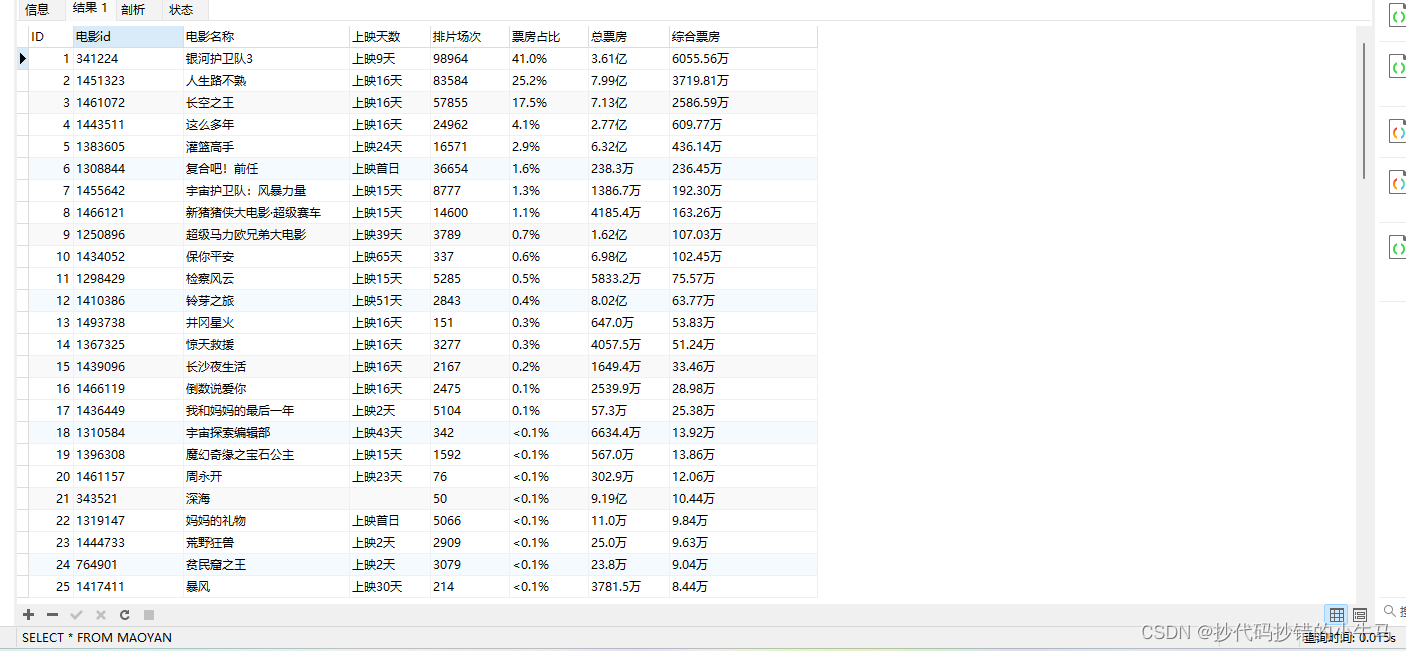
学习记录:
目录
一、目标网址分析
网页:aHR0cHM6Ly9waWFvZmFuZy5tYW95YW4uY29tL2Rhc2hib2FyZA==
接口:aHR0cHM6Ly9waWFvZmFuZy5tYW95YW4uY29tL2Rhc2hib2FyZC1hamF4P29yZGVyVHlwZT0wJnV1aWQ9MTg4MTI5YmEzZWZjOC0wOWUzYjdkZWQ3OTNhNC03YjUxNTQ3Ny0xZmE0MDAtMTg4MTI5YmEzZWZjOCZ0aW1lU3RhbXA9MTY4NDAyNjM1NTA4NiZVc2VyLUFnZW50PVRXOTZhV3hzWVM4MUxqQWdLRmRwYm1SdmQzTWdUbFFnTVRBdU1Ec2dWMmx1TmpRN0lIZzJOQ2tnUVhCd2JHVlhaV0pMYVhRdk5UTTNMak0ySUNoTFNGUk5UQ3dnYkdsclpTQkhaV05yYnlrZ1EyaHliMjFsTHpFeE15NHdMakF1TUNCVFlXWmhjbWt2TlRNM0xqTTJJRVZrWnk4eE1UTXVNQzR4TnpjMExqUXkmaW5kZXg9NjYxJmNoYW5uZWxJZD00MDAwOSZzVmVyc2lvbj0yJnNpZ25LZXk9MzFmNGFhZjUxZmM0ZjRmMDJjODc2MjdhYjYzOWVmMDg=
网页源代码查看:

参数查看:
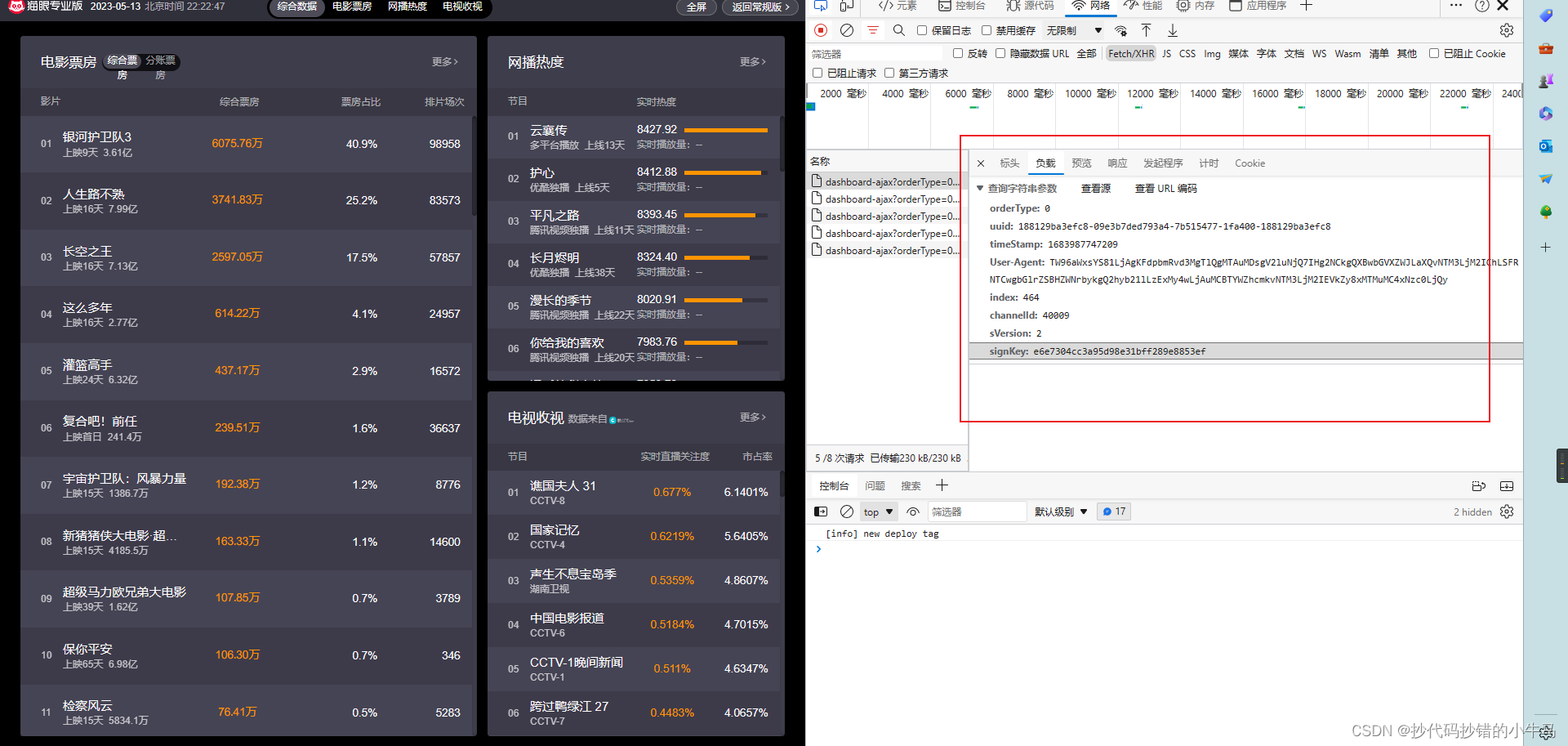
返回接口查看:

进行分析:接口为 get 请求,其部分参数通过JS进行加密,目标接口返回的数据中的综合票房是进行了字体反爬。接口实时刷新返回数据,其返回的字体映射文件也是实时变换。
实现步骤:
1、F12进行JS逆向调试,分析參數

2、模拟发送请求,拿到接口参数进行数据解析
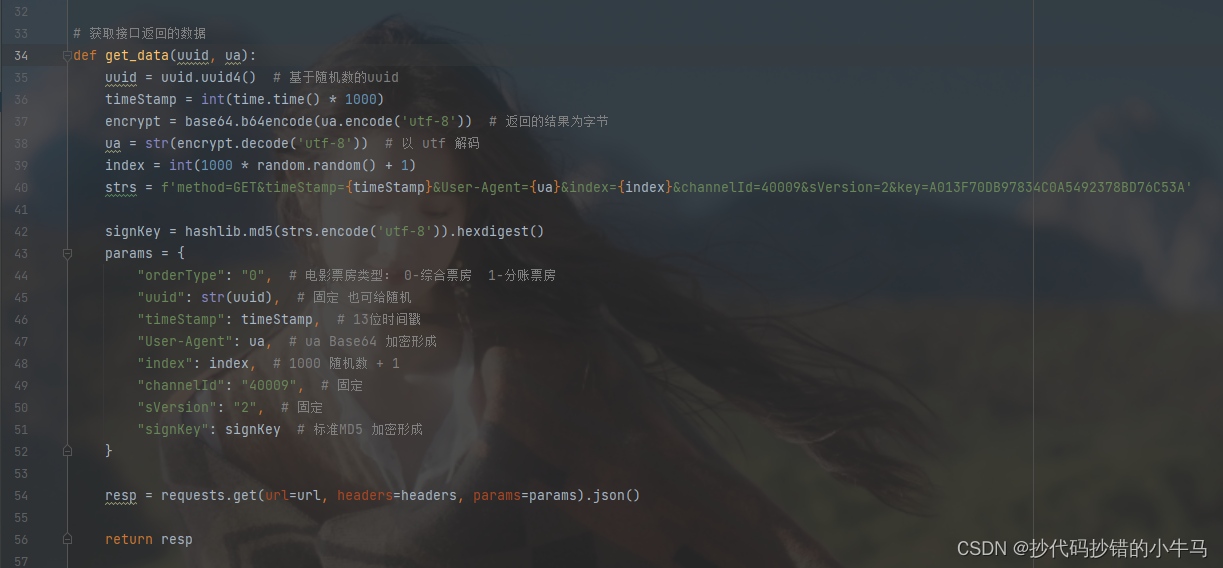
3、进行字体文件的获取下载,分析映射关系,引入 ddddocr 进行字体识别
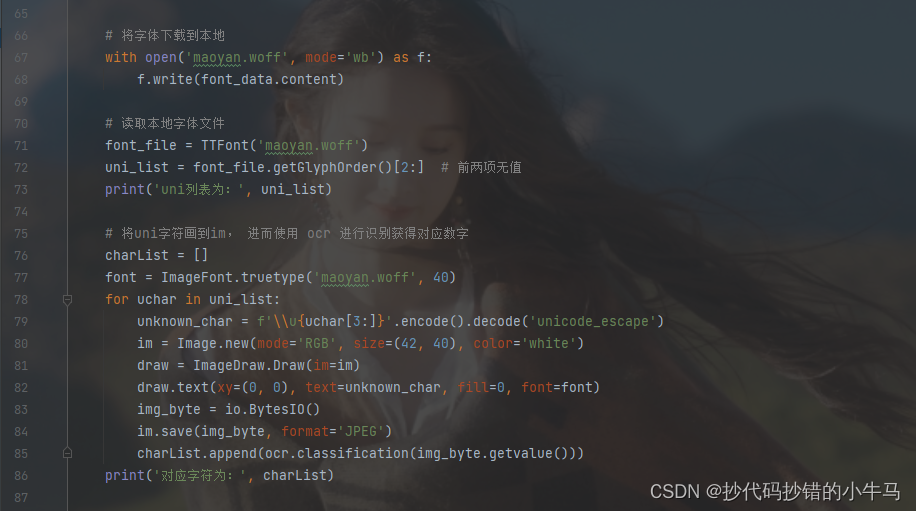
4、解析数据,循环对比替换字体

5、MySQL新建对应表,pymysql操作MySQL进行数据的存储
建表:

操作数据库:

二、代码实现
MySQL:
create table MAOYAN
(
ID int(100) AUTO_INCREMENT not null primary key,
电影id varchar(1000) null,
电影名称 varchar(1000) null,
上映天数 varchar(1000) null,
排片场次 varchar(1000) null,
票房占比 varchar(1000) null,
总票房 varchar(1000) null,
综合票房 varchar(1000) null
);
SELECT * FROM MAOYAN
drop table maoyanPython:
"""
CSDN: 抄代码抄错的小牛马
mailbox:[email protected]
"""
import base64
import hashlib
import random
import re
import io
import ddddocr
import pymysql
import requests
import time
import uuid
from userAgentPooL import userAgent
from fontTools.ttLib import TTFont
from PIL import ImageFont, Image, ImageDraw
ua = userAgent.get_ua()
ocr = ddddocr.DdddOcr()
url = 'https://piaofang.maoyan.com/dashboard-ajax'
headers = {
"Accept": "application/json, text/plain, */*",
"Referer": "https://piaofang.maoyan.com/dashboard",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35",
}
# 获取接口返回的数据
def get_data(uuid, ua):
uuid = uuid.uuid4() # 基于随机数的uuid
timeStamp = int(time.time() * 1000)
encrypt = base64.b64encode(ua.encode('utf-8')) # 返回的结果为字节
ua = str(encrypt.decode('utf-8')) # 以 utf 解码
index = int(1000 * random.random() + 1)
strs = f'method=GET&timeStamp={timeStamp}&User-Agent={ua}&index={index}&channelId=40009&sVersion=2&key=A013F70DB97834C0A5492378BD76C53A'
signKey = hashlib.md5(strs.encode('utf-8')).hexdigest()
params = {
"orderType": "0", # 电影票房类型: 0-综合票房 1-分账票房
"uuid": str(uuid), # 固定 也可给随机
"timeStamp": timeStamp, # 13位时间戳
"User-Agent": ua, # ua Base64 加密形成
"index": index, # 1000 随机数 + 1
"channelId": "40009", # 固定
"sVersion": "2", # 固定
"signKey": signKey # 标准MD5 加密形成
}
resp = requests.get(url=url, headers=headers, params=params).json()
return resp
# 处理拿到的数据
def process(resp, connect):
font_json = resp['fontStyle']
fonturl = 'http:' + re.search('opentype"\),url\("(//.*?\.woff)"', font_json).group(1)
print('字体下载链接为:', fonturl)
font_data = requests.get(fonturl)
# 将字体下载到本地
with open('maoyan.woff', mode='wb') as f:
f.write(font_data.content)
# 读取本地字体文件
font_file = TTFont('maoyan.woff')
uni_list = font_file.getGlyphOrder()[2:] # 前两项无值
print('uni列表为:', uni_list)
# 将uni字符画到im, 进而使用 ocr 进行识别获得对应数字
charList = []
font = ImageFont.truetype('maoyan.woff', 40)
for uchar in uni_list:
unknown_char = f'\\u{uchar[3:]}'.encode().decode('unicode_escape')
im = Image.new(mode='RGB', size=(42, 40), color='white')
draw = ImageDraw.Draw(im=im)
draw.text(xy=(0, 0), text=unknown_char, fill=0, font=font)
img_byte = io.BytesIO()
im.save(img_byte, format='JPEG')
charList.append(ocr.classification(img_byte.getvalue()))
print('对应字符为:', charList)
# 解析数据 循环替换
movieList = resp['movieList']['data']['list']
movieName = [i['movieInfo']['movieName'] for i in movieList] # 电影名称
movieId = [i['movieInfo']['movieId'] for i in movieList] # 电影id
releaseInfo = [i['movieInfo']['releaseInfo'] for i in movieList] # 上映天数
showCount = [i['showCount'] for i in movieList] # 排片场次
boxRate = [i['boxRate'] for i in movieList] # 票房占比
sumBoxDesc = [i['sumBoxDesc'] for i in movieList] # 总票房
boxSplitUnit = [i['boxSplitUnit']['num'] for i in movieList] # 要替换的 综合票房
# 循环对比 替换 字符
for item in range(len(boxSplitUnit)):
