在做本科毕业设计的时候,Sketchmate的CNN分支使用了Resnet50,现在重新复习一下残差神经网络。这篇文章主要整理一下,Resnet怎么应对梯度消失?为什么能训练很深的模型?这里从梯度的角度总结一下。
有关Resnet结构的问题,可参考《动手学深度学习》7.6节:
一. 如何处理梯度消失?
将乘法运算变成加法运算。(ResNet就是这么做的,特别是残差连接(Residual Connection))
二. 残差块如何处理梯度消失?
(1)考虑一个预测模型:
其中:
- x:输入
- f:表示神经网络模型
- y:输出
- w:要训练的网络权重
那么对于权重的更新,有:
这里η表示学习率。众所周知,学习率表示了迈的步子的大小,而梯度表示了迈步子的方向。因此,y 对 w 的梯度不能太小,如果太小的话,η 无论多大都不会起作用,并且也会影响数值的稳定性。
因为反向传播从输出向输入层传播,所以离输入比较近的层的权重最容易发生梯度消失的问题。
(2)现在我们在一个网络上再堆叠(串联)另一个网络:
它对权重的导数项由复合函数求导的链式法则很容易得到:
经过链式法则展开之后:第二项 y 关于 w 的梯度和之前第一部分的结果是一样的,没有任何变化;第一项 g(y) 关于 y 的梯度是新加的层的输出对输入的导数,它和预测值与真实值之间的差别有关系。假设预测的值和真实值之间的差别比较小的话,第一项的值就会变得特别小。这是因为,假设所加的层的拟合能力比较强,第一项就会变得特别小,这种情况下和第二项相乘之后,乘积的值就会变得特别小,也就是梯度就会变得特别小。就只能增大学习率,但可能增大也不是很有用,因为这是靠近底部数据层的更新。如果学习率增加得太大,很有可能新加的层中的w就已经很大了,这样的话可能会导致数值不稳定。
正是因为堆叠网络之后链式法则导致的梯度乘法存在,如果中间有一项比较小的话,可能就会导致整个式子的乘积比较小,越到底层的话乘积就越小。
(3)使用残差连接的方式对原有的模型进行加深:
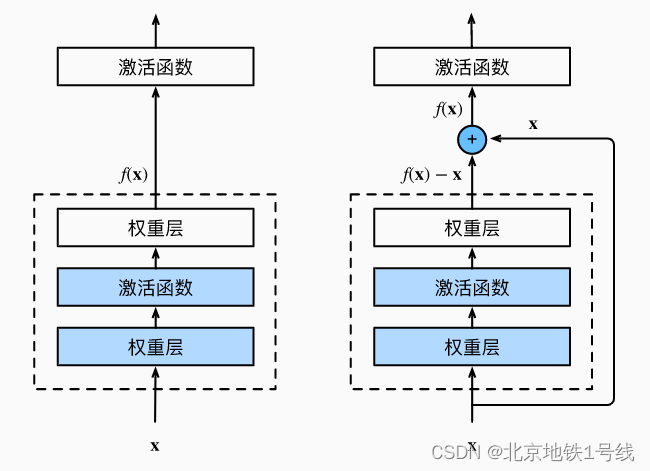
这时候的导数项:
使用加法的求导对模型表达式进行展开得到两项,第一项和前面所说的一样,就是最初的部分。
对于这两项来说,就算第二项的值比较小,但还是有第一项的值进行补充(大数加上一个小数还是一个大数,但是大数乘以一个小数就可能变成小数),正是由于跨层数据通路的存在,模型底层的权重相比于模型加深之前不会有大幅度的缩小。
靠近数据端的权重 w 难以训练,但是由于加入了跨层数据通路,所以在计算梯度的时候,上层的loss可以通过跨层连接通路直接快速地传递给下层,所以在一开始,下面的层也能够拿到比较大的梯度。
从梯度大小的角度来解释,residual connection 使得靠近数据的层的权重 w 也能够获得比较大的梯度,因此,不管网络有多深,下面的层都是可以拿到足够大的梯度,使得网络能够比较高效地更新。