# Load data
data("USArrests")
my_data <- USArrests
# Remove any missing value (i.e, NA values for not available)
my_data <- na.omit(my_data)
# Scale variables
my_data <- scale(my_data)
# View the firt 3 rows
head(my_data, n = 3)
set.seed(123)
km.res <- kmeans(my_data, 3, nstart = 25)
# Visualize
library("factoextra")
fviz_cluster(km.res, data = my_data,
ellipse.type = "convex",
palette = "jco",
repel = TRUE,
ggtheme = theme_minimal())+scale_fill_brewer(palette = "Blues")
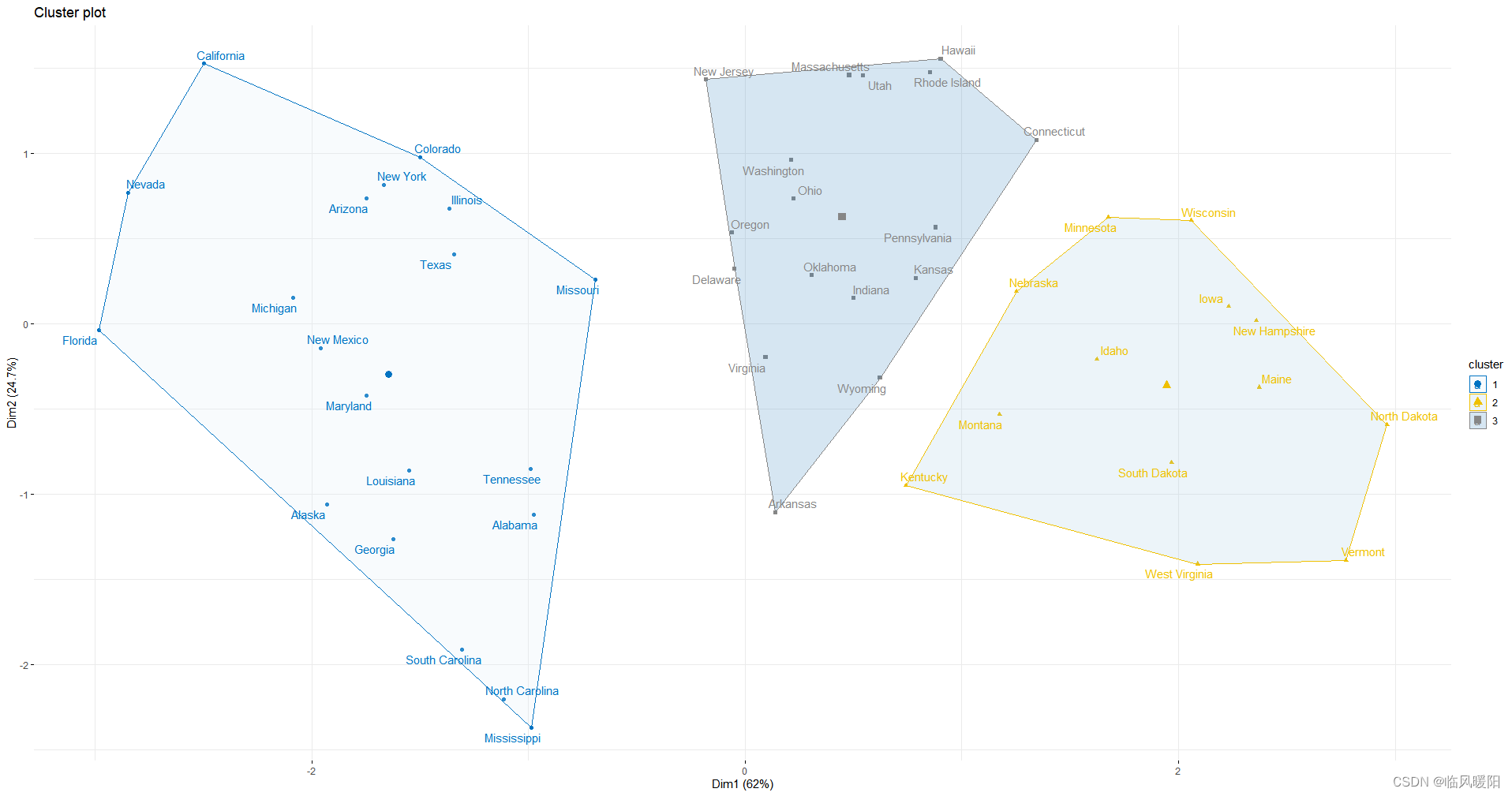
scale_fill_brewer(palette = "Set1")
# Load data
data("USArrests")
my_data <- USArrests
# Remove any missing value (i.e, NA values for not available)
my_data <- na.omit(my_data)
# Scale variables
my_data <- scale(my_data)
# View the firt 3 rows
head(my_data, n = 5)
set.seed(123)
km.res <- kmeans(my_data, 5, nstart = 54)
# Visualize
library("factoextra")
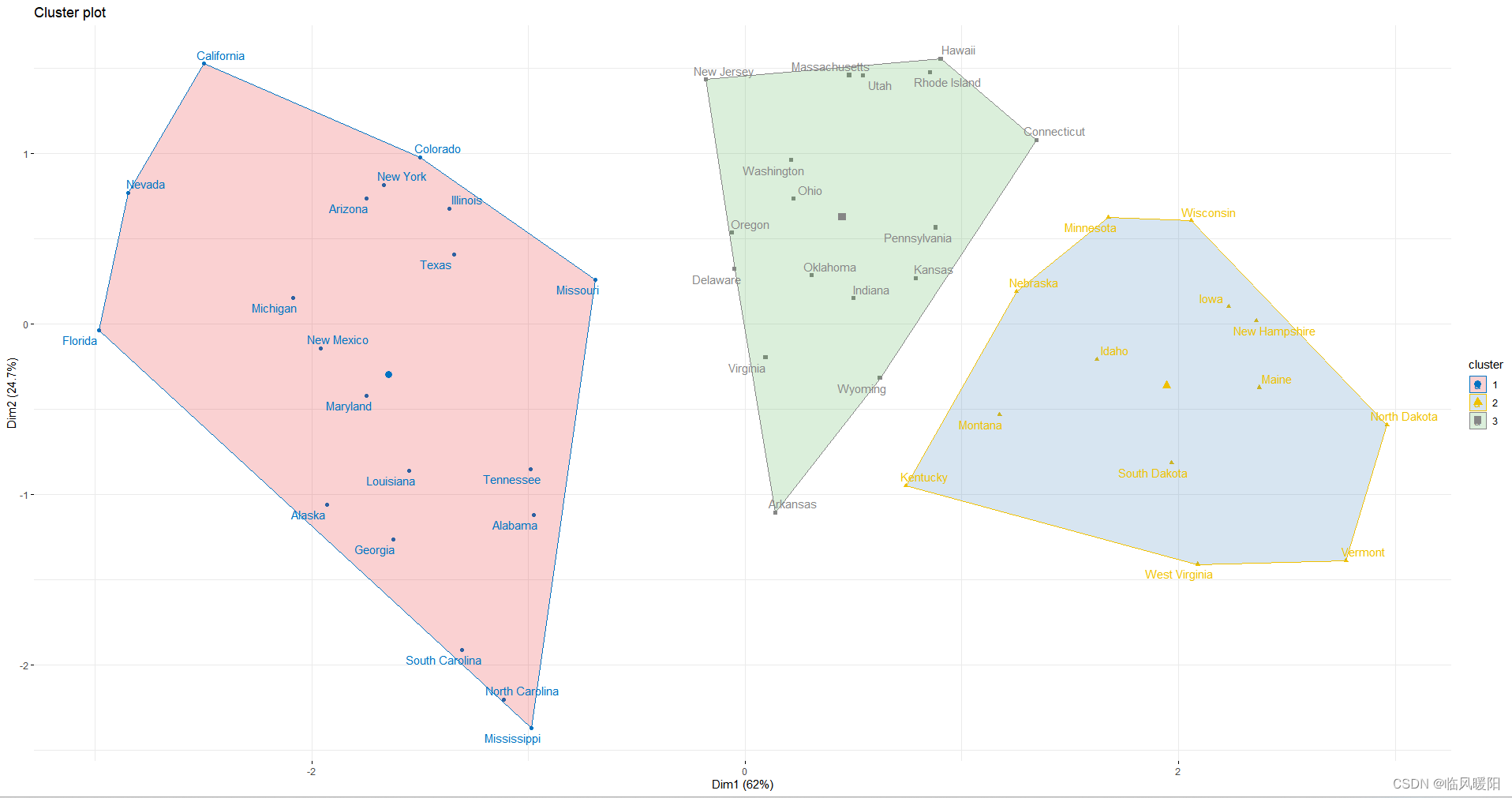
fviz_cluster(km.res, data = my_data,
