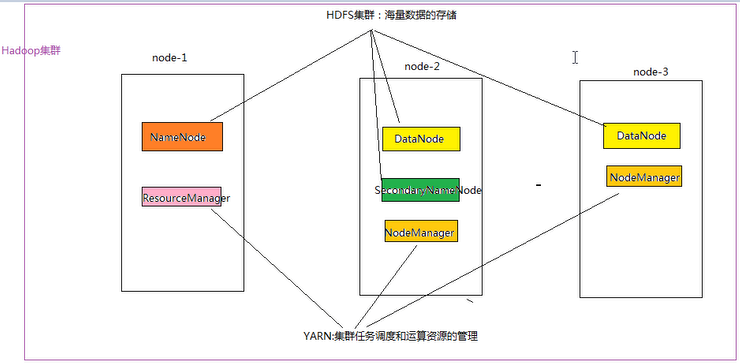
一:Hadoop集群简介:
Hadoop 集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起;
HDFS集群:负责海量数据的存储,集群中的角色主要有: NameNode、DataNode、SecondaryNameNode;
YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有: ResourceManager、NodeManager;
那么 Mapreduce 是什么呢:它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,
然后打包运行在 HDFS 集群上,并受到 YARN 集群的资源调度管理,由 YARN 为Mapreduce 程序分配运算硬件资源;
二:Hadoop集群安装部署:
Hadoop包含HDFS集群和YARN集群。部署Hadoop就是部署HDFS和YARN集群
Hadoop部署方式分为三种,Standalone mode(独立模式)、Pseudo-Distributed mode(伪分布式模式)、Cluster rmode
(群集模式),其中前两种都是在单机部署
1. 独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试
2. 伪分布模式也是在1个机器上运行 HDFS 的NameNode和DataNode、YARN的ResourceManger和NodeManager,但分别启
动单独的java进程,主要用于调试
3. 集群模式主要用于生产坏境部署,会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在
不同的机器上
4. 本集群搭建案例,以4节点为例进行搭建,角色分配如下:
| 主机名 | IP | 角色 |
|---|---|---|
| amaster | 192.168.37.143 | Name Node:9000 Resource Manager |
| anode1 | 192.168.37.129 | Data Node Node Manager |
| anode2 | 192.168.37.130 | Data Node Node Manager |
| anode3 | 192.168.37.131 | Data Node Node Manager |
示例图: