第一部分:
1、chatGPT:一个大语言模型,可以通过API去访问,下面很多是根据API去访问,然后来进行集成。
2、Vector store,你也可以叫是Vector search,主要目就是存储各种向量,然后去计算向量的各种相似度。主要是为了辨别不同的自然语言的语义,他们之间的相近性什么,其实主要也是那个GPG底层的这个embing,是一个数据结构的一个存储。
3、LangChain 简单理解类似于Java领域里那个spring,或者是说 ruby 生态里边那个Rails,其实它就是一个python的一个框架,但它主要是服务于LLM这个领域,也就是大原模型这个领域,它对这些整体的这个生态进行了一个抽象,所以它是一个Python的一个大语言模型的开发框架,当然它现在也提供JS的,你会发现后面很多应用其实都是通过它来作为类似于一个胶水,或者是一个生产线,然后把所有的这种组件啊,生态里的这些东西。就是集成到一起或者粘到一起.
现在社区也提供了很多这种,local 运行方案,类似于节点跟节点之间进行连接的这种拖拽,构建这样一个local 的一个应用啊,这是两个比较常见的,大家可以参考一下
Low/no-code Langchain
-
Flowise - https:/ /github.com/FlowiseAl/Flowise
-
Langflow - https://github.com/logspace-ai/langflow
第二部分:
1、BabyAG 来源于一篇文章《 Task-driven Autonomous Agent》,Agent就是任务驱动的自动,就是你会有不同的一些agent,然后去完成不同的任务,你只要给这些agent发一个任务,或者发目标之后他们会自己进行一些协调,以及借助于chatGPT以及存储的这些能力,然后进行任务的分解,分发,执行调度这样一些东西,BabyAgi其实就是类似于这样一套架构的一个实现,就是它是一个Python的那个脚本,它其实其实就是一个程序。

按那程序的结构如下,这个结构比较经典,新的gpt的一些应用,其实都是类似的结构。

2、HuggingGPT是那个微软然后发布的,它的结构如下,你通过它去发指令给这LLM,其实就是给chatGPT发一个类似于自然语言一个指令,然后这些自然语言那个chatGPT就会进行分解,然后去HugginGPT那边去找相应的这种合适的model,然后去执行model,然后各种返回的响应,其实跟 Baby AGI那个架构是类似的,本质上来讲就是通过chatGPT作为一个接口,然后进行任务的解析,分发这样一些任务,所以你会发现其实chatGPT在整个的这些架构里面都是。
包括这里面,其实你它更详细的就是说明了,说这个Huggin face、hugging GPT 的结构,主要是分四步,第一步什么就是任务的规划,然后再进行模型的选择,然后之后呢,就是执行任务,然后最后再把结果返回给这个chatGPT去生成啊相应的这个响应对吧,所以嗯,架构的这个流程上是很简单,但其实你会发现跟BabyAgi那整个的那个这个这架构愿景其实很相像。


