因为各个国家自己弄自己的编码,导致A语言的编码文件,放到B语言环境下,就会乱码,所以国际上弄了一个Unicode,类似一般等价物,所有语言的编码都能找到对应的Unicode编码,如果不想麻烦,在以后的编程里面,统一用Unicode编码,不然就得转码
所以在程序的开头,都是这个
开头的声明
#_*_coding:uft-8_*_
表示你的程序是用utf-8编码写的,读的时候也要按照这个来读
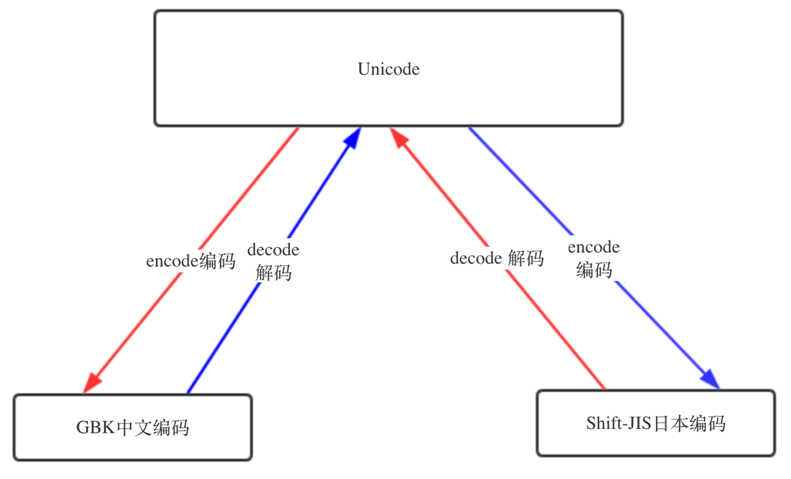
字符编码的转换
常用编码介绍一览表
| 编码 |
制定时间 |
作用 |
所占字节数 |
| ASCII |
1967年 |
表示英语及西欧语言 |
8bit/1bytes |
| GB2312 |
1980年 |
国家简体中文字符集,兼容ASCII |
2bytes |
| Unicode |
1991年 |
国际标准组织统一标准字符集 |
2bytes |
| GBK |
1995年 |
GB2312的扩展字符集,支持繁体字,兼容GB2312 |
2bytes |
| UTF-8 |
1992年 |
不定长编码 |
1-3bytes |
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节
PY3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦
想在py3里看字符,必须得是unicode编码,其它编码一律按bytes格式展示
常见编码错误的原因有:
- Python解释器的默认编码
- Python源文件文件编码
- Terminal使用的编码
- 操作系统的语言设置
掌握了编码之间的关系后,挨个排错就好啦