ellipse.type = "convex",
palette = "jco",
repel = TRUE,
ggtheme = theme_minimal())+scale_fill_brewer(palette = "Set1")
head(my_data, n = 10)
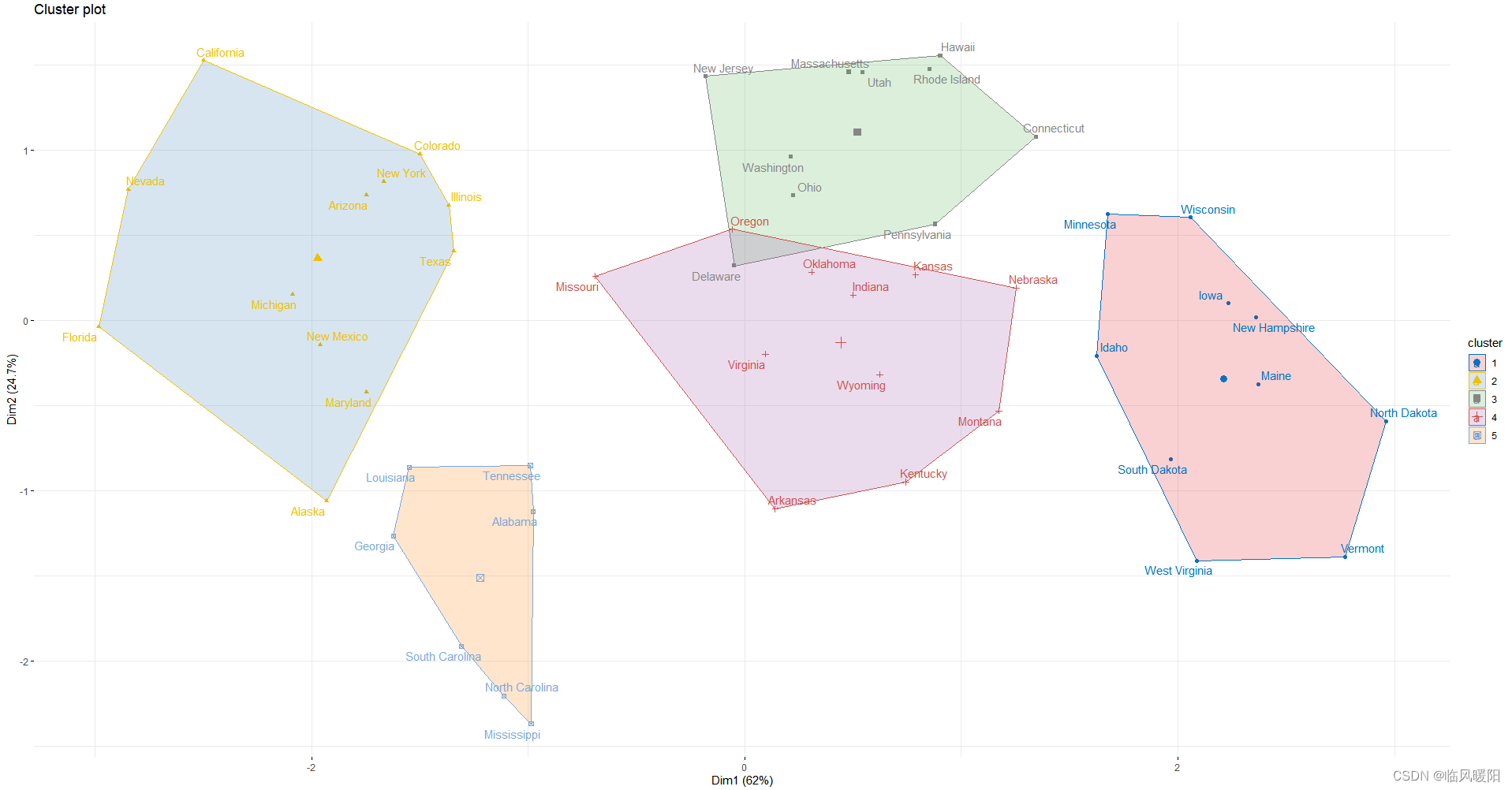
set.seed(123)
km.res <- kmeans(my_data, 10, nstart = 54)
# Visualize
library("factoextra")
fviz_cluster(km.res, data = my_data,
