text()
else:
evaluate = ''
data.append(evaluate)
datalist.append(data)
return datalist
def saveToExcel(n,fileName):
book = xlwt.Workbook()
sheet = book.add_sheet('豆瓣电影Top250')
data=getData(n)
col = ('电影名称','上映年份','电影评分','评分人数','电影简评')
for k,v in enumerate(col):
sheet.write(0, k, v)
for i,each in enumerate(data):
for j,value in enumerate(each):
sheet.write(i+1, j, value)
book.save(fileName)
saveToExcel(10,'豆瓣.xls')
print('结束')
爬取西刺代理网站(python 3.x环境)
import requests
from bs4 import BeautifulSoup
import re
import chardet
import random
data_dic_http=[]
data_dic_https =[]
def get_IP(n=5):
userAgent = [……]
url = "http://www.xicidaili.com/"
r = requests.get(url, headers={"User-Agent": random.choice(userAgent)})
code = chardet.detect(r.content)["encoding"]
html=r.content.decode(code)
soup=BeautifulSoup(html,"html.parser")
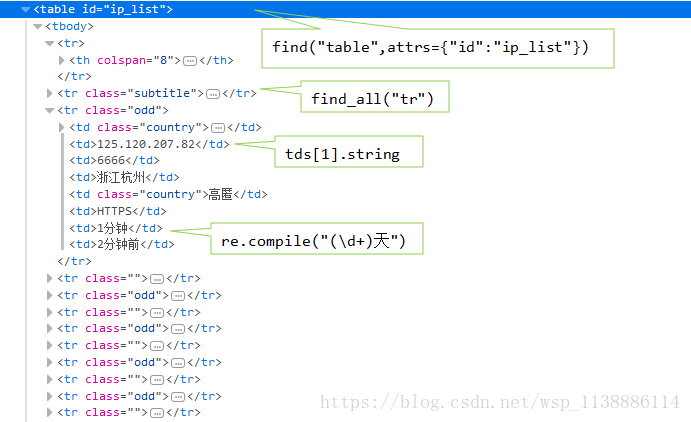
parentTable=soup.find("table",attrs={"id":"ip_list"})
trs=parentTable.find_all("tr")
for i in range(2):
trs.pop(0)
for each in trs:
if each.find_all("td"):
tds=each.find_all("td")
reg=re.compile("(\d+)天")
days=re.findall(reg,tds[6].string)
if days:
if tds[5].string=="HTTPS" and int(days[0])>=10:
data_dic_https.append(tds[1].string+":"+tds[2].string)
elif tds[5].string=="HTTP" and int(days[0])>=10:
data_dic_http.append(tds[1].string + ":" + tds[2].string)
else:
continue
else:
continue
if len(data_dic_http)>=n and len(data_dic_http)>=n:
break
return data_dic_http,data_dic_https
http_list,https_list=get_IP(10)
print(http_list)
>>> ['222.185.22.247:6666', '123.134.87.136:61234', '14.118.255.8:6666', \
'117.67.11.136:8118', '115.28.90.79:9001', '112.115.57.20:3128', \
'123.57.217.208:3128', '222.185.22.247:6666', '123.134.87.136:61234', '14.118.255.8:6666']
print(https_list)
>>> ['115.204.25.93:6666', '120.78.78.141:8888', '1.196.161.172:9999', \
'121.231.32.205:6666', '122.72.18.35:80', '101.37.79.125:3128', \
'118.212.137.135:31288', '120.76.231.27:3128', '122.72.18.34:80', \
'115.204.25.93:6666', '1.196.161.172:9999', '121.231.32.205:6666', \
'122.72.18.35:80', '101.37.79.125:3128', '118.212.137.135:31288', \
'120.76.231.27:3128', '122.72.18.34:80']
Scrapy结合 CSS+xpath实战:爬取梦幻西游门派音乐
win+r 打开cmd 执行:scrapy startproject Music
◆ 在 spiders 目录下创建Get_Music.py文件
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from Music.items import MusicItem
import re
class Music_menghua(CrawlSpider):
name = "Get_Music"
start_urls = ["http://xyq.163.com/download/down_music.html"]
def parse(self, response):
item = MusicItem()
selector = Selector(response)
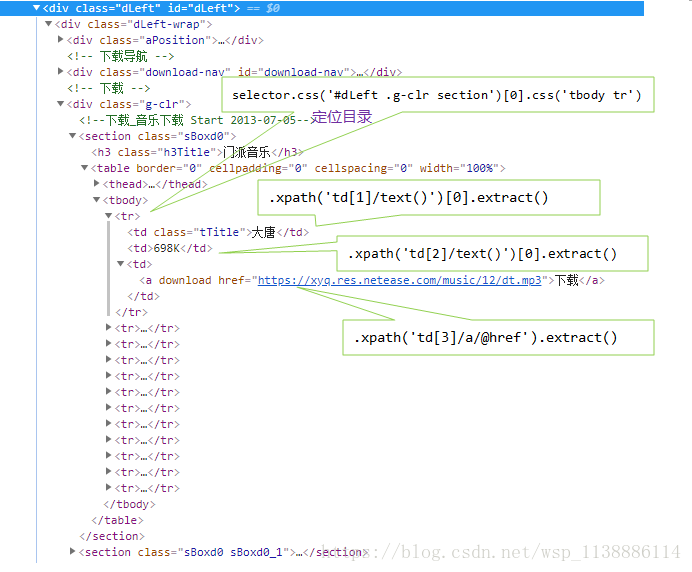
Music_List = selector.css('#dLeft .g-clr section')[0].css('tbody tr')
for tr in Music_List:
music_name = tr.xpath('td[1]/text()')[0].extract()
time_range = tr.xpath('td[2]/text()')[0].extract()
music_link = tr.xpath('td[3]/a/@href').extract()
print('3333333333333333333333333333', time_range)
item['music_name'] = music_name
item['time_range'] = time_range
item['music_link'] = music_link
yield item
◆ 编辑 items.py文件
import scrapy
from scrapy import Field,Item
class MusicItem(scrapy.Item):
music_name = Field()
time_range = Field()
music_link = Field()
pass
◆ 编辑 settings.py 文件
BOT_NAME = 'Music'
SPIDER_MODULES = ['Music.spiders']
NEWSPIDER_MODULE = 'Music.spiders'
USER_AGENT =['Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5']
FEED_URI = u'file:///D:/learning_code_scrapy/Music.csv'
FEED_FORMAT = 'CSV'
◆ 在spiders新建main.py(主函数),并编辑。--与items.py为同级文件
from scrapy import cmdline
cmdline.execute("scrapy crawl Get_Music".split())