随着互联网的快速发展,HTTP代理爬虫已成为数据采集的重要工具。然而,随之而来的是恶意爬虫对网络安全和数据隐私的威胁。为了更好地保护网络环境和用户数据,我们进行了基于机器学习的HTTP代理爬虫识别与防御的研究。以增强对HTTP代理爬虫的识别和防御能力。
这项研究的核心是将机器学习应用于HTTP代理爬虫的识别与防御。传统的规则方法已经难以应对日益复杂和变化多样的恶意爬虫。而机器学习作为一种智能化方法,通过对大量数据进行学习和分析,能够自主识别和阻止代理爬虫。
首先,针对HTTP代理爬虫的识别,我们进行了以下研究:
1. 特征工程:从代理请求中提取关键特征,如请求频率、请求头、请求路径等。经过预处理和特征选择,提高机器学习算法的准确性和鲁棒性。
2. 模型选择与训练:基于收集到的正常和代理爬虫请求数据,选择适合的机器学习模型进行训练和优化。常用的模型有决策树、支持向量机等。
3. 异常检测与识别:利用机器学习算法构建模型进行代理爬虫请求的分类判断,将正常请求与恶意代理爬虫进行区分。
其次,针对代理爬虫的防御,我们进行了以下研究:
1. 动态防御策略:利用机器学习领域的增量学习和持续优化方法,实现对代理爬虫攻击的实时监测和防御。及时更新防御策略,阻止代理爬虫的入侵。
2. 威胁情报分析:通过机器学习算法分析和整合全球的威胁情报数据,及时发现新的代理爬虫攻击手段,提前采取相应的防御措施。
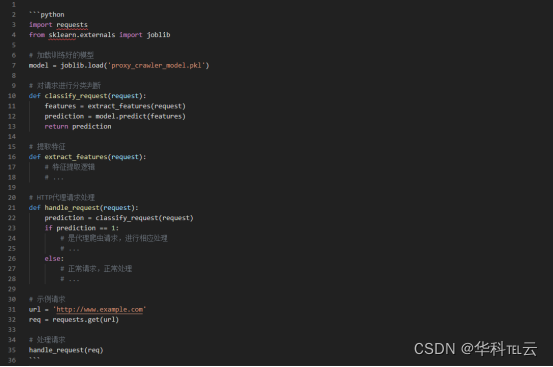
下面是一个简单的Python代码示例,演示基于机器学习的HTTP代理爬虫识别:
如果您对我们的研究和解决方案感兴趣,欢迎评论区留言,共同商讨更优解