ellipse.type = "convex",
palette = "jco",
repel = TRUE,
ggtheme = theme_minimal())+scale_fill_brewer(palette = "Set2")
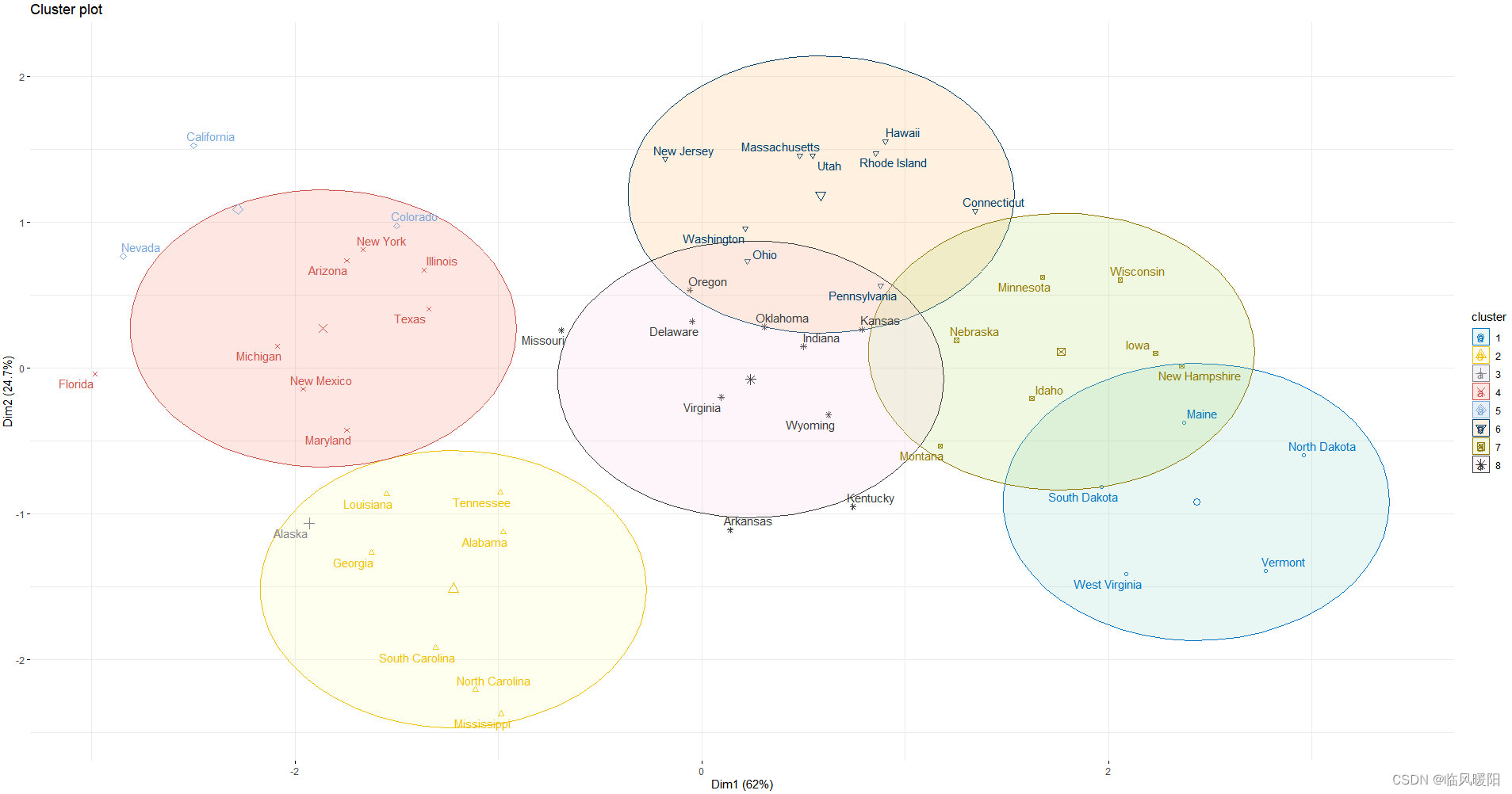
# View the firt 8 rows
head(my_data, n = 8)
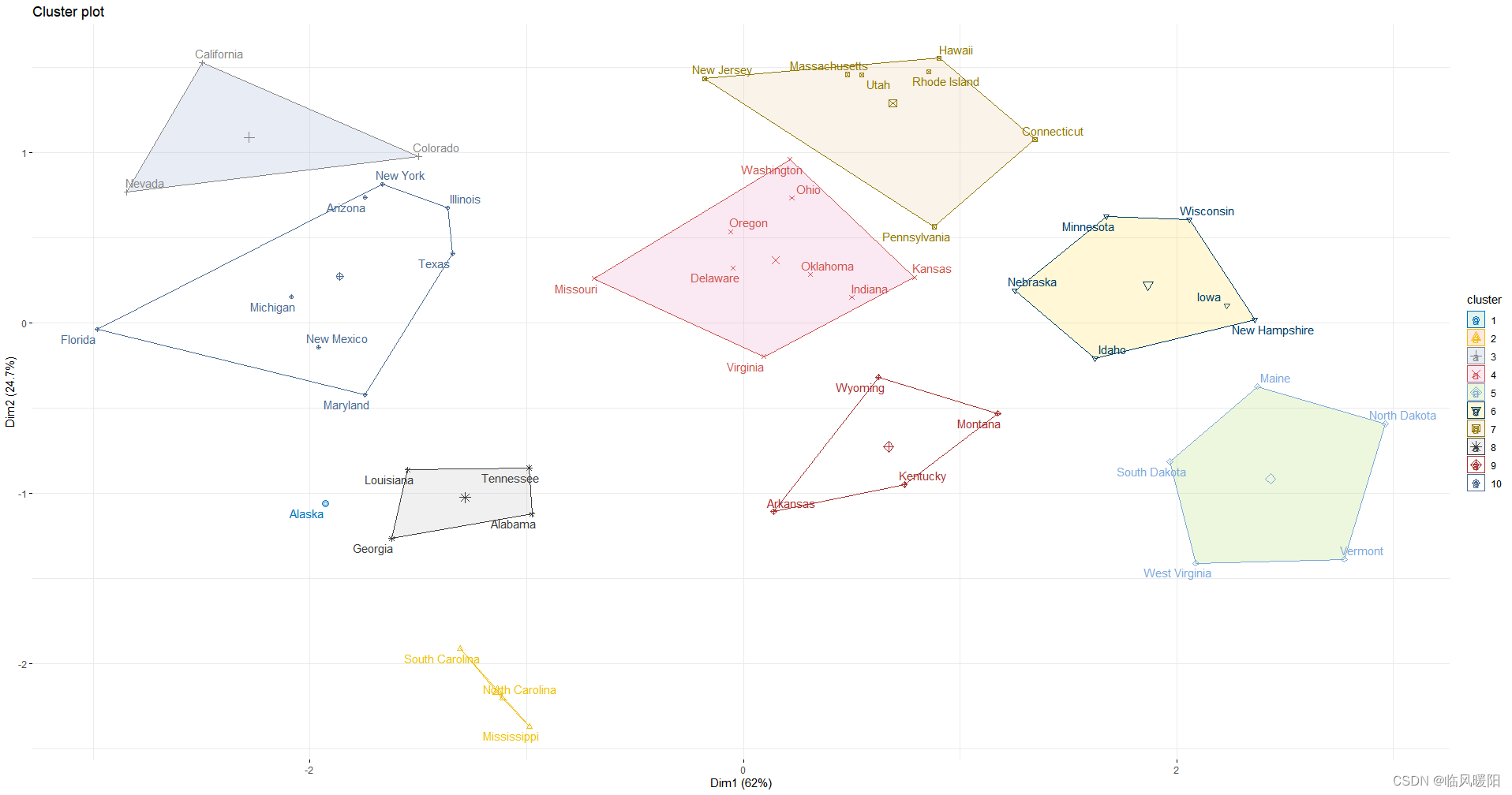
set.seed(123)
km.res <- kmeans(my_data, 8, nstart = 54)
# Visualize
library("factoextra")
fviz_cluster(km.res, data = my_data,
ellipse.type = "convex",
palette = "jco",
repel = TRUE,
ggtheme = theme_minimal())+scale_fill_brewer(palette = "Set3")
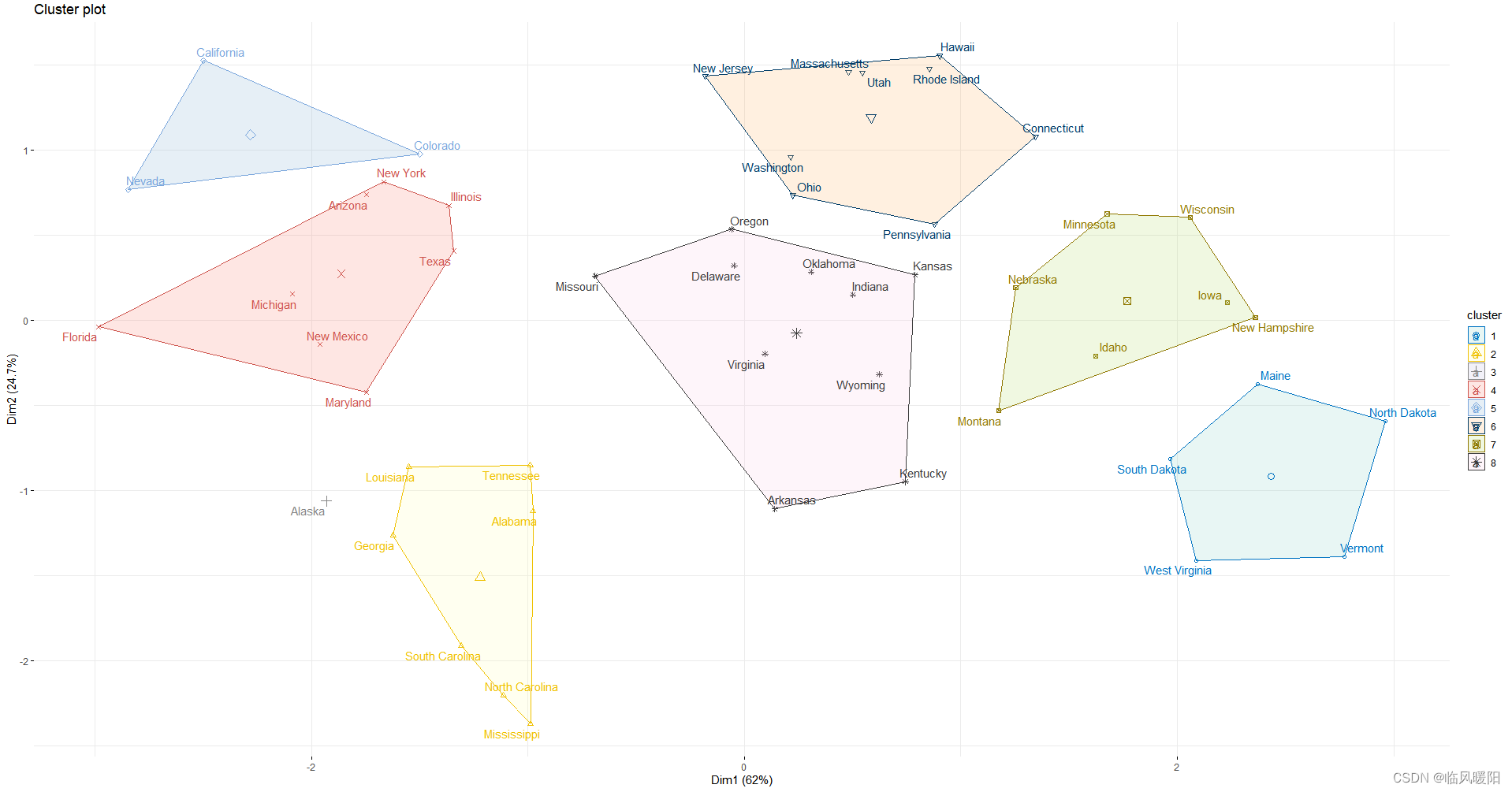
fviz_cluster(km.res, data = my_data,
ellipse.type = "t",
palette = "jco",
repel = TRUE,
ggtheme = theme_minimal())+scale_fill_brewer(palette = "Set3")
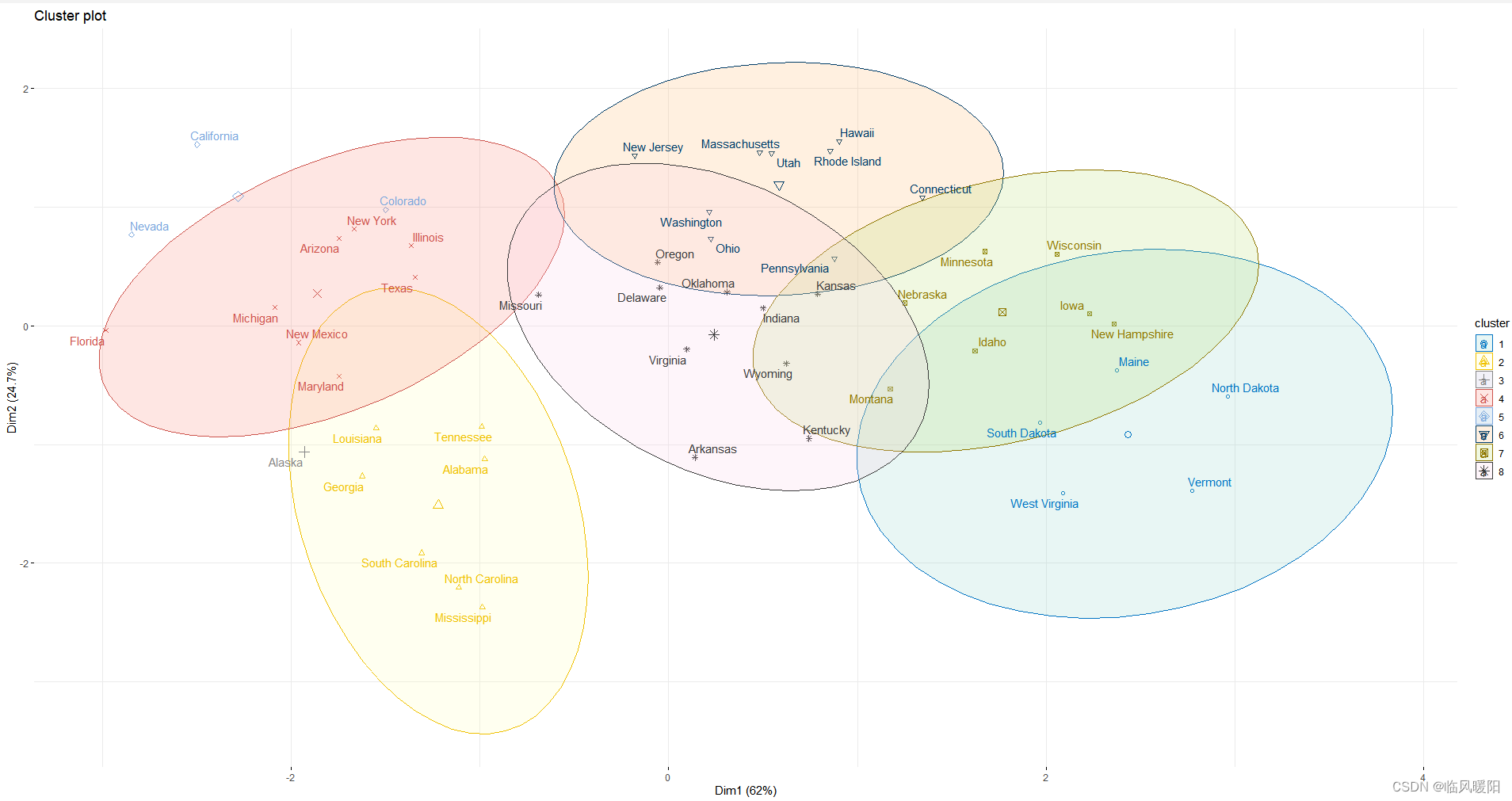
fviz_cluster(km.res, data = my_data,
ellipse.type = "euclid",
palette = "jco",
repel = TRUE,
ggtheme = theme_minimal())+scale_fill_brewer(palette = "Set3")
参考文献:https://www.datanovia.com/en/courses/partitional-clustering-in-r-the-essentials/