# for item in range(1):
end_num = ''
uni_strs = boxSplitUnit[item].split(';')
for a in uni_strs:
if a == '':
continue
end_uni = 'uni' + a.replace('&#x', '').replace('.', '').upper() # 替换并将小写转为大写
for b in range(len(uni_list)):
if end_uni == uni_list[b]:
if '.' in a:
end_num += '.' + charList[b]
else:
end_num += charList[b]
# print('综合票房:', end_num)
end_data = f'电影名称:{movieName[item]} 电影id:{movieId[item]} 上映天数:{releaseInfo[item]} 排片场次:{showCount[item]} 票房占比:{boxRate[item]} 总票房:{sumBoxDesc[item]} 综合票房:{end_num}万'
print(end_data)
value = (movieId[item],
movieName[item], releaseInfo[item], showCount[item], boxRate[item], sumBoxDesc[item],
end_num + '万')
save_data(connect=connect, value=value)
pass
# 连接数据库
def connect():
db = pymysql.connect(host='127.0.0.1', # 服务器名或本地IP
user='root', # 账户
这里是密码英文单词='******', # 自己设置的密码
database='yxhdatabase') # 你要连接的数据库名
if db:
print("恭喜你,连接成功 !!!")
return db
# 操作数据库
def save_data(connect, value):
cur = connect.cursor() # 创建游标对象
sql = 'insert into maoyan(电影id, 电影名称, 上映天数, 排片场次, 票房占比, 总票房, 综合票房) values(%s, %s, %s, %s, %s, %s, %s)' # 创建sql语句
cur.execute(sql, value) # 执行sql语句
connect.commit() # 提交
cur.close() # 关闭游标
return cur
if __name__ == '__main__':
connect = connect()
resp = get_data(uuid, ua)
process(resp, connect)
print('===============数据已写入MySQL,请检查!!!========================')
connect.close() # 关闭连接
三、效果展示