3、Jarvis 说白了它是属于HuggingGPT的一个实现啊,你可以这样这样来理解,就是HuggingGPT是一个paper,就是一个论文,最终的工程实现其实是由Jarvis来实现的。
4、AutoGPT 的结构跟前面的HuggingGPT以及BabyAGI其实类似的,都是做的一个事情,本质上来讲,他们都是在做任务的这种分发,基于任务的这样一些agent,样一些东西,所以结构上我就不分析了,其实都类似。
5、AgentGPT 重点介绍一下这个东西,agentgpt属于AutoGPT的一个web应用,所以你可以直接在web上去用那个AutoGPT,否则的话你就要去自己去安装那个AutoGPT,然后去用Python去run,然后去又要去怎么去配置这个,Python的API又要去。配置这个chatGPT的这个open API的key对吧,所以那个那个东西就是比较脚本化,面向开发人员的这样一个一个界面,反而是说啊Agentgpt呢,就直接是一个web页面,然后你就普通用户,普通小白用户,没有什么经验的用户就可以直接用,所以这个产品就相当于是Autogpt一个升级版。
在前面三种三类产品,其实它属于不同出处嘛,对吧,但其实啊,理念都是类似的,都是基于task drive的这样一些agent的。
generative agents
斯坦福大学出了一个论文,就是让这几十个这种agent的,就是这机器人这样一个东西,放在一个模拟环境里面去跑,然后他们自己会形成一个这种各种社交啦,谈话的这样一些东西,然后就形成一个自主的一个生态,然后这个这里面每一个agent其实就是就是类似于叫真的那个agent,为什么呢?就是它可以自发的做出一些。
决策响应这样一些东西,电影西部世界里边那样,就是每一个机器人,它其实相当于有了一些自主的一个意识,所以啊,这就是相当于在原来的AutoGPT,或者是啊babyAGI这样一些一些理念跟加构的基础上形成了一个生态,所以这是比较有意思的一个点,为什么如果真的照这个发展下去,是不是就是将来机器人或者什么人工智能会形成他自己的一个生态。所以这个是比较值得关注的一个一个东西,但将来会怎么演化。
你发现不同的agent,就相当于是在自主的给做出行为,然后碰到不同的人有不同的这种响应。
GPT4All(gpt for All Not gpt4 all)
就是本地安装了一套单元模型的一套方案。
chatGLM 这个这个模型就是清华大学出的这套模。
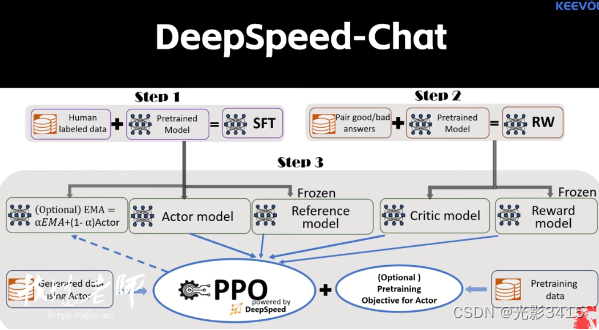
Deepspeed (LMM)这是微软出的一个内库,就是深度学习一个内库,然后很多方案都构建,看它上面,然后在它上面构建了一个东西叫deep speed chat是两个东西,所以要把它放在一起来进行澄清,然后deep speed chat就是一套方案,说白了它就是它模仿chatgpt的那套东西,其实完成了这种架构啦,完成的这种目的啊,都是类似的,就是他能让你去自己训练一套类似于chatGPT这样一套产品的一个架构体系,那也是分三步走,第一步就是监督式的进行学习,然后之后再加上reward的reward model,就是讲义式的这样一些一些模型训练,然后最终再通过这种,人工的这种干预就是专业术语提要,Reinforcement learning啊,With human feedback。
最后介绍一个东西,就是就是刚出来就是web LLM啊,它最主要的一个特点是可以让你在浏览器里面去跑大语言模型。
它的架构是这样的,就是可能很复杂,但是简单来讲就是这样,就是它是通过在开发期间去构建一个大语言模型,然后再运行的时候,通过浏览器配合WSM这个技术,就是去实现模型的这个加载,然后直接再在模型里面去跑啊,在浏览器里面去跑,因为浏览器现在,CHROME113那个版本已经支持了那个web GPU对吧,所以它也可以让这些大的模型,然后在这个浏览器里面去去使用到本机的这个GPU的这个资源,所以这套方案是现在是可行的,但是最主要是说现在还是处于better阶段,就是因为为什么,就是你在加载的时候,它还是会下载机随机的模型到本地去进行缓存,所以其实来对于这个本地的机器性能不是太好的这种用户来讲,其实也没有那么友好,但是它其实已经出现了像web2.0时代这种BS架构这样一个特点,所以让我们拭目以待吧。