1.前言
现在有一组数据对,其中有些数据是成对的,但现在对我而言它们都属于相同元素,比如(21, 5)和(5, 21)是一回事,现需要去除重复对。
2.正文
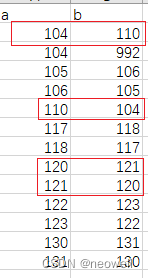
我的测试数据如下 mirrorNode.csv :
实现代码如下:
#remove_mirror_pair.py
import csv
import os
import argparse
from tqdm import tqdm
def remove_mirror_pair(file_csv):
assert os.path.exists(file_csv), "File not exists, check your address again."
#Step-0:获取读取到的表的总长度(包含表头)
with open(file_csv, 'r', encoding='utf-8-sig') as f:
total_length=len(list(csv.reader(f, skipinitialspace=True)))
#Step-1: 处理读取到的csv中的信息
a=[]
#读取重复节点csv表
with open(file_csv, encoding='utf-8-sig') as f:
csvfile=csv.reader(f, skipinitialspace=True)
#去除表头
next(csvfile,None)
total_length-=1
for row in tqdm(csvfile, desc='读取所有节点对',total=total_length):
#将列表中的每个元素从str强制转化为int型,注意row也是一个列表对,比如['1000','1001'],
# 所以此处使用map()函数,将列表里的每个元素都进行类型转化;
a.append(map(int, row))
#对a中的元素进行升/降序的统一处理,这样镜像节点的数值就会被统一,从而变成列表内重复的数据
sorted_a= map(sorted, a)
#set集合具有元素不重复的特点,利用这一点来达到筛选重复元素的目的
a_no_mirror=set()
for pair in sorted_a:
a_no_mirror.add(tuple(pair))#将每一对节点从list强制转换为tuple型,以进行添加操作;
#Step-2: 将筛选后的列表导出到新的csv文件中
original_filename=os.path.basename(file_csv)
export_filename='filtered-'+original_filename
original_address=os.path.abspath(file_csv)
export_address=os.path.dirname(original_address)
final_export_place=os.path.join(export_address, export_filename)
#以下这种写法会自动生成文件,以及会强制覆盖原同名文件,需注意;
#下文的writerow()方法会自动在行尾添加换行符,所以此处添加newline=''以免多余换行
with open(final_export_place, 'w', newline='') as csvfile:
#添加dialect='excel'参数来为输出的文件添加csv兼容性
info_writer=csv.writer(csvfile, dialect='excel')
#添加表头
info_writer.writerow(['X', 'Y'])
#添加所有信息
for node_pair in tqdm(a_no_mirror, desc='筛选重复元素'):
info_writer.writerow(node_pair)
print('\n|⬇--Output File Saved Below--⬇|\n\n{place}\n'.format(place=final_export_place))
print('|--All Done--|')
if __name__=='__main__':
parse=argparse.ArgumentParser()
parse.add_argument('--input', '-i', type=str, default='', help='设定输入CSV文件的位置')
arg=parse.parse_args()
remove_mirror_pair(arg.input)执行代码:
(neowell) C:\CSBLOG>python remove_mirror_pair.py --input ./mirrorNode.csv
读取所有节点对: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:00<?, ?it/s]
筛选重复元素: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:00<?, ?it/s]
|⬇--Output File Saved Below--⬇|
C:\CSBLOG\filtered-mirrorNode.csv
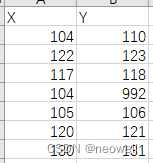
|--All Done--|生成的filtered-mirrorNode.csv结果如下图:
3. 其它
- mirrorNode.csv的数据:
| a | b |
| 104 | 110 |
| 104 | 992 |
| 105 | 106 |
| 106 | 105 |
| 110 | 104 |
| 117 | 118 |
| 118 | 117 |
| 120 | 121 |
| 121 | 120 |
| 122 | 123 |
| 123 | 122 |
| 130 | 131 |
| 131 | 130 |
- 参考: